 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-critical Control Under Partial Observability: Reach-Avoid POMDP meets Belief Space Control
Mar 11, 2026Partially Observable Markov Decision Processes (POMDPs) provide a principled framework for robot decision-making under uncertainty. Solving reach-avoid POMDPs, however, requires coordinating three distinct behaviors: goal reaching, safety, and active information gathering to reduce uncertainty. Existing online POMDP solvers attempt to address all three within a single belief tree search, but this unified approach struggles with the conflicting time scales inherent to these objectives. We propose a layered, certificate-based control architecture that operates directly in belief space, decoupling goal reaching, information gathering, and safety into modular components. We introduce Belief Control Lyapunov Functions (BCLFs) that formalize information gathering as a Lyapunov convergence problem in belief space, and show how they can be learned via reinforcement learning. For safety, we develop Belief Control Barrier Functions (BCBFs) that leverage conformal prediction to provide probabilistic safety guarantees over finite horizons. The resulting control synthesis reduces to lightweight quadratic programs solvable in real time, even for non-Gaussian belief representations with dimension $>10^4$. Experiments in simulation and on a space-robotics platform demonstrate real-time performance and improved safety and task success compared to state-of-the-art constrained POMDP solvers.
Validation of Space Robotics in Underwater Environments via Disturbance Robustness Equivalency
Feb 28, 2026We present an experimental validation framework for space robotics that leverages underwater environments to approximate microgravity dynamics. While neutral buoyancy conditions make underwater robotics an excellent platform for space robotics validation, there are still dynamical and environmental differences that need to be overcome. Given a high-level space mission specification, expressed in terms of a Signal Temporal Logic specification, we overcome these differences via the notion of maximal disturbance robustness of the mission. We formulate the motion planning problem such that the original space mission and the validation mission achieve the same disturbance robustness degree. The validation platform then executes its mission plan using a near-identical control strategy to the space mission where the closed-loop controller considers the spacecraft dynamics. Evaluating our validation framework relies on estimating disturbances during execution and comparing them to the disturbance robustness degree, providing practical evidence of operation in the space environment. Our evaluation features a dual-experiment setup: an underwater robot operating under near-neutral buoyancy conditions to validate the planning and control strategy of either an experimental planar spacecraft platform or a CubeSat in a high-fidelity space dynamics simulator.
Marinarium: a New Arena to Bring Maritime Robotics Closer to Shore
Feb 26, 2026This paper presents the Marinarium, a modular and stand-alone underwater research facility designed to provide a realistic testbed for maritime and space-analog robotic experimentation in a resource-efficient manner. The Marinarium combines a fully instrumented underwater and aerial operational volume, extendable via a retractable roof for real-weather conditions, a digital twin in the SMaRCSim simulator and tight integration with a space robotics laboratory. All of these result from design choices aimed at bridging simulation, laboratory validation, and field conditions. We compare the Marinarium to similar existing infrastructures and illustrate how its design enables a set of experiments in four open research areas within field robotics. First, we exploit high-fidelity dynamics data from the tank to demonstrate the potential of learning-based system identification approaches applied to underwater vehicles. We further highlight the versatility of the multi-domain operating volume via a rendezvous mission with a heterogeneous fleet of robots across underwater, surface, and air. We then illustrate how the presented digital twin can be utilized to reduce the reality gap in underwater simulation. Finally, we demonstrate the potential of underwater surrogates for spacecraft navigation validation by executing spatiotemporally identical inspection tasks on a planar space-robot emulator and a neutrally buoyant \gls{rov}. In this work, by sharing the insights obtained and rationale behind the design and construction of the Marinarium, we hope to provide the field robotics research community with a blueprint for bridging the gap between controlled and real offshore and space robotics experimentation.
