 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-Based Beliefs for POMDPs with Visual Observations
Feb 05, 2026Partially observable Markov decision processes (POMDPs) are a principled planning model for sequential decision-making under uncertainty. Yet, real-world problems with high-dimensional observations, such as camera images, remain intractable for traditional belief- and filtering-based solvers. To tackle this problem, we introduce the Perception-based Beliefs for POMDPs framework (PBP), which complements such solvers with a perception model. This model takes the form of an image classifier which maps visual observations to probability distributions over states. PBP incorporates these distributions directly into belief updates, so the underlying solver does not need to reason explicitly over high-dimensional observation spaces. We show that the belief update of PBP coincides with the standard belief update if the image classifier is exact. Moreover, to handle classifier imprecision, we incorporate uncertainty quantification and introduce two methods to adjust the belief update accordingly. We implement PBP using two traditional POMDP solvers and empirically show that (1) it outperforms existing end-to-end deep RL methods and (2) uncertainty quantification improves robustness of PBP against visual corruption.
Tighter Value-Function Approximations for POMDPs
Feb 10, 2025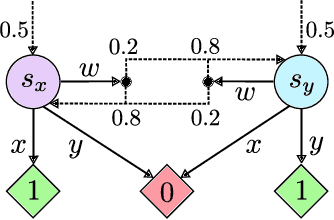

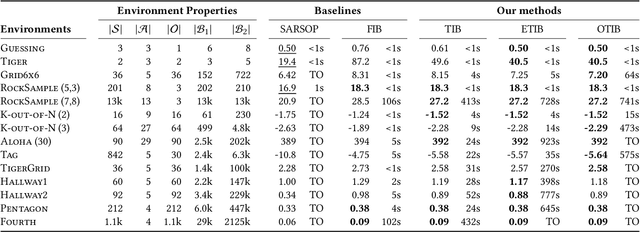
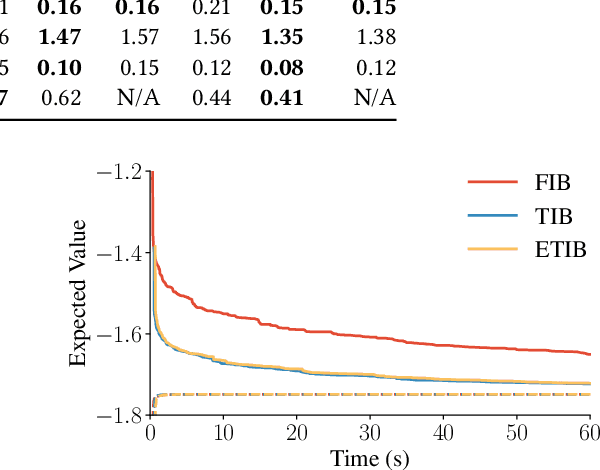
Solving partially observable Markov decision processes (POMDPs) typically requires reasoning about the values of exponentially many state beliefs. Towards practical performance, state-of-the-art solvers use value bounds to guide this reasoning. However, sound upper value bounds are often computationally expensive to compute, and there is a tradeoff between the tightness of such bounds and their computational cost. This paper introduces new and provably tighter upper value bounds than the commonly used fast informed bound. Our empirical evaluation shows that, despite their additional computational overhead, the new upper bounds accelerate state-of-the-art POMDP solvers on a wide range of benchmarks.
Robust Active Measuring under Model Uncertainty
Dec 18, 2023



Partial observability and uncertainty are common problems in sequential decision-making that particularly impede the use of formal models such as Markov decision processes (MDPs). However, in practice, agents may be able to employ costly sensors to measure their environment and resolve partial observability by gathering information. Moreover, imprecise transition functions can capture model uncertainty. We combine these concepts and extend MDPs to robust active-measuring MDPs (RAM-MDPs). We present an active-measure heuristic to solve RAM-MDPs efficiently and show that model uncertainty can, counterintuitively, let agents take fewer measurements. We propose a method to counteract this behavior while only incurring a bounded additional cost. We empirically compare our methods to several baselines and show their superior scalability and performance.
Act-Then-Measure: Reinforcement Learning for Partially Observable Environments with Active Measuring
Mar 14, 2023



We study Markov decision processes (MDPs), where agents have direct control over when and how they gather information, as formalized by action-contingent noiselessly observable MDPs (ACNO-MPDs). In these models, actions consist of two components: a control action that affects the environment, and a measurement action that affects what the agent can observe. To solve ACNO-MDPs, we introduce the act-then-measure (ATM) heuristic, which assumes that we can ignore future state uncertainty when choosing control actions. We show how following this heuristic may lead to shorter policy computation times and prove a bound on the performance loss incurred by the heuristic. To decide whether or not to take a measurement action, we introduce the concept of measuring value. We develop a reinforcement learning algorithm based on the ATM heuristic, using a Dyna-Q variant adapted for partially observable domains, and showcase its superior performance compared to prior methods on a number of partially-observable environments.