 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human Motion Plausibility with Body Momentum
Sep 11, 2025Many studies decompose human motion into local motion in a frame attached to the root joint and global motion of the root joint in the world frame, treating them separately. However, these two components are not independent. Global movement arises from interactions with the environment, which are, in turn, driven by changes in the body configuration. Motion models often fail to precisely capture this physical coupling between local and global dynamics, while deriving global trajectories from joint torques and external forces is computationally expensive and complex. To address these challenges, we propose using whole-body linear and angular momentum as a constraint to link local motion with global movement. Since momentum reflects the aggregate effect of joint-level dynamics on the body's movement through space, it provides a physically grounded way to relate local joint behavior to global displacement. Building on this insight, we introduce a new loss term that enforces consistency between the generated momentum profiles and those observed in ground-truth data. Incorporating our loss reduces foot sliding and jitter, improves balance, and preserves the accuracy of the recovered motion. Code and data are available at the project page https://hlinhn.github.io/momentum_bmvc.
Visual Intention Grounding for Egocentric Assistants
Apr 18, 2025Visual grounding associates textual descriptions with objects in an image. Conventional methods target third-person image inputs and named object queries. In applications such as AI assistants, the perspective shifts -- inputs are egocentric, and objects may be referred to implicitly through needs and intentions. To bridge this gap, we introduce EgoIntention, the first dataset for egocentric visual intention grounding. EgoIntention challenges multimodal LLMs to 1) understand and ignore unintended contextual objects and 2) reason about uncommon object functionalities. Benchmark results show that current models misidentify context objects and lack affordance understanding in egocentric views. We also propose Reason-to-Ground (RoG) instruction tuning; it enables hybrid training with normal descriptions and egocentric intentions with a chained intention reasoning and object grounding mechanism. RoG significantly outperforms naive finetuning and hybrid training on EgoIntention, while maintaining or slightly improving naive description grounding. This advancement enables unified visual grounding for egocentric and exocentric visual inputs while handling explicit object queries and implicit human intentions.
Collaborative Learning for 3D Hand-Object Reconstruction and Compositional Action Recognition from Egocentric RGB Videos Using Superquadrics
Jan 13, 2025

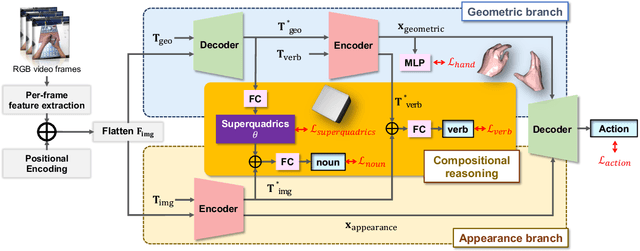

With the availability of egocentric 3D hand-object interaction datasets, there is increasing interest in developing unified models for hand-object pose estimation and action recognition. However, existing methods still struggle to recognise seen actions on unseen objects due to the limitations in representing object shape and movement using 3D bounding boxes. Additionally, the reliance on object templates at test time limits their generalisability to unseen objects. To address these challenges, we propose to leverage superquadrics as an alternative 3D object representation to bounding boxes and demonstrate their effectiveness on both template-free object reconstruction and action recognition tasks. Moreover, as we find that pure appearance-based methods can outperform the unified methods, the potential benefits from 3D geometric information remain unclear. Therefore, we study the compositionality of actions by considering a more challenging task where the training combinations of verbs and nouns do not overlap with the testing split. We extend H2O and FPHA datasets with compositional splits and design a novel collaborative learning framework that can explicitly reason about the geometric relations between hands and the manipulated object. Through extensive quantitative and qualitative evaluations, we demonstrate significant improvements over the state-of-the-arts in (compositional) action recognition.
DAS3R: Dynamics-Aware Gaussian Splatting for Static Scene Reconstruction
Dec 27, 2024We propose a novel framework for scene decomposition and static background reconstruction from everyday videos. By integrating the trained motion masks and modeling the static scene as Gaussian splats with dynamics-aware optimization, our method achieves more accurate background reconstruction results than previous works. Our proposed method is termed DAS3R, an abbreviation for Dynamics-Aware Gaussian Splatting for Static Scene Reconstruction. Compared to existing methods, DAS3R is more robust in complex motion scenarios, capable of handling videos where dynamic objects occupy a significant portion of the scene, and does not require camera pose inputs or point cloud data from SLAM-based methods. We compared DAS3R against recent distractor-free approaches on the DAVIS and Sintel datasets; DAS3R demonstrates enhanced performance and robustness with a margin of more than 2 dB in PSNR. The project's webpage can be accessed via \url{https://kai422.github.io/DAS3R/}
SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain
May 28, 2024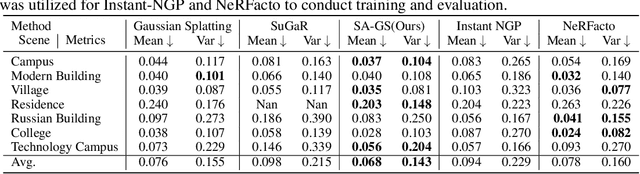
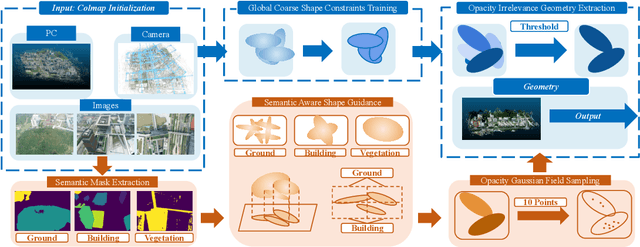
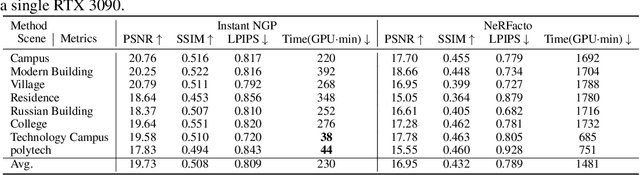

