 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCRF: Neural Contact Radiance Fields for Free-Viewpoint Rendering of Hand-Object Interaction
Feb 09, 2024Modeling hand-object interactions is a fundamentally challenging task in 3D computer vision. Despite remarkable progress that has been achieved in this field, existing methods still fail to synthesize the hand-object interaction photo-realistically, suffering from degraded rendering quality caused by the heavy mutual occlusions between the hand and the object, and inaccurate hand-object pose estimation. To tackle these challenges, we present a novel free-viewpoint rendering framework, Neural Contact Radiance Field (NCRF), to reconstruct hand-object interactions from a sparse set of videos. In particular, the proposed NCRF framework consists of two key components: (a) A contact optimization field that predicts an accurate contact field from 3D query points for achieving desirable contact between the hand and the object. (b) A hand-object neural radiance field to learn an implicit hand-object representation in a static canonical space, in concert with the specifically designed hand-object motion field to produce observation-to-canonical correspondences. We jointly learn these key components where they mutually help and regularize each other with visual and geometric constraints, producing a high-quality hand-object reconstruction that achieves photo-realistic novel view synthesis. Extensive experiments on HO3D and DexYCB datasets show that our approach outperforms the current state-of-the-art in terms of both rendering quality and pose estimation accuracy.
Deformable 3D Gaussian Splatting for Animatable Human Avatars
Dec 22, 2023



Recent advances in neural radiance fields enable novel view synthesis of photo-realistic images in dynamic settings, which can be applied to scenarios with human animation. Commonly used implicit backbones to establish accurate models, however, require many input views and additional annotations such as human masks, UV maps and depth maps. In this work, we propose ParDy-Human (Parameterized Dynamic Human Avatar), a fully explicit approach to construct a digital avatar from as little as a single monocular sequence. ParDy-Human introduces parameter-driven dynamics into 3D Gaussian Splatting where 3D Gaussians are deformed by a human pose model to animate the avatar. Our method is composed of two parts: A first module that deforms canonical 3D Gaussians according to SMPL vertices and a consecutive module that further takes their designed joint encodings and predicts per Gaussian deformations to deal with dynamics beyond SMPL vertex deformations. Images are then synthesized by a rasterizer. ParDy-Human constitutes an explicit model for realistic dynamic human avatars which requires significantly fewer training views and images. Our avatars learning is free of additional annotations such as masks and can be trained with variable backgrounds while inferring full-resolution images efficiently even on consumer hardware. We provide experimental evidence to show that ParDy-Human outperforms state-of-the-art methods on ZJU-MoCap and THUman4.0 datasets both quantitatively and visually.
Reality's Canvas, Language's Brush: Crafting 3D Avatars from Monocular Video
Dec 08, 2023



