 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancing Points: Synthesizing Ballroom Dancing with Three-Point Inputs
Jan 05, 2026Ballroom dancing is a structured yet expressive motion category. Its highly diverse movement and complex interactions between leader and follower dancers make the understanding and synthesis challenging. We demonstrate that the three-point trajectory available from a virtual reality (VR) device can effectively serve as a dancer's motion descriptor, simplifying the modeling and synthesis of interplay between dancers' full-body motions down to sparse trajectories. Thanks to the low dimensionality, we can employ an efficient MLP network to predict the follower's three-point trajectory directly from the leader's three-point input for certain types of ballroom dancing, addressing the challenge of modeling high-dimensional full-body interaction. It also prevents our method from overfitting thanks to its compact yet explicit representation. By leveraging the inherent structure of the movements and carefully planning the autoregressive procedure, we show a deterministic neural network is able to translate three-point trajectories into a virtual embodied avatar, which is typically considered under-constrained and requires generative models for common motions. In addition, we demonstrate this deterministic approach generalizes beyond small, structured datasets like ballroom dancing, and performs robustly on larger, more diverse datasets such as LaFAN. Our method provides a computationally- and data-efficient solution, opening new possibilities for immersive paired dancing applications. Code and pre-trained models for this paper are available at https://peizhuoli.github.io/dancing-points.
SCENIC: Scene-aware Semantic Navigation with Instruction-guided Control
Dec 20, 2024



Synthesizing natural human motion that adapts to complex environments while allowing creative control remains a fundamental challenge in motion synthesis. Existing models often fall short, either by assuming flat terrain or lacking the ability to control motion semantics through text. To address these limitations, we introduce SCENIC, a diffusion model designed to generate human motion that adapts to dynamic terrains within virtual scenes while enabling semantic control through natural language. The key technical challenge lies in simultaneously reasoning about complex scene geometry while maintaining text control. This requires understanding both high-level navigation goals and fine-grained environmental constraints. The model must ensure physical plausibility and precise navigation across varied terrain, while also preserving user-specified text control, such as ``carefully stepping over obstacles" or ``walking upstairs like a zombie." Our solution introduces a hierarchical scene reasoning approach. At its core is a novel scene-dependent, goal-centric canonicalization that handles high-level goal constraint, and is complemented by an ego-centric distance field that captures local geometric details. This dual representation enables our model to generate physically plausible motion across diverse 3D scenes. By implementing frame-wise text alignment, our system achieves seamless transitions between different motion styles while maintaining scene constraints. Experiments demonstrate our novel diffusion model generates arbitrarily long human motions that both adapt to complex scenes with varying terrain surfaces and respond to textual prompts. Additionally, we show SCENIC can generalize to four real-scene datasets. Our code, dataset, and models will be released at \url{https://virtualhumans.mpi-inf.mpg.de/scenic/}.
