 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoGUENeRF: A Robust Geometry-Consistent Universal Enhancer for NeRF
Mar 18, 2024
Recent advances in neural rendering have enabled highly photorealistic 3D scene reconstruction and novel view synthesis. Despite this progress, current state-of-the-art methods struggle to reconstruct high frequency detail, due to factors such as a low-frequency bias of radiance fields and inaccurate camera calibration. One approach to mitigate this issue is to enhance images post-rendering. 2D enhancers can be pre-trained to recover some detail but are agnostic to scene geometry and do not easily generalize to new distributions of image degradation. Conversely, existing 3D enhancers are able to transfer detail from nearby training images in a generalizable manner, but suffer from inaccurate camera calibration and can propagate errors from the geometry into rendered images. We propose a neural rendering enhancer, RoGUENeRF, which exploits the best of both paradigms. Our method is pre-trained to learn a general enhancer while also leveraging information from nearby training images via robust 3D alignment and geometry-aware fusion. Our approach restores high-frequency textures while maintaining geometric consistency and is also robust to inaccurate camera calibration. We show that RoGUENeRF substantially enhances the rendering quality of a wide range of neural rendering baselines, e.g. improving the PSNR of MipNeRF360 by 0.63dB and Nerfacto by 1.34dB on the real world 360v2 dataset.
Deformable 3D Gaussian Splatting for Animatable Human Avatars
Dec 22, 2023



Recent advances in neural radiance fields enable novel view synthesis of photo-realistic images in dynamic settings, which can be applied to scenarios with human animation. Commonly used implicit backbones to establish accurate models, however, require many input views and additional annotations such as human masks, UV maps and depth maps. In this work, we propose ParDy-Human (Parameterized Dynamic Human Avatar), a fully explicit approach to construct a digital avatar from as little as a single monocular sequence. ParDy-Human introduces parameter-driven dynamics into 3D Gaussian Splatting where 3D Gaussians are deformed by a human pose model to animate the avatar. Our method is composed of two parts: A first module that deforms canonical 3D Gaussians according to SMPL vertices and a consecutive module that further takes their designed joint encodings and predicts per Gaussian deformations to deal with dynamics beyond SMPL vertex deformations. Images are then synthesized by a rasterizer. ParDy-Human constitutes an explicit model for realistic dynamic human avatars which requires significantly fewer training views and images. Our avatars learning is free of additional annotations such as masks and can be trained with variable backgrounds while inferring full-resolution images efficiently even on consumer hardware. We provide experimental evidence to show that ParDy-Human outperforms state-of-the-art methods on ZJU-MoCap and THUman4.0 datasets both quantitatively and visually.
SWAGS: Sampling Windows Adaptively for Dynamic 3D Gaussian Splatting
Dec 20, 2023Novel view synthesis has shown rapid progress recently, with methods capable of producing evermore photo-realistic results. 3D Gaussian Splatting has emerged as a particularly promising method, producing high-quality renderings of static scenes and enabling interactive viewing at real-time frame rates. However, it is currently limited to static scenes only. In this work, we extend 3D Gaussian Splatting to reconstruct dynamic scenes. We model the dynamics of a scene using a tunable MLP, which learns the deformation field from a canonical space to a set of 3D Gaussians per frame. To disentangle the static and dynamic parts of the scene, we learn a tuneable parameter for each Gaussian, which weighs the respective MLP parameters to focus attention on the dynamic parts. This improves the model's ability to capture dynamics in scenes with an imbalance of static to dynamic regions. To handle scenes of arbitrary length whilst maintaining high rendering quality, we introduce an adaptive window sampling strategy to partition the sequence into windows based on the amount of movement in the sequence. We train a separate dynamic Gaussian Splatting model for each window, allowing the canonical representation to change, thus enabling the reconstruction of scenes with significant geometric or topological changes. Temporal consistency is enforced using a fine-tuning step with self-supervising consistency loss on randomly sampled novel views. As a result, our method produces high-quality renderings of general dynamic scenes with competitive quantitative performance, which can be viewed in real-time with our dynamic interactive viewer.
HDR Reconstruction from Bracketed Exposures and Events
Mar 28, 2022
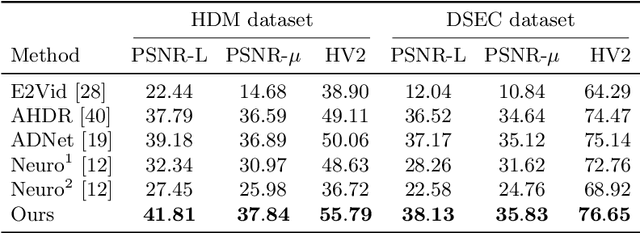
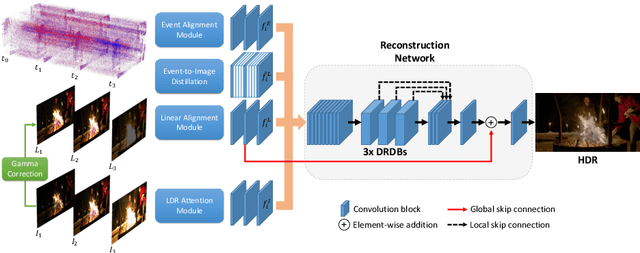
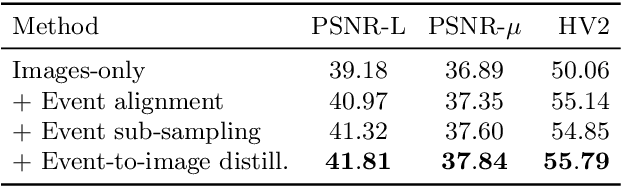
Reconstruction of high-quality HDR images is at the core of modern computational photography. Significant progress has been made with multi-frame HDR reconstruction methods, producing high-resolution, rich and accurate color reconstructions with high-frequency details. However, they are still prone to fail in dynamic or largely over-exposed scenes, where frame misalignment often results in visible ghosting artifacts. Recent approaches attempt to alleviate this by utilizing an event-based camera (EBC), which measures only binary changes of illuminations. Despite their desirable high temporal resolution and dynamic range characteristics, such approaches have not outperformed traditional multi-frame reconstruction methods, mainly due to the lack of color information and low-resolution sensors. In this paper, we propose to leverage both bracketed LDR images and simultaneously captured events to obtain the best of both worlds: high-quality RGB information from bracketed LDRs and complementary high frequency and dynamic range information from events. We present a multi-modal end-to-end learning-based HDR imaging system that fuses bracketed images and event modalities in the feature domain using attention and multi-scale spatial alignment modules. We propose a novel event-to-image feature distillation module that learns to translate event features into the image-feature space with self-supervision. Our framework exploits the higher temporal resolution of events by sub-sampling the input event streams using a sliding window, enriching our combined feature representation. Our proposed approach surpasses SoTA multi-frame HDR reconstruction methods using synthetic and real events, with a 2dB and 1dB improvement in PSNR-L and PSNR-mu on the HdM HDR dataset, respectively.