Recent advancements in 3D avatar generation excel with multi-view supervision for photorealistic models. However, monocular counterparts lag in quality despite broader applicability. We propose ReCaLab to close this gap. ReCaLab is a fully-differentiable pipeline that learns high-fidelity 3D human avatars from just a single RGB video. A pose-conditioned deformable NeRF is optimized to volumetrically represent a human subject in canonical T-pose. The canonical representation is then leveraged to efficiently associate viewpoint-agnostic textures using 2D-3D correspondences. This enables to separately generate albedo and shading which jointly compose an RGB prediction. The design allows to control intermediate results for human pose, body shape, texture, and lighting with text prompts. An image-conditioned diffusion model thereby helps to animate appearance and pose of the 3D avatar to create video sequences with previously unseen human motion. Extensive experiments show that ReCaLab outperforms previous monocular approaches in terms of image quality for image synthesis tasks. ReCaLab even outperforms multi-view methods that leverage up to 19x more synchronized videos for the task of novel pose rendering. Moreover, natural language offers an intuitive user interface for creative manipulation of 3D human avatars.
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
Dec 05, 2023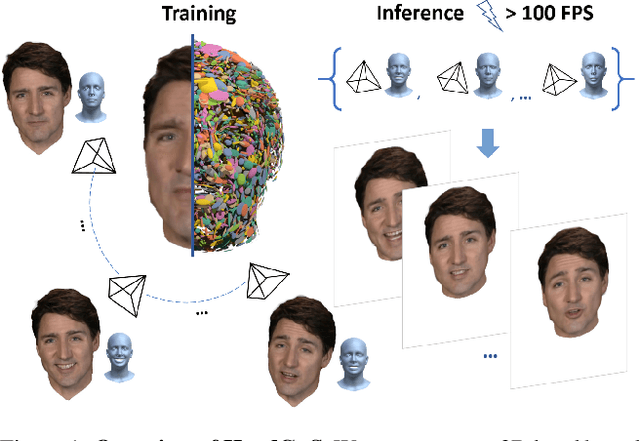
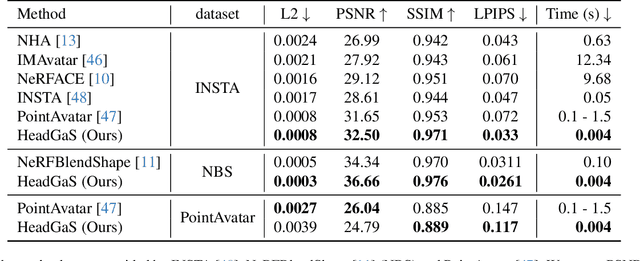
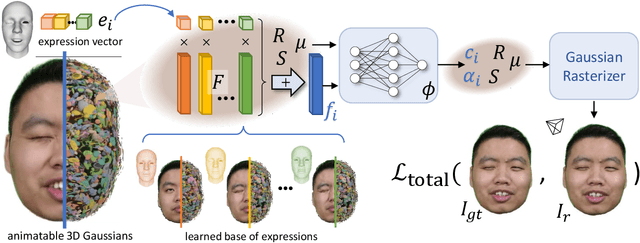
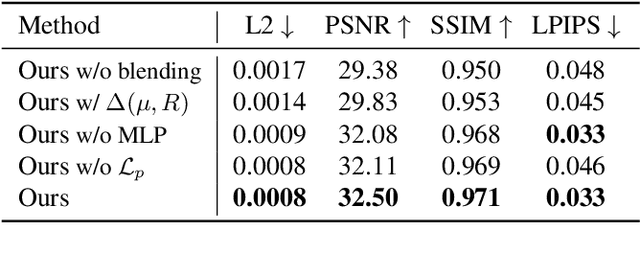
3D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, the first model to use 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit representation from 3DGS with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent final color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, which surpasses baselines by up to ~2dB, while accelerating rendering speed by over x10.
Human Gaussian Splatting: Real-time Rendering of Animatable Avatars
Nov 28, 2023



This work addresses the problem of real-time rendering of photorealistic human body avatars learned from multi-view videos. While the classical approaches to model and render virtual humans generally use a textured mesh, recent research has developed neural body representations that achieve impressive visual quality. However, these models are difficult to render in real-time and their quality degrades when the character is animated with body poses different than the training observations. We propose the first animatable human model based on 3D Gaussian Splatting, that has recently emerged as a very efficient alternative to neural radiance fields. Our body is represented by a set of gaussian primitives in a canonical space which are deformed in a coarse to fine approach that combines forward skinning and local non-rigid refinement. We describe how to learn our Human Gaussian Splatting (\OURS) model in an end-to-end fashion from multi-view observations, and evaluate it against the state-of-the-art approaches for novel pose synthesis of clothed body. Our method presents a PSNR 1.5dbB better than the state-of-the-art on THuman4 dataset while being able to render at 20fps or more.
On the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
Mar 26, 2023



Learning-based methods to solve dense 3D vision problems typically train on 3D sensor data. The respectively used principle of measuring distances provides advantages and drawbacks. These are typically not compared nor discussed in the literature due to a lack of multi-modal datasets. Texture-less regions are problematic for structure from motion and stereo, reflective material poses issues for active sensing, and distances for translucent objects are intricate to measure with existing hardware. Training on inaccurate or corrupt data induces model bias and hampers generalisation capabilities. These effects remain unnoticed if the sensor measurement is considered as ground truth during the evaluation. This paper investigates the effect of sensor errors for the dense 3D vision tasks of depth estimation and reconstruction. We rigorously show the significant impact of sensor characteristics on the learned predictions and notice generalisation issues arising from various technologies in everyday household environments. For evaluation, we introduce a carefully designed dataset\footnote{dataset available at https://github.com/Junggy/HAMMER-dataset} comprising measurements from commodity sensors, namely D-ToF, I-ToF, passive/active stereo, and monocular RGB+P. Our study quantifies the considerable sensor noise impact and paves the way to improved dense vision estimates and targeted data fusion.
Disentangling 3D Attributes from a Single 2D Image: Human Pose, Shape and Garment
Aug 05, 2022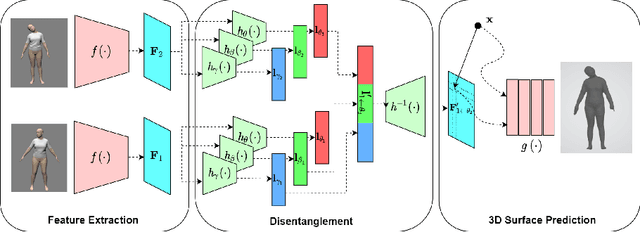

