 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysGraph: A Physics-aware 3D Scene Graph for Perception and Reasoning
Jun 07, 2026To perform a wide range of daily tasks, robots need to construct a 3D representation that is semantically rich, physically grounded, and structured enough to support task planning and affordance prediction. However, existing approaches primarily focus on semantic retrieval, often overlooking physical and kinematic factors. Methods that attempt to model physical properties typically rely on narrow training sets or single-object modeling, limiting scalability and generalization across diverse object types. To address these challenges, we present PhysGraph, a framework that unifies symbolic reasoning with structured 3D geometry to model kinematic and physical properties in cluttered scenes. Given RGB-D observations, PhysGraph reconstructs object-centric 3D geometry and associates object instances across views. It then decomposes objects into functional parts and infers materials and articulations through visual reasoning. Evaluated on both synthetic and real-world datasets, PhysGraph achieves state-of-the-art results in semantic segmentation, multi-object mass estimation, and articulation prediction. With its simple yet effective design, PhysGraph produces physically consistent and semantically structured scene graphs, serving as a structured 3D representation for downstream tasks such as constraint-aware 3D affordance prediction and real-to-sim transfer, both of which are demonstrated in our experiments.
Any-ttach: Quick End-effector Swapping Enables Manipulation Dexterity with Simplicity
May 28, 2026Robotic manipulation dexterity is often pursued by building increasingly complex high-DoF multifingered hands. While many robotic hands are designed to replicate human morphology, the functional role of human hands suggests a different perspective: much of their complexity may exist to enable tool use and tool making. This observation motivates Any-ttach, a tool-centric manipulation framework that treats quick end-effector swapping as a mechanism for dexterity with simplicity. Any-ttach combines a low-cost automatic swapping mechanism for an open-close robot interface, a handheld device for collecting human demonstrations, and a task planning framework that composes learned, parameterized, and planned tool-use skills. The system supports diverse tools and end-effector modules, including daily tools, articulated tools such as scissors, Fin Ray fingers, and a low-cost anthropomorphic hand, through the same shared interface. Our experiments show that Any-ttach improves tool-swapping reliability, increases demonstration efficiency, reduces tool-pose variability, and supports diverse tool-use skills. In two long-horizon tasks, making a sandwich and preparing a cucumber, Any-ttach executes six tool-use subskills through end-effector switching and execution monitoring. These results suggest that robots can expand manipulation capability not only through more complex end-effectors, but also through rapidly exchangeable tools and end-effector modules. More details and videos are available at https://any-ttach.github.io/.
CEER: Compliant End-Effector and Root Control as a Unified Interface for Hierarchical Humanoid Loco-Manipulation
May 19, 2026Humanoid robots have achieved impressive locomotion performance, yet contact-rich and long-horizon manipulation remains a major bottleneck. Manipulation is inherently contact-rich and demands compliant whole-body control for stable interaction, while its diversity and long-horizon nature favor modular, planner-compatible interfaces over joint-space tracking. We propose CEER, a compliant end-effector-root (EE-root) control abstraction for modular humanoid loco-manipulation within a hierarchical planning framework. CEER enables compliance-aware whole-body control in an interpretable task space defined by root motion commands and end-effector pose targets, and supports plug-and-play integration with heterogeneous high-level planners. A teacher-student framework is adopted to distill a general motion-tracking controller into a low-level policy that consumes only EE-root commands. We further construct a hierarchical system that integrates heterogeneous planners and task modules through the EE-root interface, enabling diverse manipulation tasks without retraining the underlying whole-body policy. Experiments in simulation and on hardware demonstrate 3.3 cm end-effector tracking accuracy with substantially reduced jerk compared to baselines, stable contact-rich manipulation under teleoperation, and up to 70% success in simulated single-object loco-manipulation tasks within a room-scale environment. These results indicate that compliant EE-root control provides a practical abstraction for humanoid loco-manipulation, enabling modular and scalable integration of diverse skills.
OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
Dec 18, 2025The human hand is our primary interface to the physical world, yet egocentric perception rarely knows when, where, or how forcefully it makes contact. Robust wearable tactile sensors are scarce, and no existing in-the-wild datasets align first-person video with full-hand touch. To bridge the gap between visual perception and physical interaction, we present OpenTouch, the first in-the-wild egocentric full-hand tactile dataset, containing 5.1 hours of synchronized video-touch-pose data and 2,900 curated clips with detailed text annotations. Using OpenTouch, we introduce retrieval and classification benchmarks that probe how touch grounds perception and action. We show that tactile signals provide a compact yet powerful cue for grasp understanding, strengthen cross-modal alignment, and can be reliably retrieved from in-the-wild video queries. By releasing this annotated vision-touch-pose dataset and benchmark, we aim to advance multimodal egocentric perception, embodied learning, and contact-rich robotic manipulation.
Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
Jan 03, 2025



