 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRVS: a Generalizable and Recurrent Approach to Monocular Dynamic View Synthesis
Mar 31, 2026Synthesizing novel views from monocular videos of dynamic scenes remains a challenging problem. Scene-specific methods that optimize 4D representations with explicit motion priors often break down in highly dynamic regions where multi-view information is hard to exploit. Diffusion-based approaches that integrate camera control into large pre-trained models can produce visually plausible videos but frequently suffer from geometric inconsistencies across both static and dynamic areas. Both families of methods also require substantial computational resources. Building on the success of generalizable models for static novel view synthesis, we adapt the framework to dynamic inputs and propose a new model with two key components: (1) a recurrent loop that enables unbounded and asynchronous mapping between input and target videos and (2) an efficient use of plane sweeps over dynamic inputs to disentangle camera and scene motion, and achieve fine-grained, six-degrees-of-freedom camera controls. We train and evaluate our model on the UCSD dataset and on Kubric-4D-dyn, a new monocular dynamic dataset featuring longer, higher resolution sequences with more complex scene dynamics than existing alternatives. Our model outperforms four Gaussian Splatting-based scene-specific approaches, as well as two diffusion-based approaches in reconstructing fine-grained geometric details across both static and dynamic regions.
Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
Dec 17, 2025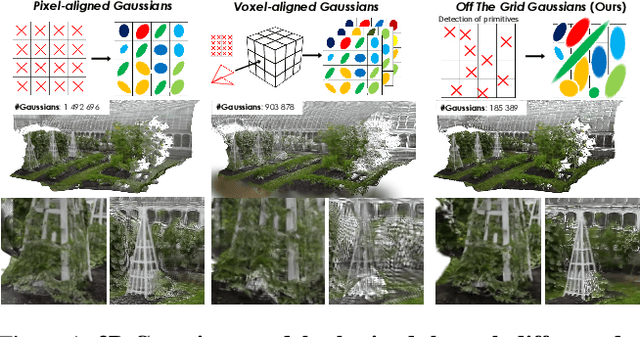
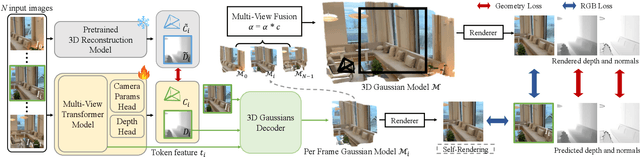


Feed-forward 3D Gaussian Splatting (3DGS) models enable real-time scene generation but are hindered by suboptimal pixel-aligned primitive placement, which relies on a dense, rigid grid and limits both quality and efficiency. We introduce a new feed-forward architecture that detects 3D Gaussian primitives at a sub-pixel level, replacing the pixel grid with an adaptive, "Off The Grid" distribution. Inspired by keypoint detection, our multi-resolution decoder learns to distribute primitives across image patches. This module is trained end-to-end with a 3D reconstruction backbone using self-supervised learning. Our resulting pose-free model generates photorealistic scenes in seconds, achieving state-of-the-art novel view synthesis for feed-forward models. It outperforms competitors while using far fewer primitives, demonstrating a more accurate and efficient allocation that captures fine details and reduces artifacts. Moreover, we observe that by learning to render 3D Gaussians, our 3D reconstruction backbone improves camera pose estimation, suggesting opportunities to train these foundational models without labels.
Charge: A Comprehensive Novel View Synthesis Benchmark and Dataset to Bind Them All
Dec 15, 2025This paper presents a new dataset for Novel View Synthesis, generated from a high-quality, animated film with stunning realism and intricate detail. Our dataset captures a variety of dynamic scenes, complete with detailed textures, lighting, and motion, making it ideal for training and evaluating cutting-edge 4D scene reconstruction and novel view generation models. In addition to high-fidelity RGB images, we provide multiple complementary modalities, including depth, surface normals, object segmentation and optical flow, enabling a deeper understanding of scene geometry and motion. The dataset is organised into three distinct benchmarking scenarios: a dense multi-view camera setup, a sparse camera arrangement, and monocular video sequences, enabling a wide range of experimentation and comparison across varying levels of data sparsity. With its combination of visual richness, high-quality annotations, and diverse experimental setups, this dataset offers a unique resource for pushing the boundaries of view synthesis and 3D vision.