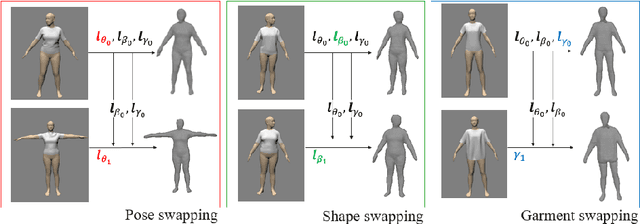
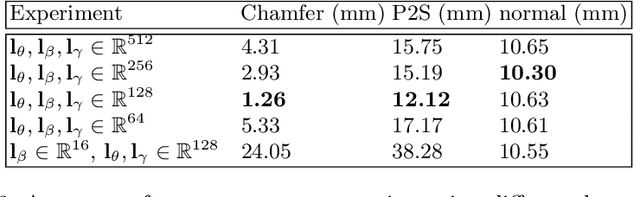
For visual manipulation tasks, we aim to represent image content with semantically meaningful features. However, learning implicit representations from images often lacks interpretability, especially when attributes are intertwined. We focus on the challenging task of extracting disentangled 3D attributes only from 2D image data. Specifically, we focus on human appearance and learn implicit pose, shape and garment representations of dressed humans from RGB images. Our method learns an embedding with disentangled latent representations of these three image properties and enables meaningful re-assembling of features and property control through a 2D-to-3D encoder-decoder structure. The 3D model is inferred solely from the feature map in the learned embedding space. To the best of our knowledge, our method is the first to achieve cross-domain disentanglement for this highly under-constrained problem. We qualitatively and quantitatively demonstrate our framework's ability to transfer pose, shape, and garments in 3D reconstruction on virtual data and show how an implicit shape loss can benefit the model's ability to recover fine-grained reconstruction details.
Is my Depth Ground-Truth Good Enough? HAMMER -- Highly Accurate Multi-Modal Dataset for DEnse 3D Scene Regression
May 09, 2022


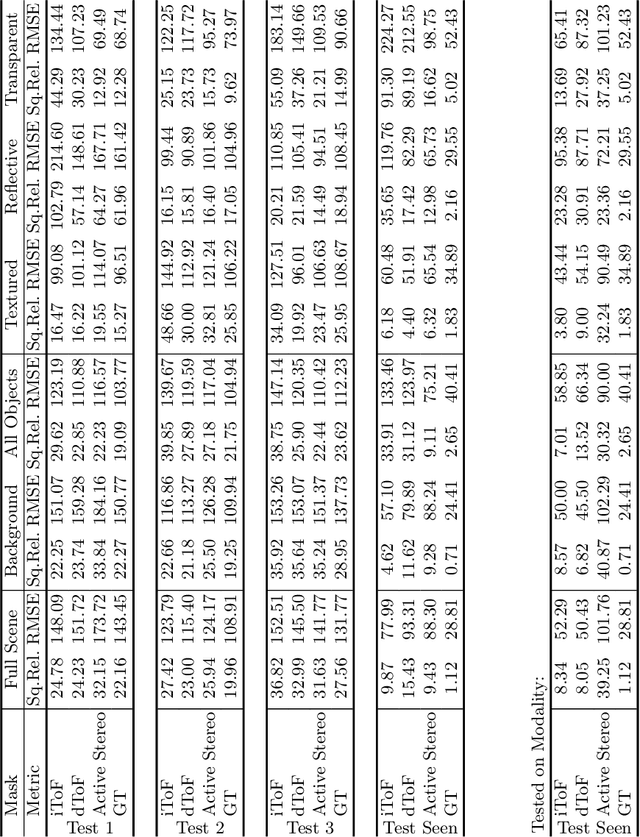
Depth estimation is a core task in 3D computer vision. Recent methods investigate the task of monocular depth trained with various depth sensor modalities. Every sensor has its advantages and drawbacks caused by the nature of estimates. In the literature, mostly mean average error of the depth is investigated and sensor capabilities are typically not discussed. Especially indoor environments, however, pose challenges for some devices. Textureless regions pose challenges for structure from motion, reflective materials are problematic for active sensing, and distances for translucent material are intricate to measure with existing sensors. This paper proposes HAMMER, a dataset comprising depth estimates from multiple commonly used sensors for indoor depth estimation, namely ToF, stereo, structured light together with monocular RGB+P data. We construct highly reliable ground truth depth maps with the help of 3D scanners and aligned renderings. A popular depth estimators is trained on this data and typical depth senosors. The estimates are extensively analyze on different scene structures. We notice generalization issues arising from various sensor technologies in household environments with challenging but everyday scene content. HAMMER, which we make publicly available, provides a reliable base to pave the way to targeted depth improvements and sensor fusion approaches.
Adaptive Quantization for Deep Neural Network
Dec 04, 2017
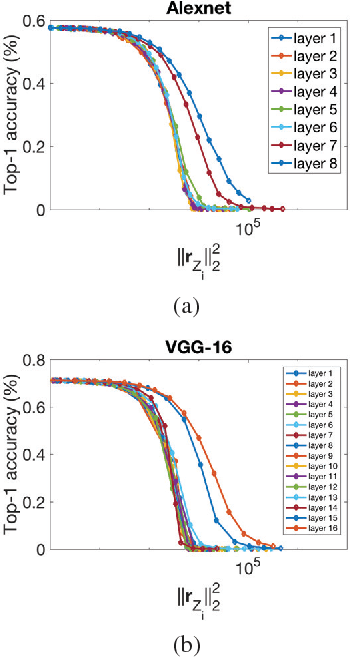