With the emergence of Gaussian Splats, recent efforts have focused on large-scale scene geometric reconstruction. However, most of these efforts either concentrate on memory reduction or spatial space division, neglecting information in the semantic space. In this paper, we propose a novel method, named SA-GS, for fine-grained 3D geometry reconstruction using semantic-aware 3D Gaussian Splats. Specifically, we leverage prior information stored in large vision models such as SAM and DINO to generate semantic masks. We then introduce a geometric complexity measurement function to serve as soft regularization, guiding the shape of each Gaussian Splat within specific semantic areas. Additionally, we present a method that estimates the expected number of Gaussian Splats in different semantic areas, effectively providing a lower bound for Gaussian Splats in these areas. Subsequently, we extract the point cloud using a novel probability density-based extraction method, transforming Gaussian Splats into a point cloud crucial for downstream tasks. Our method also offers the potential for detailed semantic inquiries while maintaining high image-based reconstruction results. We provide extensive experiments on publicly available large-scale scene reconstruction datasets with highly accurate point clouds as ground truth and our novel dataset. Our results demonstrate the superiority of our method over current state-of-the-art Gaussian Splats reconstruction methods by a significant margin in terms of geometric-based measurement metrics. Code and additional results will soon be available on our project page.
GeoReF: Geometric Alignment Across Shape Variation for Category-level Object Pose Refinement
Apr 17, 2024Object pose refinement is essential for robust object pose estimation. Previous work has made significant progress towards instance-level object pose refinement. Yet, category-level pose refinement is a more challenging problem due to large shape variations within a category and the discrepancies between the target object and the shape prior. To address these challenges, we introduce a novel architecture for category-level object pose refinement. Our approach integrates an HS-layer and learnable affine transformations, which aims to enhance the extraction and alignment of geometric information. Additionally, we introduce a cross-cloud transformation mechanism that efficiently merges diverse data sources. Finally, we push the limits of our model by incorporating the shape prior information for translation and size error prediction. We conducted extensive experiments to demonstrate the effectiveness of the proposed framework. Through extensive quantitative experiments, we demonstrate significant improvement over the baseline method by a large margin across all metrics.
Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images
Aug 21, 2023We propose a novel transformer-based framework that reconstructs two high fidelity hands from multi-view RGB images. Unlike existing hand pose estimation methods, where one typically trains a deep network to regress hand model parameters from single RGB image, we consider a more challenging problem setting where we directly regress the absolute root poses of two-hands with extended forearm at high resolution from egocentric view. As existing datasets are either infeasible for egocentric viewpoints or lack background variations, we create a large-scale synthetic dataset with diverse scenarios and collect a real dataset from multi-calibrated camera setup to verify our proposed multi-view image feature fusion strategy. To make the reconstruction physically plausible, we propose two strategies: (i) a coarse-to-fine spectral graph convolution decoder to smoothen the meshes during upsampling and (ii) an optimisation-based refinement stage at inference to prevent self-penetrations. Through extensive quantitative and qualitative evaluations, we show that our framework is able to produce realistic two-hand reconstructions and demonstrate the generalisation of synthetic-trained models to real data, as well as real-time AR/VR applications.
DiffPose: SpatioTemporal Diffusion Model for Video-Based Human Pose Estimation
Aug 05, 2023



