 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTGaze: Real-Time 3D-Aware Gaze Redirection from a Single Image
Nov 14, 2025Gaze redirection methods aim to generate realistic human face images with controllable eye movement. However, recent methods often struggle with 3D consistency, efficiency, or quality, limiting their practical applications. In this work, we propose RTGaze, a real-time and high-quality gaze redirection method. Our approach learns a gaze-controllable facial representation from face images and gaze prompts, then decodes this representation via neural rendering for gaze redirection. Additionally, we distill face geometric priors from a pretrained 3D portrait generator to enhance generation quality. We evaluate RTGaze both qualitatively and quantitatively, demonstrating state-of-the-art performance in efficiency, redirection accuracy, and image quality across multiple datasets. Our system achieves real-time, 3D-aware gaze redirection with a feedforward network (~0.06 sec/image), making it 800x faster than the previous state-of-the-art 3D-aware methods.
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
Feb 06, 20253D and 2D gaze estimation share the fundamental objective of capturing eye movements but are traditionally treated as two distinct research domains. In this paper, we introduce a novel cross-task few-shot 2D gaze estimation approach, aiming to adapt a pre-trained 3D gaze estimation network for 2D gaze prediction on unseen devices using only a few training images. This task is highly challenging due to the domain gap between 3D and 2D gaze, unknown screen poses, and limited training data. To address these challenges, we propose a novel framework that bridges the gap between 3D and 2D gaze. Our framework contains a physics-based differentiable projection module with learnable parameters to model screen poses and project 3D gaze into 2D gaze. The framework is fully differentiable and can integrate into existing 3D gaze networks without modifying their original architecture. Additionally, we introduce a dynamic pseudo-labelling strategy for flipped images, which is particularly challenging for 2D labels due to unknown screen poses. To overcome this, we reverse the projection process by converting 2D labels to 3D space, where flipping is performed. Notably, this 3D space is not aligned with the camera coordinate system, so we learn a dynamic transformation matrix to compensate for this misalignment. We evaluate our method on MPIIGaze, EVE, and GazeCapture datasets, collected respectively on laptops, desktop computers, and mobile devices. The superior performance highlights the effectiveness of our approach, and demonstrates its strong potential for real-world applications.
NL2Contact: Natural Language Guided 3D Hand-Object Contact Modeling with Diffusion Model
Jul 17, 2024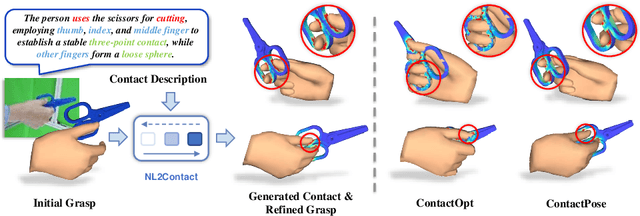
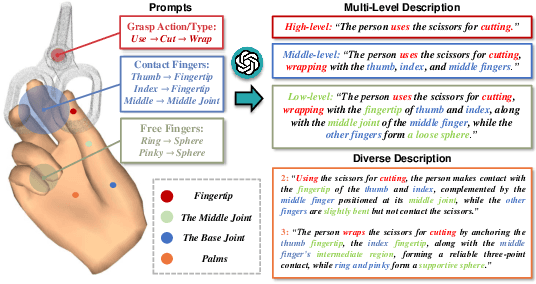

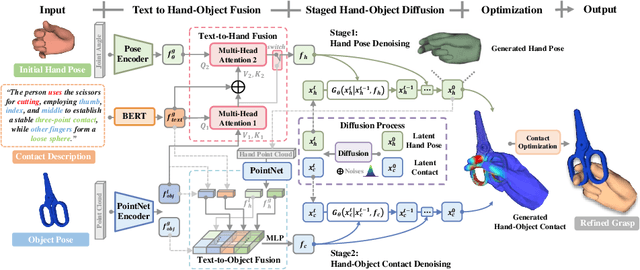
Modeling the physical contacts between the hand and object is standard for refining inaccurate hand poses and generating novel human grasp in 3D hand-object reconstruction. However, existing methods rely on geometric constraints that cannot be specified or controlled. This paper introduces a novel task of controllable 3D hand-object contact modeling with natural language descriptions. Challenges include i) the complexity of cross-modal modeling from language to contact, and ii) a lack of descriptive text for contact patterns. To address these issues, we propose NL2Contact, a model that generates controllable contacts by leveraging staged diffusion models. Given a language description of the hand and contact, NL2Contact generates realistic and faithful 3D hand-object contacts. To train the model, we build \textit{ContactDescribe}, the first dataset with hand-centered contact descriptions. It contains multi-level and diverse descriptions generated by large language models based on carefully designed prompts (e.g., grasp action, grasp type, contact location, free finger status). We show applications of our model to grasp pose optimization and novel human grasp generation, both based on a textual contact description.