Parameter-Robust MPPI for Safe Online Learning of Unknown Parameters
Jan 06, 2026Robots deployed in dynamic environments must remain safe even when key physical parameters are uncertain or change over time. We propose Parameter-Robust Model Predictive Path Integral (PRMPPI) control, a framework that integrates online parameter learning with probabilistic safety constraints. PRMPPI maintains a particle-based belief over parameters via Stein Variational Gradient Descent, evaluates safety constraints using Conformal Prediction, and optimizes both a nominal performance-driven and a safety-focused backup trajectory in parallel. This yields a controller that is cautious at first, improves performance as parameters are learned, and ensures safety throughout. Simulation and hardware experiments demonstrate higher success rates, lower tracking error, and more accurate parameter estimates than baselines.
Exact Smooth Reformulations for Trajectory Optimization Under Signal Temporal Logic Specifications
Nov 10, 2025We study motion planning under Signal Temporal Logic (STL), a useful formalism for specifying spatial-temporal requirements. We pose STL synthesis as a trajectory optimization problem leveraging the STL robustness semantics. To obtain a differentiable problem without approximation error, we introduce an exact reformulation of the max and min operators. The resulting method is exact, smooth, and sound. We validate it in numerical simulations, demonstrating its practical performance.
BURNS: Backward Underapproximate Reachability for Neural-Feedback-Loop Systems
May 06, 2025Learning-enabled planning and control algorithms are increasingly popular, but they often lack rigorous guarantees of performance or safety. We introduce an algorithm for computing underapproximate backward reachable sets of nonlinear discrete time neural feedback loops. We then use the backward reachable sets to check goal-reaching properties. Our algorithm is based on overapproximating the system dynamics function to enable computation of underapproximate backward reachable sets through solutions of mixed-integer linear programs. We rigorously analyze the soundness of our algorithm and demonstrate it on a numerical example. Our work expands the class of properties that can be verified for learning-enabled systems.
Collaborative Object Transportation in Space via Impact Interactions
Apr 25, 2025



We present a planning and control approach for collaborative transportation of objects in space by a team of robots. Object and robots in microgravity environments are not subject to friction but are instead free floating. This property is key to how we approach the transportation problem: the passive objects are controlled by impact interactions with the controlled robots. In particular, given a high-level Signal Temporal Logic (STL) specification of the transportation task, we synthesize motion plans for the robots to maximize the specification satisfaction in terms of spatial STL robustness. Given that the physical impact interactions are complex and hard to model precisely, we also present an alternative formulation maximizing the permissible uncertainty in a simplified kinematic impact model. We define the full planning and control stack required to solve the object transportation problem; an offline planner, an online replanner, and a low-level model-predictive control scheme for each of the robots. We show the method in a high-fidelity simulator for a variety of scenarios and present experimental validation of 2-robot, 1-object scenarios on a freeflyer platform.
Risk-Aware Robot Control in Dynamic Environments Using Belief Control Barrier Functions
Apr 05, 2025
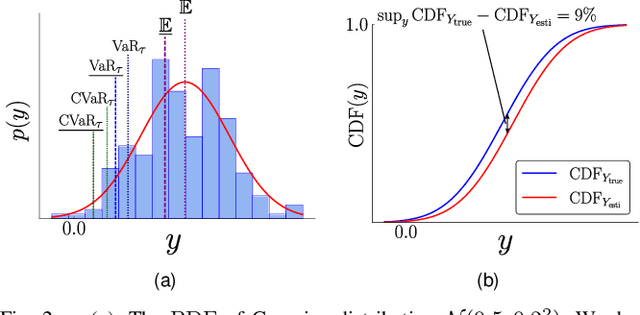
