 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Humanoid Walking on Compliant and Uneven Terrain with Deep Reinforcement Learning
Apr 18, 2025For the deployment of legged robots in real-world environments, it is essential to develop robust locomotion control methods for challenging terrains that may exhibit unexpected deformability and irregularity. In this paper, we explore the application of sim-to-real deep reinforcement learning (RL) for the design of bipedal locomotion controllers for humanoid robots on compliant and uneven terrains. Our key contribution is to show that a simple training curriculum for exposing the RL agent to randomized terrains in simulation can achieve robust walking on a real humanoid robot using only proprioceptive feedback. We train an end-to-end bipedal locomotion policy using the proposed approach, and show extensive real-robot demonstration on the HRP-5P humanoid over several difficult terrains inside and outside the lab environment. Further, we argue that the robustness of a bipedal walking policy can be improved if the robot is allowed to exhibit aperiodic motion with variable stepping frequency. We propose a new control policy to enable modification of the observed clock signal, leading to adaptive gait frequencies depending on the terrain and command velocity. Through simulation experiments, we show the effectiveness of this policy specifically for walking over challenging terrains by controlling swing and stance durations. The code for training and evaluation is available online at https://github.com/rohanpsingh/LearningHumanoidWalking. Demo video is available at https://www.youtube.com/watch?v=ZgfNzGAkk2Q.
Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
Jan 03, 2025



Humanoid robots have great potential to perform various human-level skills. These skills involve locomotion, manipulation, and cognitive capabilities. Driven by advances in machine learning and the strength of existing model-based approaches, these capabilities have progressed rapidly, but often separately. Therefore, a timely overview of current progress and future trends in this fast-evolving field is essential. This survey first summarizes the model-based planning and control that have been the backbone of humanoid robotics for the past three decades. We then explore emerging learning-based methods, with a focus on reinforcement learning and imitation learning that enhance the versatility of loco-manipulation skills. We examine the potential of integrating foundation models with humanoid embodiments, assessing the prospects for developing generalist humanoid agents. In addition, this survey covers emerging research for whole-body tactile sensing that unlocks new humanoid skills that involve physical interactions. The survey concludes with a discussion of the challenges and future trends.
Learning-based legged locomotion; state of the art and future perspectives
Jun 03, 2024Legged locomotion holds the premise of universal mobility, a critical capability for many real-world robotic applications. Both model-based and learning-based approaches have advanced the field of legged locomotion in the past three decades. In recent years, however, a number of factors have dramatically accelerated progress in learning-based methods, including the rise of deep learning, rapid progress in simulating robotic systems, and the availability of high-performance and affordable hardware. This article aims to give a brief history of the field, to summarize recent efforts in learning locomotion skills for quadrupeds, and to provide researchers new to the area with an understanding of the key issues involved. With the recent proliferation of humanoid robots, we further outline the rapid rise of analogous methods for bipedal locomotion. We conclude with a discussion of open problems as well as related societal impact.
PDP: Physics-Based Character Animation via Diffusion Policy
Jun 03, 2024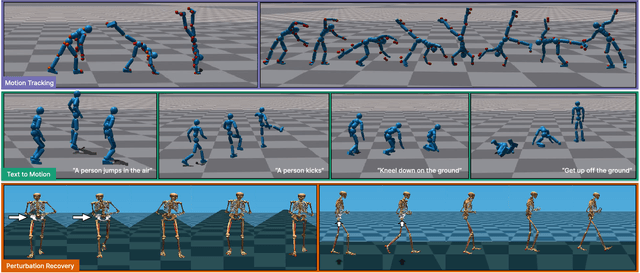
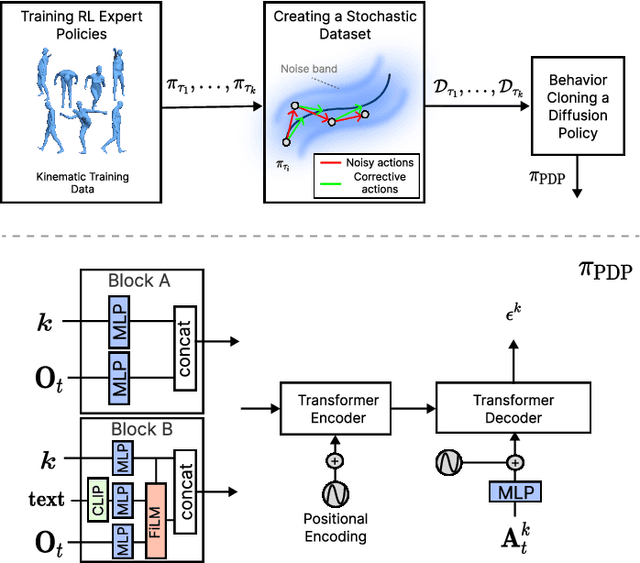