Denoising diffusion probabilistic models that were initially proposed for realistic image generation have recently shown success in various perception tasks (e.g., object detection and image segmentation) and are increasingly gaining attention in computer vision. However, extending such models to multi-frame human pose estimation is non-trivial due to the presence of the additional temporal dimension in videos. More importantly, learning representations that focus on keypoint regions is crucial for accurate localization of human joints. Nevertheless, the adaptation of the diffusion-based methods remains unclear on how to achieve such objective. In this paper, we present DiffPose, a novel diffusion architecture that formulates video-based human pose estimation as a conditional heatmap generation problem. First, to better leverage temporal information, we propose SpatioTemporal Representation Learner which aggregates visual evidences across frames and uses the resulting features in each denoising step as a condition. In addition, we present a mechanism called Lookup-based MultiScale Feature Interaction that determines the correlations between local joints and global contexts across multiple scales. This mechanism generates delicate representations that focus on keypoint regions. Altogether, by extending diffusion models, we show two unique characteristics from DiffPose on pose estimation task: (i) the ability to combine multiple sets of pose estimates to improve prediction accuracy, particularly for challenging joints, and (ii) the ability to adjust the number of iterative steps for feature refinement without retraining the model. DiffPose sets new state-of-the-art results on three benchmarks: PoseTrack2017, PoseTrack2018, and PoseTrack21.
Mutual Information-Based Temporal Difference Learning for Human Pose Estimation in Video
Mar 15, 2023



Temporal modeling is crucial for multi-frame human pose estimation. Most existing methods directly employ optical flow or deformable convolution to predict full-spectrum motion fields, which might incur numerous irrelevant cues, such as a nearby person or background. Without further efforts to excavate meaningful motion priors, their results are suboptimal, especially in complicated spatiotemporal interactions. On the other hand, the temporal difference has the ability to encode representative motion information which can potentially be valuable for pose estimation but has not been fully exploited. In this paper, we present a novel multi-frame human pose estimation framework, which employs temporal differences across frames to model dynamic contexts and engages mutual information objectively to facilitate useful motion information disentanglement. To be specific, we design a multi-stage Temporal Difference Encoder that performs incremental cascaded learning conditioned on multi-stage feature difference sequences to derive informative motion representation. We further propose a Representation Disentanglement module from the mutual information perspective, which can grasp discriminative task-relevant motion signals by explicitly defining useful and noisy constituents of the raw motion features and minimizing their mutual information. These place us to rank No.1 in the Crowd Pose Estimation in Complex Events Challenge on benchmark dataset HiEve, and achieve state-of-the-art performance on three benchmarks PoseTrack2017, PoseTrack2018, and PoseTrack21.
S$^2$Contact: Graph-based Network for 3D Hand-Object Contact Estimation with Semi-Supervised Learning
Aug 01, 2022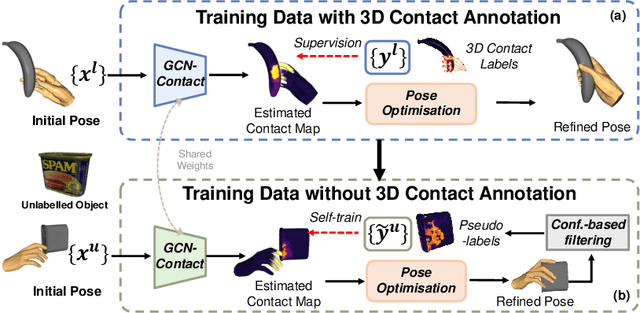
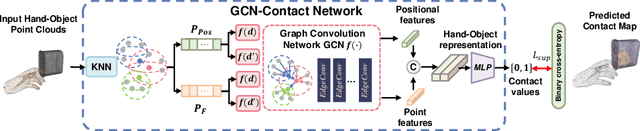
Despite the recent efforts in accurate 3D annotations in hand and object datasets, there still exist gaps in 3D hand and object reconstructions. Existing works leverage contact maps to refine inaccurate hand-object pose estimations and generate grasps given object models. However, they require explicit 3D supervision which is seldom available and therefore, are limited to constrained settings, e.g., where thermal cameras observe residual heat left on manipulated objects. In this paper, we propose a novel semi-supervised framework that allows us to learn contact from monocular images. Specifically, we leverage visual and geometric consistency constraints in large-scale datasets for generating pseudo-labels in semi-supervised learning and propose an efficient graph-based network to infer contact. Our semi-supervised learning framework achieves a favourable improvement over the existing supervised learning methods trained on data with `limited' annotations. Notably, our proposed model is able to achieve superior results with less than half the network parameters and memory access cost when compared with the commonly-used PointNet-based approach. We show benefits from using a contact map that rules hand-object interactions to produce more accurate reconstructions. We further demonstrate that training with pseudo-labels can extend contact map estimations to out-of-domain objects and generalise better across multiple datasets.