ViDAR: Video Diffusion-Aware 4D Reconstruction From Monocular Inputs
Jun 23, 2025

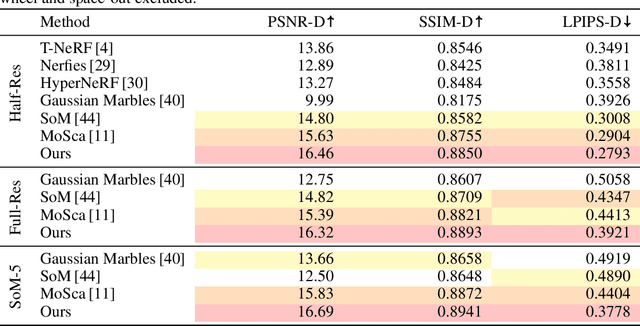

Dynamic Novel View Synthesis aims to generate photorealistic views of moving subjects from arbitrary viewpoints. This task is particularly challenging when relying on monocular video, where disentangling structure from motion is ill-posed and supervision is scarce. We introduce Video Diffusion-Aware Reconstruction (ViDAR), a novel 4D reconstruction framework that leverages personalised diffusion models to synthesise a pseudo multi-view supervision signal for training a Gaussian splatting representation. By conditioning on scene-specific features, ViDAR recovers fine-grained appearance details while mitigating artefacts introduced by monocular ambiguity. To address the spatio-temporal inconsistency of diffusion-based supervision, we propose a diffusion-aware loss function and a camera pose optimisation strategy that aligns synthetic views with the underlying scene geometry. Experiments on DyCheck, a challenging benchmark with extreme viewpoint variation, show that ViDAR outperforms all state-of-the-art baselines in visual quality and geometric consistency. We further highlight ViDAR's strong improvement over baselines on dynamic regions and provide a new benchmark to compare performance in reconstructing motion-rich parts of the scene. Project page: https://vidar-4d.github.io
MuBlE: MuJoCo and Blender simulation Environment and Benchmark for Task Planning in Robot Manipulation
Mar 04, 2025Current embodied reasoning agents struggle to plan for long-horizon tasks that require to physically interact with the world to obtain the necessary information (e.g. 'sort the objects from lightest to heaviest'). The improvement of the capabilities of such an agent is highly dependent on the availability of relevant training environments. In order to facilitate the development of such systems, we introduce a novel simulation environment (built on top of robosuite) that makes use of the MuJoCo physics engine and high-quality renderer Blender to provide realistic visual observations that are also accurate to the physical state of the scene. It is the first simulator focusing on long-horizon robot manipulation tasks preserving accurate physics modeling. MuBlE can generate mutlimodal data for training and enable design of closed-loop methods through environment interaction on two levels: visual - action loop, and control - physics loop. Together with the simulator, we propose SHOP-VRB2, a new benchmark composed of 10 classes of multi-step reasoning scenarios that require simultaneous visual and physical measurements.
Closed Loop Interactive Embodied Reasoning for Robot Manipulation
Apr 23, 2024Embodied reasoning systems integrate robotic hardware and cognitive processes to perform complex tasks typically in response to a natural language query about a specific physical environment. This usually involves changing the belief about the scene or physically interacting and changing the scene (e.g. 'Sort the objects from lightest to heaviest'). In order to facilitate the development of such systems we introduce a new simulating environment that makes use of MuJoCo physics engine and high-quality renderer Blender to provide realistic visual observations that are also accurate to the physical state of the scene. Together with the simulator we propose a new benchmark composed of 10 classes of multi-step reasoning scenarios that require simultaneous visual and physical measurements. Finally, we develop a new modular Closed Loop Interactive Reasoning (CLIER) approach that takes into account the measurements of non-visual object properties, changes in the scene caused by external disturbances as well as uncertain outcomes of robotic actions. We extensively evaluate our reasoning approach in simulation and in the real world manipulation tasks with a success rate above 76% and 64%, respectively.
SWAGS: Sampling Windows Adaptively for Dynamic 3D Gaussian Splatting
Dec 20, 2023Novel view synthesis has shown rapid progress recently, with methods capable of producing evermore photo-realistic results. 3D Gaussian Splatting has emerged as a particularly promising method, producing high-quality renderings of static scenes and enabling interactive viewing at real-time frame rates. However, it is currently limited to static scenes only. In this work, we extend 3D Gaussian Splatting to reconstruct dynamic scenes. We model the dynamics of a scene using a tunable MLP, which learns the deformation field from a canonical space to a set of 3D Gaussians per frame. To disentangle the static and dynamic parts of the scene, we learn a tuneable parameter for each Gaussian, which weighs the respective MLP parameters to focus attention on the dynamic parts. This improves the model's ability to capture dynamics in scenes with an imbalance of static to dynamic regions. To handle scenes of arbitrary length whilst maintaining high rendering quality, we introduce an adaptive window sampling strategy to partition the sequence into windows based on the amount of movement in the sequence. We train a separate dynamic Gaussian Splatting model for each window, allowing the canonical representation to change, thus enabling the reconstruction of scenes with significant geometric or topological changes. Temporal consistency is enforced using a fine-tuning step with self-supervising consistency loss on randomly sampled novel views. As a result, our method produces high-quality renderings of general dynamic scenes with competitive quantitative performance, which can be viewed in real-time with our dynamic interactive viewer.