CHOICE: Coordinated Human-Object Interaction in Cluttered Environments for Pick-and-Place Actions
Dec 09, 2024
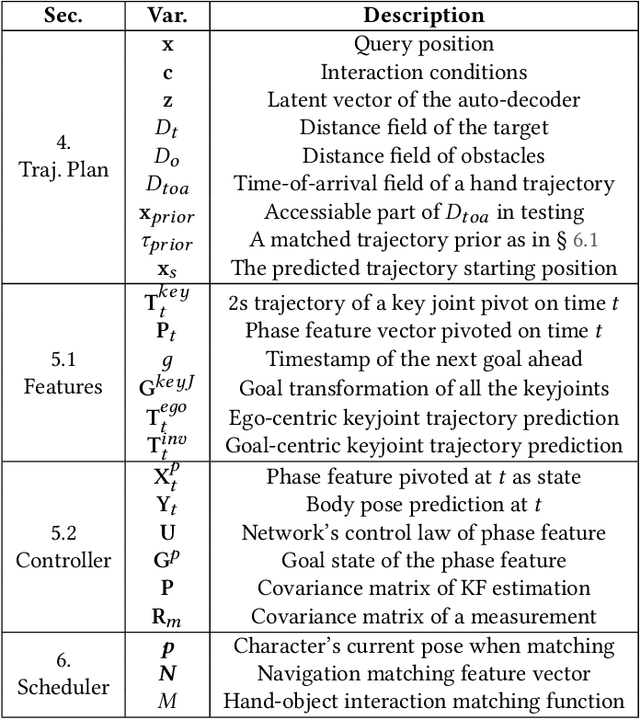
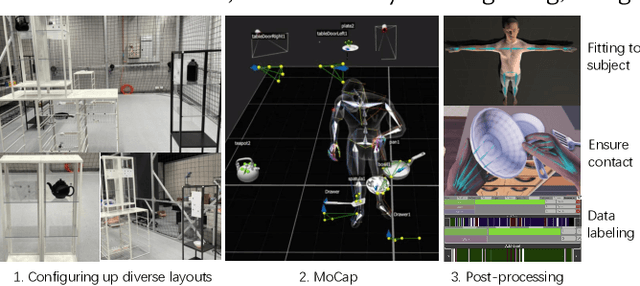
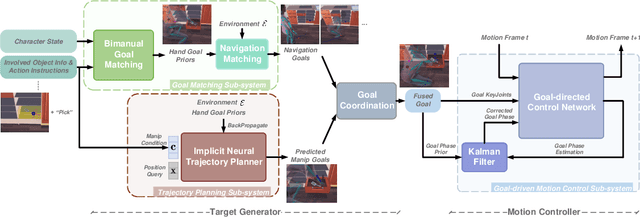
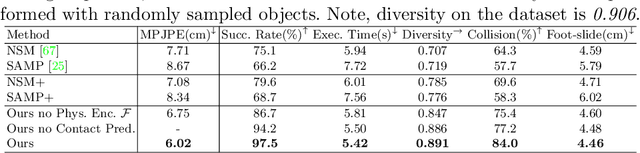
Animating human-scene interactions such as pick-and-place tasks in cluttered, complex layouts is a challenging task, with objects of a wide variation of geometries and articulation under scenarios with various obstacles. The main difficulty lies in the sparsity of the motion data compared to the wide variation of the objects and environments as well as the poor availability of transition motions between different tasks, increasing the complexity of the generalization to arbitrary conditions. To cope with this issue, we develop a system that tackles the interaction synthesis problem as a hierarchical goal-driven task. Firstly, we develop a bimanual scheduler that plans a set of keyframes for simultaneously controlling the two hands to efficiently achieve the pick-and-place task from an abstract goal signal such as the target object selected by the user. Next, we develop a neural implicit planner that generates guidance hand trajectories under diverse object shape/types and obstacle layouts. Finally, we propose a linear dynamic model for our DeepPhase controller that incorporates a Kalman filter to enable smooth transitions in the frequency domain, resulting in a more realistic and effective multi-objective control of the character.Our system can produce a wide range of natural pick-and-place movements with respect to the geometry of objects, the articulation of containers and the layout of the objects in the scene.
FORCE: Dataset and Method for Intuitive Physics Guided Human-object Interaction
Mar 17, 2024

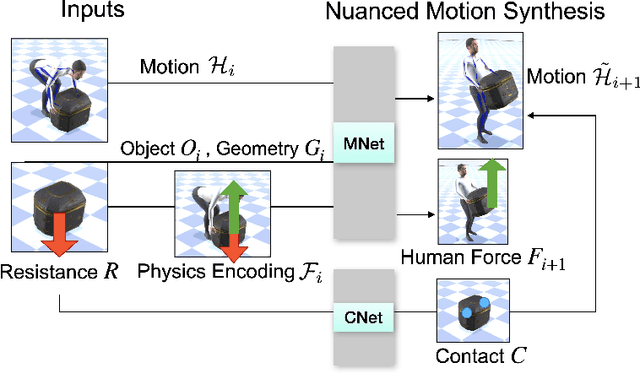
Interactions between human and objects are influenced not only by the object's pose and shape, but also by physical attributes such as object mass and surface friction. They introduce important motion nuances that are essential for diversity and realism. Despite advancements in recent kinematics-based methods, this aspect has been overlooked. Generating nuanced human motion presents two challenges. First, it is non-trivial to learn from multi-modal human and object information derived from both the physical and non-physical attributes. Second, there exists no dataset capturing nuanced human interactions with objects of varying physical properties, hampering model development. This work addresses the gap by introducing the FORCE model, a kinematic approach for synthesizing diverse, nuanced human-object interactions by modeling physical attributes. Our key insight is that human motion is dictated by the interrelation between the force exerted by the human and the perceived resistance. Guided by a novel intuitive physics encoding, the model captures the interplay between human force and resistance. Experiments also demonstrate incorporating human force facilitates learning multi-class motion. Accompanying our model, we contribute the FORCE dataset. It features diverse, different-styled motion through interactions with varying resistances.