Humanoid robots have great potential to perform various human-level skills. These skills involve locomotion, manipulation, and cognitive capabilities. Driven by advances in machine learning and the strength of existing model-based approaches, these capabilities have progressed rapidly, but often separately. Therefore, a timely overview of current progress and future trends in this fast-evolving field is essential. This survey first summarizes the model-based planning and control that have been the backbone of humanoid robotics for the past three decades. We then explore emerging learning-based methods, with a focus on reinforcement learning and imitation learning that enhance the versatility of loco-manipulation skills. We examine the potential of integrating foundation models with humanoid embodiments, assessing the prospects for developing generalist humanoid agents. In addition, this survey covers emerging research for whole-body tactile sensing that unlocks new humanoid skills that involve physical interactions. The survey concludes with a discussion of the challenges and future trends.
Co-Designing Tools and Control Policies for Robust Manipulation
Sep 17, 2024Inherent robustness in manipulation is prevalent in biological systems and critical for robotic manipulation systems due to real-world uncertainties and disturbances. This robustness relies not only on robust control policies but also on the design characteristics of the end-effectors. This paper introduces a bi-level optimization approach to co-designing tools and control policies to achieve robust manipulation. The approach employs reinforcement learning for lower-level control policy learning and multi-task Bayesian optimization for upper-level design optimization. Diverging from prior approaches, we incorporate caging-based robustness metrics into both levels, ensuring manipulation robustness against disturbances and environmental variations. Our method is evaluated in four non-prehensile manipulation environments, demonstrating improvements in task success rate under disturbances and environment changes. A real-world experiment is also conducted to validate the framework's practical effectiveness.
Caging in Motion: Characterizing Robustness in Manipulation through Energy Margin and Dynamic Caging Analysis
Apr 18, 2024


To develop robust manipulation policies, quantifying robustness is essential. Evaluating robustness in general dexterous manipulation, nonetheless, poses significant challenges due to complex hybrid dynamics, combinatorial explosion of possible contact interactions, global geometry, etc. This paper introduces ``caging in motion'', an approach for analyzing manipulation robustness through energy margins and caging-based analysis. Our method assesses manipulation robustness by measuring the energy margin to failure and extends traditional caging concepts for a global analysis of dynamic manipulation. This global analysis is facilitated by a kinodynamic planning framework that naturally integrates global geometry, contact changes, and robot compliance. We validate the effectiveness of our approach in the simulation and real-world experiments of multiple dynamic manipulation scenarios, highlighting its potential to predict manipulation success and robustness.
WebArena: A Realistic Web Environment for Building Autonomous Agents
Jul 25, 2023



With generative AI advances, the exciting potential for autonomous agents to manage daily tasks via natural language commands has emerged. However, cur rent agents are primarily created and tested in simplified synthetic environments, substantially limiting real-world scenario representation. In this paper, we build an environment for agent command and control that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on websites, and we create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and are designed to emulate tasks that humans routinely perform on the internet. We design and implement several autonomous agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 10.59%. These results highlight the need for further development of robust agents, that current state-of-the-art LMs are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress. Our code, data, environment reproduction resources, and video demonstrations are publicly available at https://webarena.dev/.
Enhancing Dexterity in Robotic Manipulation via Hierarchical Contact Exploration
Jul 01, 2023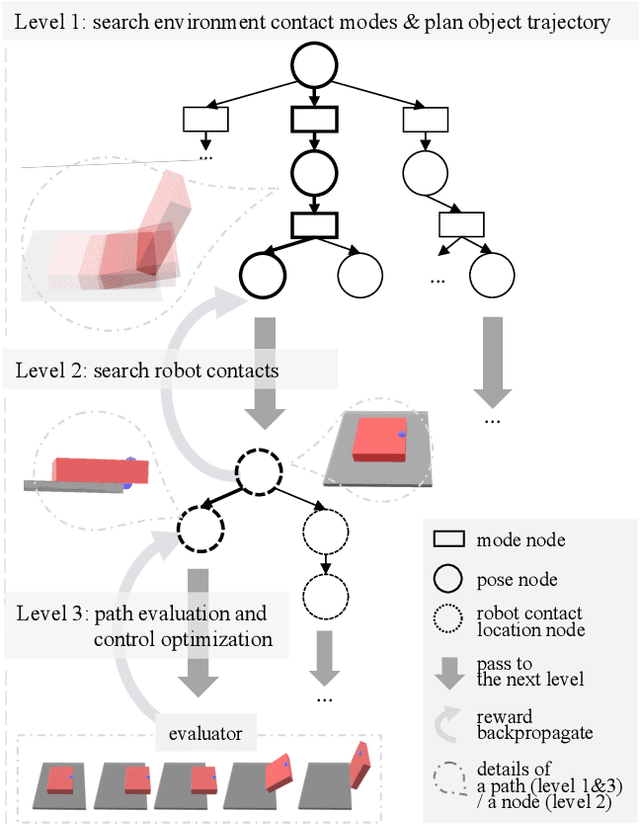
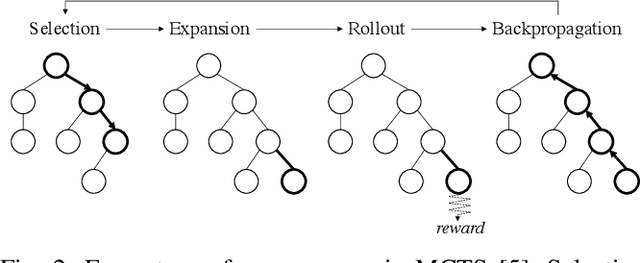
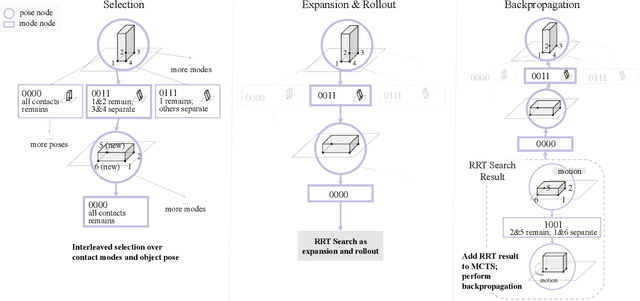