Self-supervised HDR Imaging from Motion and Exposure Cues
Mar 23, 2022
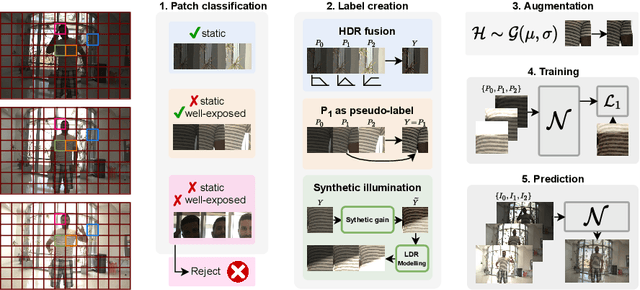
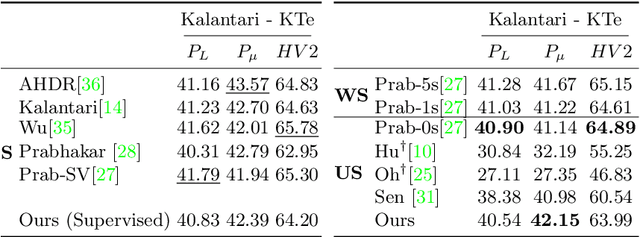
Recent High Dynamic Range (HDR) techniques extend the capabilities of current cameras where scenes with a wide range of illumination can not be accurately captured with a single low-dynamic-range (LDR) image. This is generally accomplished by capturing several LDR images with varying exposure values whose information is then incorporated into a merged HDR image. While such approaches work well for static scenes, dynamic scenes pose several challenges, mostly related to the difficulty of finding reliable pixel correspondences. Data-driven approaches tackle the problem by learning an end-to-end mapping with paired LDR-HDR training data, but in practice generating such HDR ground-truth labels for dynamic scenes is time-consuming and requires complex procedures that assume control of certain dynamic elements of the scene (e.g. actor pose) and repeatable lighting conditions (stop-motion capturing). In this work, we propose a novel self-supervised approach for learnable HDR estimation that alleviates the need for HDR ground-truth labels. We propose to leverage the internal statistics of LDR images to create HDR pseudo-labels. We separately exploit static and well-exposed parts of the input images, which in conjunction with synthetic illumination clipping and motion augmentation provide high quality training examples. Experimental results show that the HDR models trained using our proposed self-supervision approach achieve performance competitive with those trained under full supervision, and are to a large extent superior to previous methods that equally do not require any supervision.
SHOP-VRB: A Visual Reasoning Benchmark for Object Perception
Apr 06, 2020

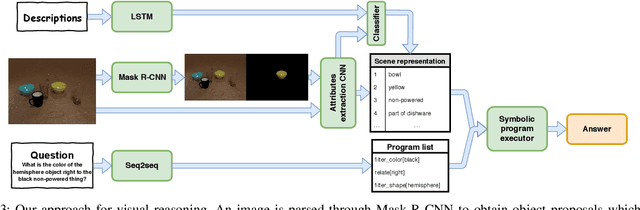
In this paper we present an approach and a benchmark for visual reasoning in robotics applications, in particular small object grasping and manipulation. The approach and benchmark are focused on inferring object properties from visual and text data. It concerns small household objects with their properties, functionality, natural language descriptions as well as question-answer pairs for visual reasoning queries along with their corresponding scene semantic representations. We also present a method for generating synthetic data which allows to extend the benchmark to other objects or scenes and propose an evaluation protocol that is more challenging than in the existing datasets. We propose a reasoning system based on symbolic program execution. A disentangled representation of the visual and textual inputs is obtained and used to execute symbolic programs that represent a 'reasoning process' of the algorithm. We perform a set of experiments on the proposed benchmark and compare to results for the state of the art methods. These results expose the shortcomings of the existing benchmarks that may lead to misleading conclusions on the actual performance of the visual reasoning systems.