Generating diverse and realistic human motion that can physically interact with an environment remains a challenging research area in character animation. Meanwhile, diffusion-based methods, as proposed by the robotics community, have demonstrated the ability to capture highly diverse and multi-modal skills. However, naively training a diffusion policy often results in unstable motions for high-frequency, under-actuated control tasks like bipedal locomotion due to rapidly accumulating compounding errors, pushing the agent away from optimal training trajectories. The key idea lies in using RL policies not just for providing optimal trajectories but for providing corrective actions in sub-optimal states, giving the policy a chance to correct for errors caused by environmental stimulus, model errors, or numerical errors in simulation. Our method, Physics-Based Character Animation via Diffusion Policy (PDP), combines reinforcement learning (RL) and behavior cloning (BC) to create a robust diffusion policy for physics-based character animation. We demonstrate PDP on perturbation recovery, universal motion tracking, and physics-based text-to-motion synthesis.
Hierarchical Planning and Control for Box Loco-Manipulation
Jun 15, 2023

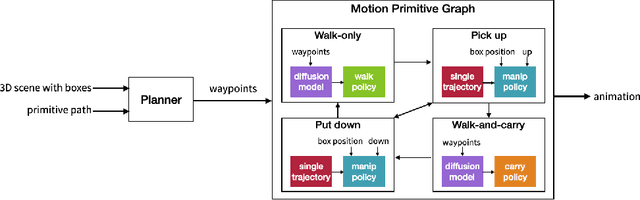

Humans perform everyday tasks using a combination of locomotion and manipulation skills. Building a system that can handle both skills is essential to creating virtual humans. We present a physically-simulated human capable of solving box rearrangement tasks, which requires a combination of both skills. We propose a hierarchical control architecture, where each level solves the task at a different level of abstraction, and the result is a physics-based simulated virtual human capable of rearranging boxes in a cluttered environment. The control architecture integrates a planner, diffusion models, and physics-based motion imitation of sparse motion clips using deep reinforcement learning. Boxes can vary in size, weight, shape, and placement height. Code and trained control policies are provided.
Learning Bipedal Walking for Humanoids with Current Feedback
Mar 07, 2023