Uncertainty Estimation in Instance Segmentation with Star-convex Shapes
Sep 19, 2023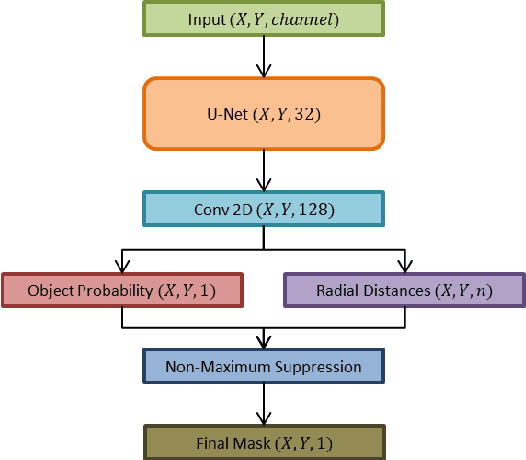
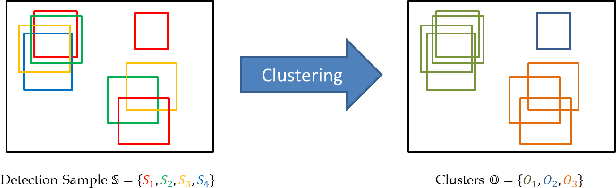
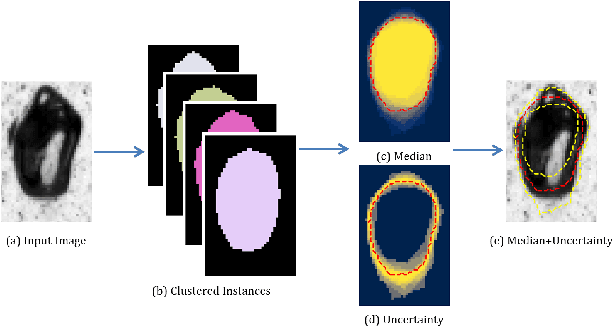
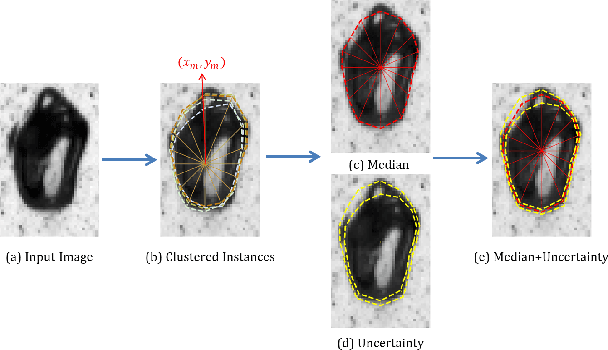
Instance segmentation has witnessed promising advancements through deep neural network-based algorithms. However, these models often exhibit incorrect predictions with unwarranted confidence levels. Consequently, evaluating prediction uncertainty becomes critical for informed decision-making. Existing methods primarily focus on quantifying uncertainty in classification or regression tasks, lacking emphasis on instance segmentation. Our research addresses the challenge of estimating spatial certainty associated with the location of instances with star-convex shapes. Two distinct clustering approaches are evaluated which compute spatial and fractional certainty per instance employing samples by the Monte-Carlo Dropout or Deep Ensemble technique. Our study demonstrates that combining spatial and fractional certainty scores yields improved calibrated estimation over individual certainty scores. Notably, our experimental results show that the Deep Ensemble technique alongside our novel radial clustering approach proves to be an effective strategy. Our findings emphasize the significance of evaluating the calibration of estimated certainties for model reliability and decision-making.