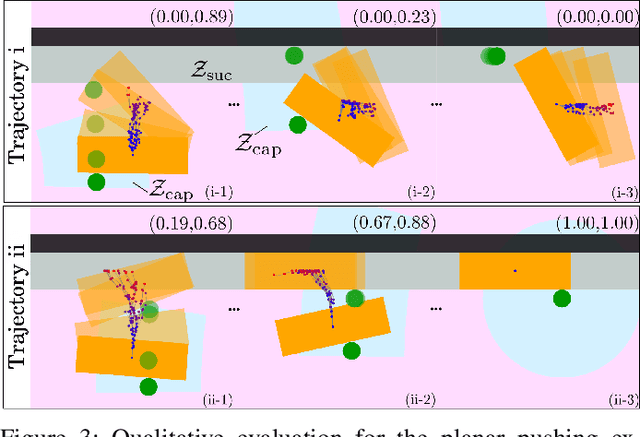
We present a hierarchical planning framework for dexterous robotic manipulation (HiDex). This framework exploits in-hand and extrinsic dexterity by actively exploring contacts. It generates rigid-body motions and complex contact sequences. Our framework is based on Monte-Carlo Tree Search (MCTS) and has three levels: 1) planning object motions and environment contact modes; 2) planning robot contacts; 3) path evaluation and control optimization that passes the rewards to the upper levels. This framework offers two main advantages. First, it allows efficient global reasoning over high-dimensional complex space created by contacts. It solves a diverse set of manipulation tasks that require dexterity, both intrinsic (using the fingers) and extrinsic (also using the environment), mostly in seconds. Second, our framework allows the incorporation of expert knowledge and customizable setups in task mechanics and models. It requires minor modifications to accommodate different scenarios and robots. Hence, it could provide a flexible and generalizable solution for various manipulation tasks. As examples, we analyze the results on 7 hand configurations and 15 scenarios. We demonstrate 8 of them on two robot platforms.
Learning Preconditions of Hybrid Force-Velocity Controllers for Contact-Rich Manipulation
Jun 25, 2022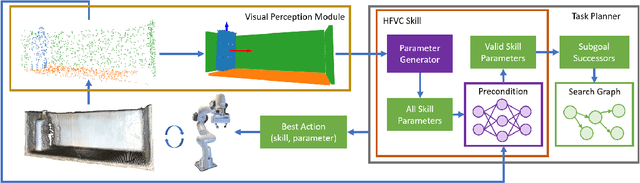



Robots need to manipulate objects in constrained environments like shelves and cabinets when assisting humans in everyday settings like homes and offices. These constraints make manipulation difficult by reducing grasp accessibility, so robots need to use non-prehensile strategies that leverage object-environment contacts to perform manipulation tasks. To tackle the challenge of planning and controlling contact-rich behaviors in such settings, this work uses Hybrid Force-Velocity Controllers (HFVCs) as the skill representation and plans skill sequences with learned preconditions. While HFVCs naturally enable robust and compliant contact-rich behaviors, solvers that synthesize them have traditionally relied on precise object models and closed-loop feedback on object pose, which are difficult to obtain in constrained environments due to occlusions. We first relax HFVCs' need for precise models and feedback with our HFVC synthesis framework, then learn a point-cloud-based precondition function to classify where HFVC executions will still be successful despite modeling inaccuracies. Finally, we use the learned precondition in a search-based task planner to complete contact-rich manipulation tasks in a shelf domain. Our method achieves a task success rate of $73.2\%$, outperforming the $51.5\%$ achieved by a baseline without the learned precondition. While the precondition function is trained in simulation, it can also transfer to a real-world setup without further fine-tuning.