 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCENIC: Scene-aware Semantic Navigation with Instruction-guided Control
Dec 20, 2024



Synthesizing natural human motion that adapts to complex environments while allowing creative control remains a fundamental challenge in motion synthesis. Existing models often fall short, either by assuming flat terrain or lacking the ability to control motion semantics through text. To address these limitations, we introduce SCENIC, a diffusion model designed to generate human motion that adapts to dynamic terrains within virtual scenes while enabling semantic control through natural language. The key technical challenge lies in simultaneously reasoning about complex scene geometry while maintaining text control. This requires understanding both high-level navigation goals and fine-grained environmental constraints. The model must ensure physical plausibility and precise navigation across varied terrain, while also preserving user-specified text control, such as ``carefully stepping over obstacles" or ``walking upstairs like a zombie." Our solution introduces a hierarchical scene reasoning approach. At its core is a novel scene-dependent, goal-centric canonicalization that handles high-level goal constraint, and is complemented by an ego-centric distance field that captures local geometric details. This dual representation enables our model to generate physically plausible motion across diverse 3D scenes. By implementing frame-wise text alignment, our system achieves seamless transitions between different motion styles while maintaining scene constraints. Experiments demonstrate our novel diffusion model generates arbitrarily long human motions that both adapt to complex scenes with varying terrain surfaces and respond to textual prompts. Additionally, we show SCENIC can generalize to four real-scene datasets. Our code, dataset, and models will be released at \url{https://virtualhumans.mpi-inf.mpg.de/scenic/}.
Self-supervised HDR Imaging from Motion and Exposure Cues
Mar 23, 2022
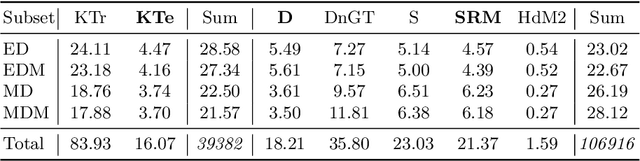
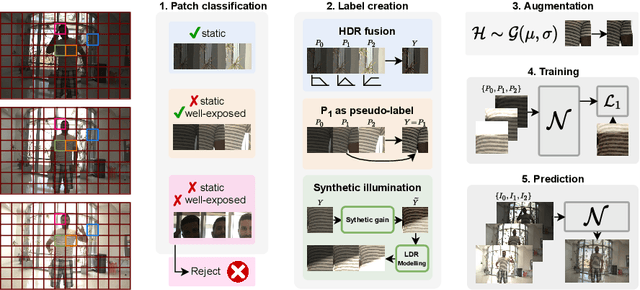
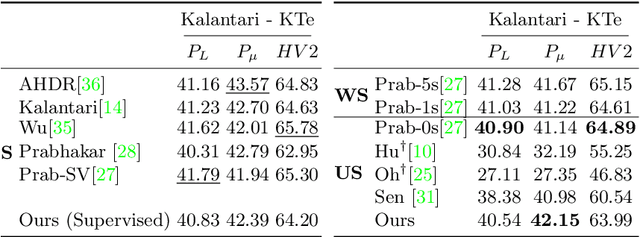
Recent High Dynamic Range (HDR) techniques extend the capabilities of current cameras where scenes with a wide range of illumination can not be accurately captured with a single low-dynamic-range (LDR) image. This is generally accomplished by capturing several LDR images with varying exposure values whose information is then incorporated into a merged HDR image. While such approaches work well for static scenes, dynamic scenes pose several challenges, mostly related to the difficulty of finding reliable pixel correspondences. Data-driven approaches tackle the problem by learning an end-to-end mapping with paired LDR-HDR training data, but in practice generating such HDR ground-truth labels for dynamic scenes is time-consuming and requires complex procedures that assume control of certain dynamic elements of the scene (e.g. actor pose) and repeatable lighting conditions (stop-motion capturing). In this work, we propose a novel self-supervised approach for learnable HDR estimation that alleviates the need for HDR ground-truth labels. We propose to leverage the internal statistics of LDR images to create HDR pseudo-labels. We separately exploit static and well-exposed parts of the input images, which in conjunction with synthetic illumination clipping and motion augmentation provide high quality training examples. Experimental results show that the HDR models trained using our proposed self-supervision approach achieve performance competitive with those trained under full supervision, and are to a large extent superior to previous methods that equally do not require any supervision.