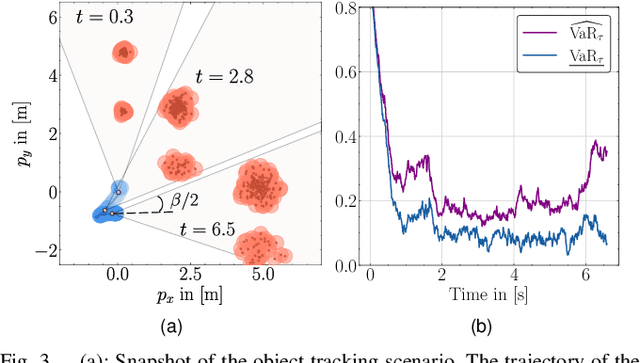
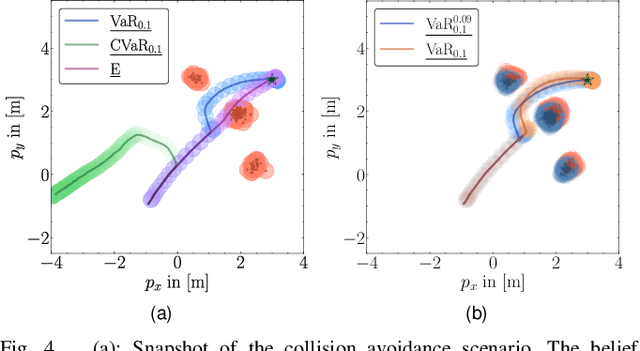
Ensuring safety for autonomous robots operating in dynamic environments can be challenging due to factors such as unmodeled dynamics, noisy sensor measurements, and partial observability. To account for these limitations, it is common to maintain a belief distribution over the true state. This belief could be a non-parametric, sample-based representation to capture uncertainty more flexibly. In this paper, we propose a novel form of Belief Control Barrier Functions (BCBFs) specifically designed to ensure safety in dynamic environments under stochastic dynamics and a sample-based belief about the environment state. Our approach incorporates provable concentration bounds on tail risk measures into BCBFs, effectively addressing possible multimodal and skewed belief distributions represented by samples. Moreover, the proposed method demonstrates robustness against distributional shifts up to a predefined bound. We validate the effectiveness and real-time performance (approximately 1kHz) of the proposed method through two simulated underwater robotic applications: object tracking and dynamic collision avoidance.
Pedestrian-Aware Motion Planning for Autonomous Driving in Complex Urban Scenarios
Apr 02, 2025



Motion planning in uncertain environments like complex urban areas is a key challenge for autonomous vehicles (AVs). The aim of our research is to investigate how AVs can navigate crowded, unpredictable scenarios with multiple pedestrians while maintaining a safe and efficient vehicle behavior. So far, most research has concentrated on static or deterministic traffic participant behavior. This paper introduces a novel algorithm for motion planning in crowded spaces by combining social force principles for simulating realistic pedestrian behavior with a risk-aware motion planner. We evaluate this new algorithm in a 2D simulation environment to rigorously assess AV-pedestrian interactions, demonstrating that our algorithm enables safe, efficient, and adaptive motion planning, particularly in highly crowded urban environments - a first in achieving this level of performance. This study has not taken into consideration real-time constraints and has been shown only in simulation so far. Further studies are needed to investigate the novel algorithm in a complete software stack for AVs on real cars to investigate the entire perception, planning and control pipeline in crowded scenarios. We release the code developed in this research as an open-source resource for further studies and development. It can be accessed at the following link: https://github.com/TUM-AVS/PedestrianAwareMotionPlanning
Towards Open-Source and Modular Space Systems with ATMOS
Jan 28, 2025



In the near future, autonomous space systems will compose a large number of the spacecraft being deployed. Their tasks will involve autonomous rendezvous and proximity operations with large structures, such as inspections or assembly of orbiting space stations and maintenance and human-assistance tasks over shared workspaces. To promote replicable and reliable scientific results for autonomous control of spacecraft, we present the design of a space systems laboratory based on open-source and modular software and hardware. The simulation software provides a software-in-the-loop (SITL) architecture that seamlessly transfers simulated results to the ATMOS platforms, developed for testing of multi-agent autonomy schemes for microgravity. The manuscript presents the KTH space systems laboratory facilities and the ATMOS platform as open-source hardware and software contributions. Preliminary results showcase SITL and real testing.