TextGaze: Gaze-Controllable Face Generation with Natural Language
Apr 26, 2024



Generating face image with specific gaze information has attracted considerable attention. Existing approaches typically input gaze values directly for face generation, which is unnatural and requires annotated gaze datasets for training, thereby limiting its application. In this paper, we present a novel gaze-controllable face generation task. Our approach inputs textual descriptions that describe human gaze and head behavior and generates corresponding face images. Our work first introduces a text-of-gaze dataset containing over 90k text descriptions spanning a dense distribution of gaze and head poses. We further propose a gaze-controllable text-to-face method. Our method contains a sketch-conditioned face diffusion module and a model-based sketch diffusion module. We define a face sketch based on facial landmarks and eye segmentation map. The face diffusion module generates face images from the face sketch, and the sketch diffusion module employs a 3D face model to generate face sketch from text description. Experiments on the FFHQ dataset show the effectiveness of our method. We will release our dataset and code for future research.
NCRF: Neural Contact Radiance Fields for Free-Viewpoint Rendering of Hand-Object Interaction
Feb 09, 2024Modeling hand-object interactions is a fundamentally challenging task in 3D computer vision. Despite remarkable progress that has been achieved in this field, existing methods still fail to synthesize the hand-object interaction photo-realistically, suffering from degraded rendering quality caused by the heavy mutual occlusions between the hand and the object, and inaccurate hand-object pose estimation. To tackle these challenges, we present a novel free-viewpoint rendering framework, Neural Contact Radiance Field (NCRF), to reconstruct hand-object interactions from a sparse set of videos. In particular, the proposed NCRF framework consists of two key components: (a) A contact optimization field that predicts an accurate contact field from 3D query points for achieving desirable contact between the hand and the object. (b) A hand-object neural radiance field to learn an implicit hand-object representation in a static canonical space, in concert with the specifically designed hand-object motion field to produce observation-to-canonical correspondences. We jointly learn these key components where they mutually help and regularize each other with visual and geometric constraints, producing a high-quality hand-object reconstruction that achieves photo-realistic novel view synthesis. Extensive experiments on HO3D and DexYCB datasets show that our approach outperforms the current state-of-the-art in terms of both rendering quality and pose estimation accuracy.
Multi-Modal Gaze Following in Conversational Scenarios
Nov 09, 2023Gaze following estimates gaze targets of in-scene person by understanding human behavior and scene information. Existing methods usually analyze scene images for gaze following. However, compared with visual images, audio also provides crucial cues for determining human behavior.This suggests that we can further improve gaze following considering audio cues. In this paper, we explore gaze following tasks in conversational scenarios. We propose a novel multi-modal gaze following framework based on our observation ``audiences tend to focus on the speaker''. We first leverage the correlation between audio and lips, and classify speakers and listeners in a scene. We then use the identity information to enhance scene images and propose a gaze candidate estimation network. The network estimates gaze candidates from enhanced scene images and we use MLP to match subjects with candidates as classification tasks. Existing gaze following datasets focus on visual images while ignore audios.To evaluate our method, we collect a conversational dataset, VideoGazeSpeech (VGS), which is the first gaze following dataset including images and audio. Our method significantly outperforms existing methods in VGS datasets. The visualization result also prove the advantage of audio cues in gaze following tasks. Our work will inspire more researches in multi-modal gaze following estimation.