Motion In-Betweening with Phase Manifolds
Aug 24, 2023
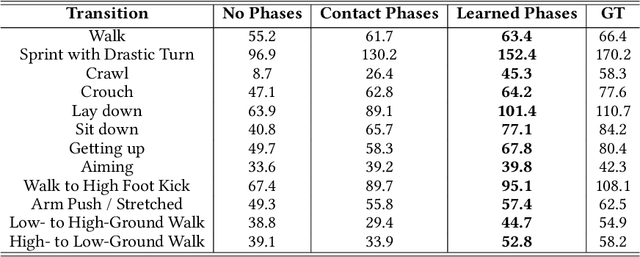
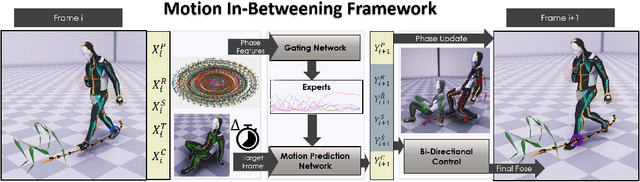

This paper introduces a novel data-driven motion in-betweening system to reach target poses of characters by making use of phases variables learned by a Periodic Autoencoder. Our approach utilizes a mixture-of-experts neural network model, in which the phases cluster movements in both space and time with different expert weights. Each generated set of weights then produces a sequence of poses in an autoregressive manner between the current and target state of the character. In addition, to satisfy poses which are manually modified by the animators or where certain end effectors serve as constraints to be reached by the animation, a learned bi-directional control scheme is implemented to satisfy such constraints. The results demonstrate that using phases for motion in-betweening tasks sharpen the interpolated movements, and furthermore stabilizes the learning process. Moreover, using phases for motion in-betweening tasks can also synthesize more challenging movements beyond locomotion behaviors. Additionally, style control is enabled between given target keyframes. Our proposed framework can compete with popular state-of-the-art methods for motion in-betweening in terms of motion quality and generalization, especially in the existence of long transition durations. Our framework contributes to faster prototyping workflows for creating animated character sequences, which is of enormous interest for the game and film industry.
* 17 pages, 11 figures, conference
Hierarchical Planning and Control for Box Loco-Manipulation
Jun 15, 2023

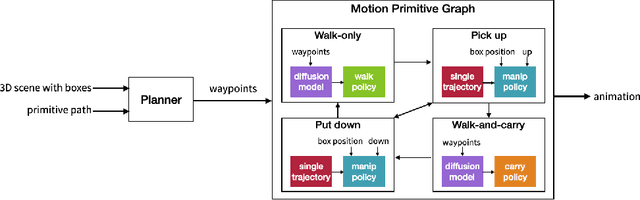

Humans perform everyday tasks using a combination of locomotion and manipulation skills. Building a system that can handle both skills is essential to creating virtual humans. We present a physically-simulated human capable of solving box rearrangement tasks, which requires a combination of both skills. We propose a hierarchical control architecture, where each level solves the task at a different level of abstraction, and the result is a physics-based simulated virtual human capable of rearranging boxes in a cluttered environment. The control architecture integrates a planner, diffusion models, and physics-based motion imitation of sparse motion clips using deep reinforcement learning. Boxes can vary in size, weight, shape, and placement height. Code and trained control policies are provided.
QuestEnvSim: Environment-Aware Simulated Motion Tracking from Sparse Sensors
Jun 09, 2023


Replicating a user's pose from only wearable sensors is important for many AR/VR applications. Most existing methods for motion tracking avoid environment interaction apart from foot-floor contact due to their complex dynamics and hard constraints. However, in daily life people regularly interact with their environment, e.g. by sitting on a couch or leaning on a desk. Using Reinforcement Learning, we show that headset and controller pose, if combined with physics simulation and environment observations can generate realistic full-body poses even in highly constrained environments. The physics simulation automatically enforces the various constraints necessary for realistic poses, instead of manually specifying them as in many kinematic approaches. These hard constraints allow us to achieve high-quality interaction motions without typical artifacts such as penetration or contact sliding. We discuss three features, the environment representation, the contact reward and scene randomization, crucial to the performance of the method. We demonstrate the generality of the approach through various examples, such as sitting on chairs, a couch and boxes, stepping over boxes, rocking a chair and turning an office chair. We believe these are some of the highest-quality results achieved for motion tracking from sparse sensor with scene interaction.