Recent advances in deep reinforcement learning (RL) based techniques combined with training in simulation have offered a new approach to developing control policies for legged robots. However, the application of such approaches to real hardware has largely been limited to quadrupedal robots with direct-drive actuators and light-weight bipedal robots with low gear-ratio transmission systems. Application to life-sized humanoid robots has been elusive due to the large sim-to-real gap arising from their large size, heavier limbs, and a high gear-ratio transmission systems. In this paper, we present an approach for effectively overcoming the sim-to-real gap issue for humanoid robots arising from inaccurate torque tracking at the actuator level. Our key idea is to utilize the current feedback from the motors on the real robot, after training the policy in a simulation environment artificially degraded with poor torque tracking. Our approach successfully trains an end-to-end policy in simulation that can be deployed on a real HRP-5P humanoid robot for bipedal locomotion on challenging terrain. We also perform robustness tests on the RL policy and compare its performance against a conventional model-based controller for walking on uneven terrain. YouTube video: https://youtu.be/IeUaSsBRbNY
OPT-Mimic: Imitation of Optimized Trajectories for Dynamic Quadruped Behaviors
Oct 03, 2022
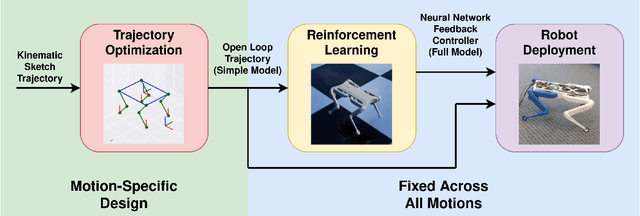

Reinforcement Learning (RL) has seen many recent successes for quadruped robot control. The imitation of reference motions provides a simple and powerful prior for guiding solutions towards desired solutions without the need for meticulous reward design. While much work uses motion capture data or hand-crafted trajectories as the reference motion, relatively little work has explored the use of reference motions coming from model-based trajectory optimization. In this work, we investigate several design considerations that arise with such a framework, as demonstrated through four dynamic behaviours: trot, front hop, 180 backflip, and biped stepping. These are trained in simulation and transferred to a physical Solo 8 quadruped robot without further adaptation. In particular, we explore the space of feed-forward designs afforded by the trajectory optimizer to understand its impact on RL learning efficiency and sim-to-real transfer. These findings contribute to the long standing goal of producing robot controllers that combine the interpretability and precision of model-based optimization with the robustness that model-free RL-based controllers offer.
GLiDE: Generalizable Quadrupedal Locomotion in Diverse Environments with a Centroidal Model
Apr 22, 2021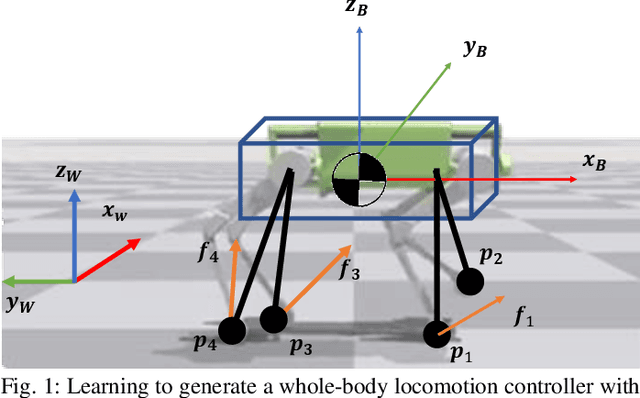