High-Fidelity Eye Animatable Neural Radiance Fields for Human Face
Aug 22, 2023Face rendering using neural radiance fields (NeRF) is a rapidly developing research area in computer vision. While recent methods primarily focus on controlling facial attributes such as identity and expression, they often overlook the crucial aspect of modeling eyeball rotation, which holds importance for various downstream tasks. In this paper, we aim to learn a face NeRF model that is sensitive to eye movements from multi-view images. We address two key challenges in eye-aware face NeRF learning: how to effectively capture eyeball rotation for training and how to construct a manifold for representing eyeball rotation. To accomplish this, we first fit FLAME, a well-established parametric face model, to the multi-view images considering multi-view consistency. Subsequently, we introduce a new Dynamic Eye-aware NeRF (DeNeRF). DeNeRF transforms 3D points from different views into a canonical space to learn a unified face NeRF model. We design an eye deformation field for the transformation, including rigid transformation, e.g., eyeball rotation, and non-rigid transformation. Through experiments conducted on the ETH-XGaze dataset, we demonstrate that our model is capable of generating high-fidelity images with accurate eyeball rotation and non-rigid periocular deformation, even under novel viewing angles. Furthermore, we show that utilizing the rendered images can effectively enhance gaze estimation performance.
Category-Level 6D Object Pose Estimation with Flexible Vector-Based Rotation Representation
Dec 09, 2022



In this paper, we propose a novel 3D graph convolution based pipeline for category-level 6D pose and size estimation from monocular RGB-D images. The proposed method leverages an efficient 3D data augmentation and a novel vector-based decoupled rotation representation. Specifically, we first design an orientation-aware autoencoder with 3D graph convolution for latent feature learning. The learned latent feature is insensitive to point shift and size thanks to the shift and scale-invariance properties of the 3D graph convolution. Then, to efficiently decode the rotation information from the latent feature, we design a novel flexible vector-based decomposable rotation representation that employs two decoders to complementarily access the rotation information. The proposed rotation representation has two major advantages: 1) decoupled characteristic that makes the rotation estimation easier; 2) flexible length and rotated angle of the vectors allow us to find a more suitable vector representation for specific pose estimation task. Finally, we propose a 3D deformation mechanism to increase the generalization ability of the pipeline. Extensive experiments show that the proposed pipeline achieves state-of-the-art performance on category-level tasks. Further, the experiments demonstrate that the proposed rotation representation is more suitable for the pose estimation tasks than other rotation representations.
S$^2$Contact: Graph-based Network for 3D Hand-Object Contact Estimation with Semi-Supervised Learning
Aug 01, 2022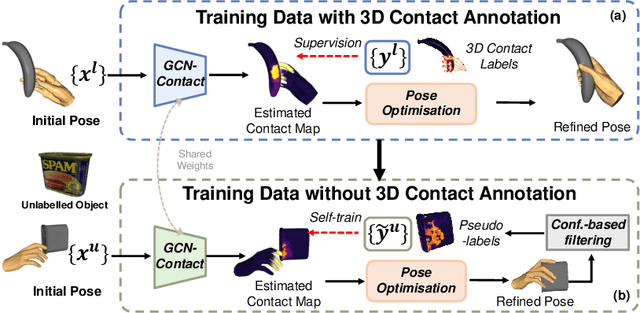
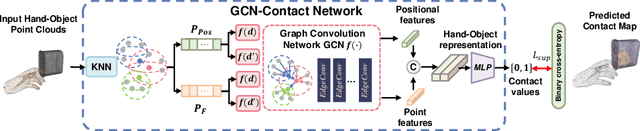
Despite the recent efforts in accurate 3D annotations in hand and object datasets, there still exist gaps in 3D hand and object reconstructions. Existing works leverage contact maps to refine inaccurate hand-object pose estimations and generate grasps given object models. However, they require explicit 3D supervision which is seldom available and therefore, are limited to constrained settings, e.g., where thermal cameras observe residual heat left on manipulated objects. In this paper, we propose a novel semi-supervised framework that allows us to learn contact from monocular images. Specifically, we leverage visual and geometric consistency constraints in large-scale datasets for generating pseudo-labels in semi-supervised learning and propose an efficient graph-based network to infer contact. Our semi-supervised learning framework achieves a favourable improvement over the existing supervised learning methods trained on data with `limited' annotations. Notably, our proposed model is able to achieve superior results with less than half the network parameters and memory access cost when compared with the commonly-used PointNet-based approach. We show benefits from using a contact map that rules hand-object interactions to produce more accurate reconstructions. We further demonstrate that training with pseudo-labels can extend contact map estimations to out-of-domain objects and generalise better across multiple datasets.