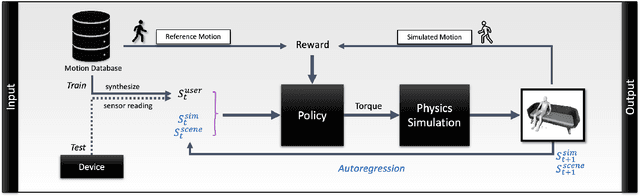
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model
Apr 17, 2023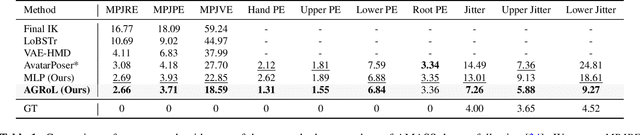
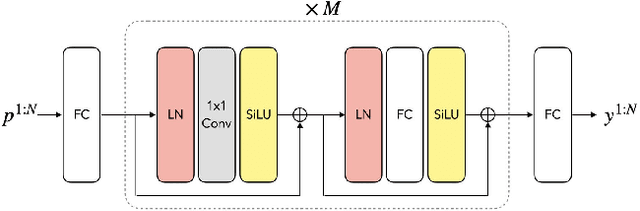
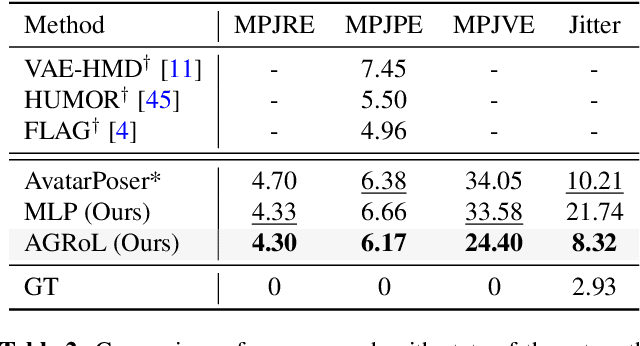
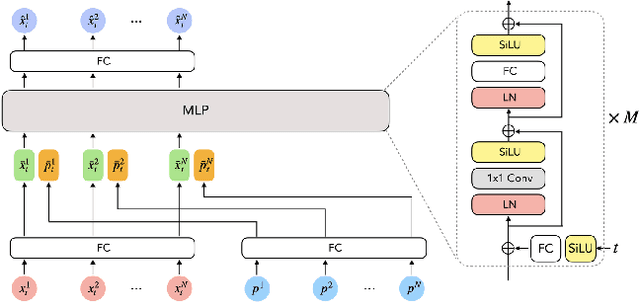
With the recent surge in popularity of AR/VR applications, realistic and accurate control of 3D full-body avatars has become a highly demanded feature. A particular challenge is that only a sparse tracking signal is available from standalone HMDs (Head Mounted Devices), often limited to tracking the user's head and wrists. While this signal is resourceful for reconstructing the upper body motion, the lower body is not tracked and must be synthesized from the limited information provided by the upper body joints. In this paper, we present AGRoL, a novel conditional diffusion model specifically designed to track full bodies given sparse upper-body tracking signals. Our model is based on a simple multi-layer perceptron (MLP) architecture and a novel conditioning scheme for motion data. It can predict accurate and smooth full-body motion, particularly the challenging lower body movement. Unlike common diffusion architectures, our compact architecture can run in real-time, making it suitable for online body-tracking applications. We train and evaluate our model on AMASS motion capture dataset, and demonstrate that our approach outperforms state-of-the-art methods in generated motion accuracy and smoothness. We further justify our design choices through extensive experiments and ablation studies.
COUCH: Towards Controllable Human-Chair Interactions
May 01, 2022

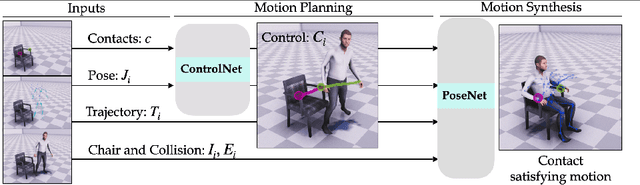
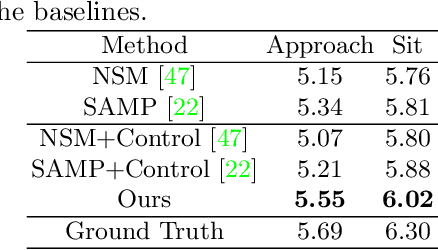
Humans interact with an object in many different ways by making contact at different locations, creating a highly complex motion space that can be difficult to learn, particularly when synthesizing such human interactions in a controllable manner. Existing works on synthesizing human scene interaction focus on the high-level control of action but do not consider the fine-grained control of motion. In this work, we study the problem of synthesizing scene interactions conditioned on different contact positions on the object. As a testbed to investigate this new problem, we focus on human-chair interaction as one of the most common actions which exhibit large variability in terms of contacts. We propose a novel synthesis framework COUCH that plans ahead the motion by predicting contact-aware control signals of the hands, which are then used to synthesize contact-conditioned interactions. Furthermore, we contribute a large human-chair interaction dataset with clean annotations, the COUCH Dataset. Our method shows significant quantitative and qualitative improvements over existing methods for human-object interactions. More importantly, our method enables control of the motion through user-specified or automatically predicted contacts.