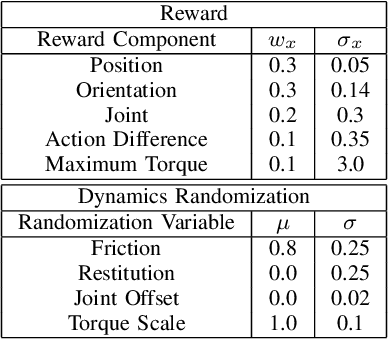
Model-free reinforcement learning (RL) for legged locomotion commonly relies on a physics simulator that can accurately predict the behaviors of every degree of freedom of the robot. In contrast, approximate reduced-order models are often sufficient for many model-based control strategies. In this work we explore how RL can be effectively used with a centroidal model to generate robust control policies for quadrupedal locomotion. Advantages over RL with a full-order model include a simple reward structure, reduced computational costs, and robust sim-to-real transfer. We further show the potential of the method by demonstrating stepping-stone locomotion, two-legged in-place balance, balance beam locomotion, and sim-to-real transfer without further adaptations. Additional Results: https://www.pair.toronto.edu/glide-quadruped/.
Dynamics Randomization Revisited:A Case Study for Quadrupedal Locomotion
Nov 04, 2020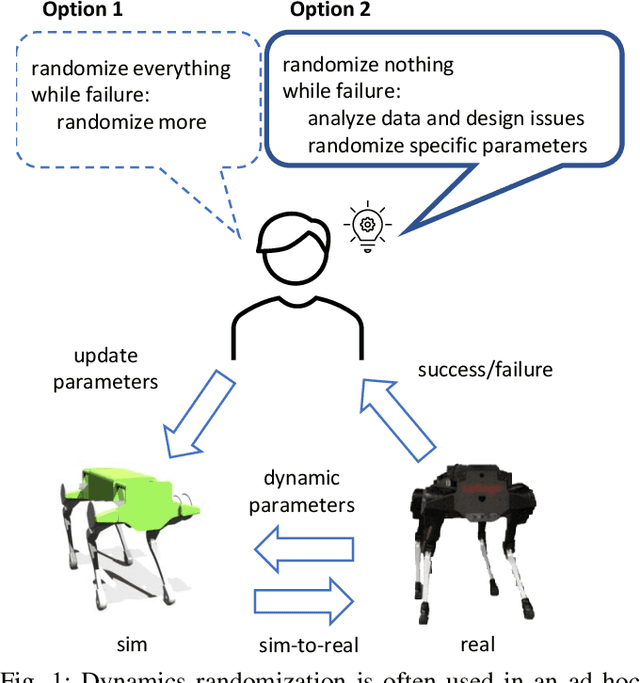
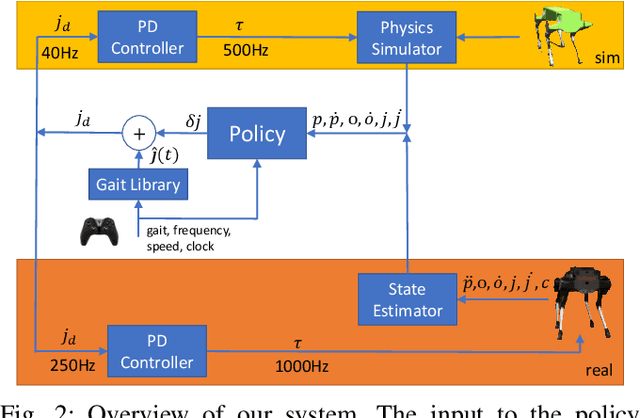