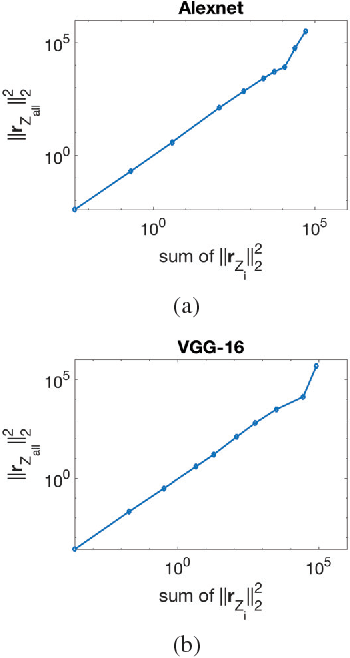
In recent years Deep Neural Networks (DNNs) have been rapidly developed in various applications, together with increasingly complex architectures. The performance gain of these DNNs generally comes with high computational costs and large memory consumption, which may not be affordable for mobile platforms. Deep model quantization can be used for reducing the computation and memory costs of DNNs, and deploying complex DNNs on mobile equipment. In this work, we propose an optimization framework for deep model quantization. First, we propose a measurement to estimate the effect of parameter quantization errors in individual layers on the overall model prediction accuracy. Then, we propose an optimization process based on this measurement for finding optimal quantization bit-width for each layer. This is the first work that theoretically analyse the relationship between parameter quantization errors of individual layers and model accuracy. Our new quantization algorithm outperforms previous quantization optimization methods, and achieves 20-40% higher compression rate compared to equal bit-width quantization at the same model prediction accuracy.
On Classification of Distorted Images with Deep Convolutional Neural Networks
Jan 08, 2017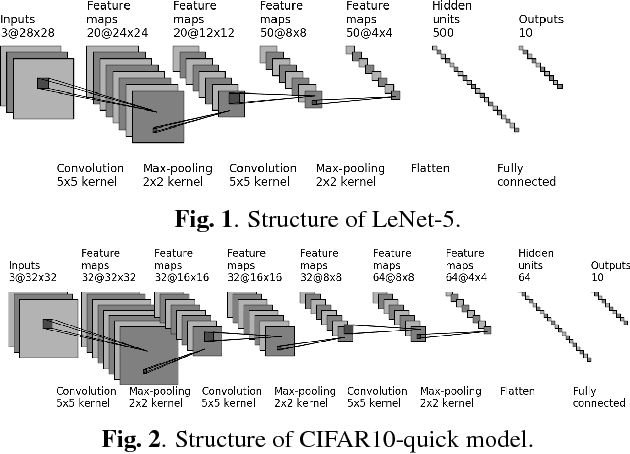
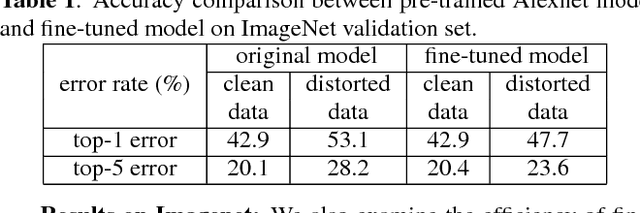


Image blur and image noise are common distortions during image acquisition. In this paper, we systematically study the effect of image distortions on the deep neural network (DNN) image classifiers. First, we examine the DNN classifier performance under four types of distortions. Second, we propose two approaches to alleviate the effect of image distortion: re-training and fine-tuning with noisy images. Our results suggest that, under certain conditions, fine-tuning with noisy images can alleviate much effect due to distorted inputs, and is more practical than re-training.