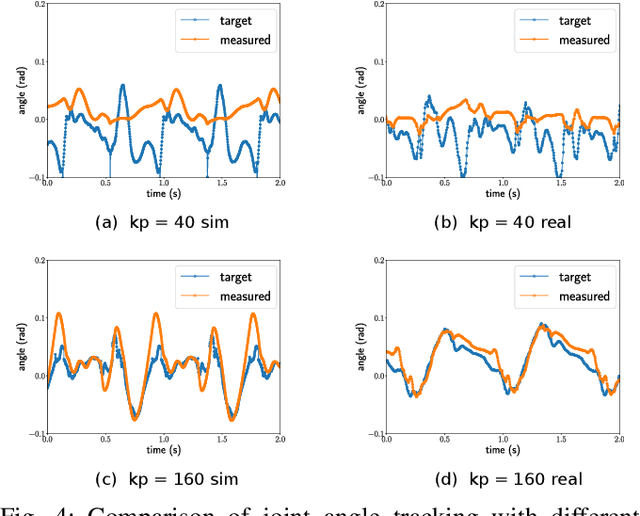
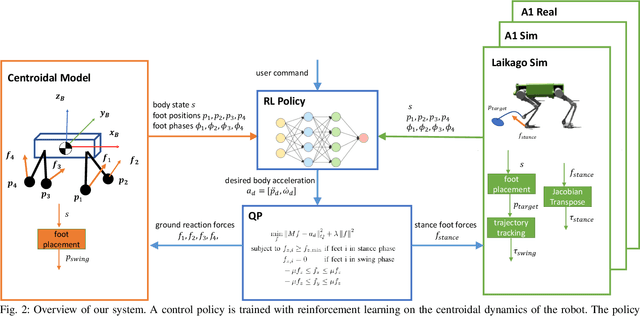
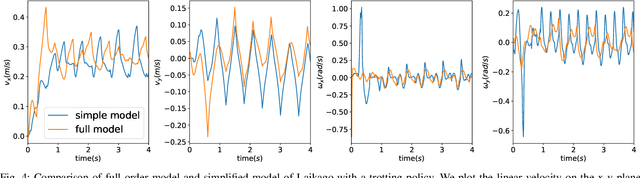
Understanding the gap between simulation andreality is critical for reinforcement learning with legged robots,which are largely trained in simulation. However, recent workhas resulted in sometimes conflicting conclusions with regardto which factors are important for success, including therole of dynamics randomization. In this paper, we aim toprovide clarity and understanding on the role of dynamicsrandomization in learning robust locomotion policies for theLaikago quadruped robot. Surprisingly, in contrast to priorwork with the same robot model, we find that direct sim-to-real transfer is possible without dynamics randomizationor on-robot adaptation schemes. We conduct extensive abla-tion studies in a sim-to-sim setting to understand the keyissues underlying successful policy transfer, including otherdesign decisions that can impact policy robustness. We furtherground our conclusions via sim-to-real experiments with variousgaits, speeds, and stepping frequencies. Additional Details: https://www.pair.toronto.edu/understanding-dr/.
Learning a Contact-Adaptive Controller for Robust, Efficient Legged Locomotion
Oct 05, 2020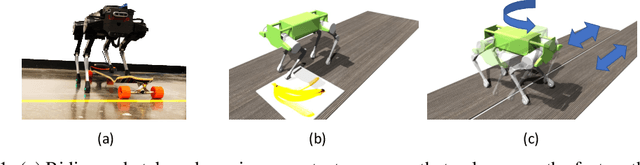
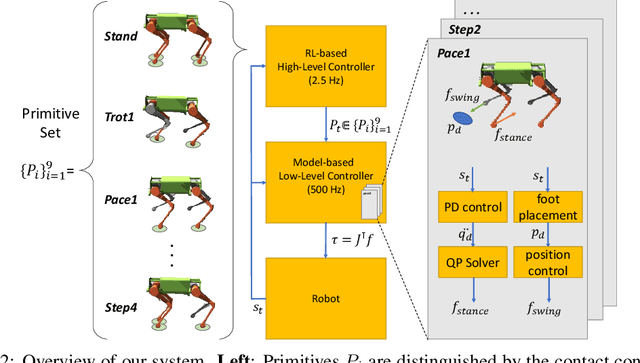

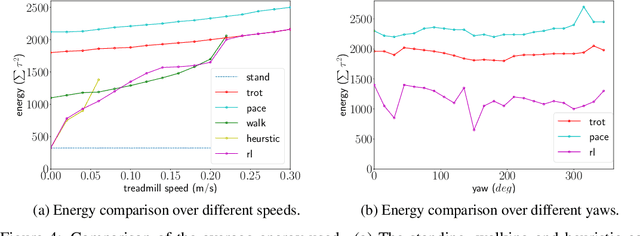
We present a hierarchical framework that combines model-based control and reinforcement learning (RL) to synthesize robust controllers for a quadruped (the Unitree Laikago). The system consists of a high-level controller that learns to choose from a set of primitives in response to changes in the environment and a low-level controller that utilizes an established control method to robustly execute the primitives. Our framework learns a controller that can adapt to challenging environmental changes on the fly, including novel scenarios not seen during training. The learned controller is up to 85~percent more energy efficient and is more robust compared to baseline methods. We also deploy the controller on a physical robot without any randomization or adaptation scheme.