 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Intention Grounding for Egocentric Assistants
Apr 18, 2025Visual grounding associates textual descriptions with objects in an image. Conventional methods target third-person image inputs and named object queries. In applications such as AI assistants, the perspective shifts -- inputs are egocentric, and objects may be referred to implicitly through needs and intentions. To bridge this gap, we introduce EgoIntention, the first dataset for egocentric visual intention grounding. EgoIntention challenges multimodal LLMs to 1) understand and ignore unintended contextual objects and 2) reason about uncommon object functionalities. Benchmark results show that current models misidentify context objects and lack affordance understanding in egocentric views. We also propose Reason-to-Ground (RoG) instruction tuning; it enables hybrid training with normal descriptions and egocentric intentions with a chained intention reasoning and object grounding mechanism. RoG significantly outperforms naive finetuning and hybrid training on EgoIntention, while maintaining or slightly improving naive description grounding. This advancement enables unified visual grounding for egocentric and exocentric visual inputs while handling explicit object queries and implicit human intentions.
LayoutGPT: Compositional Visual Planning and Generation with Large Language Models
May 24, 2023
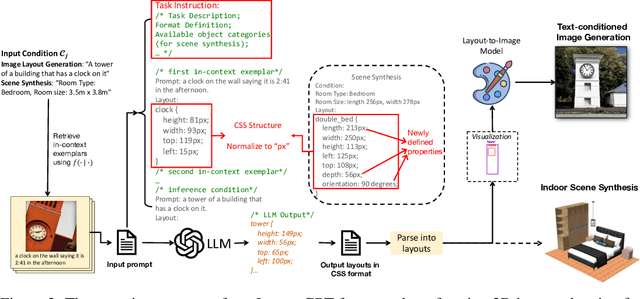
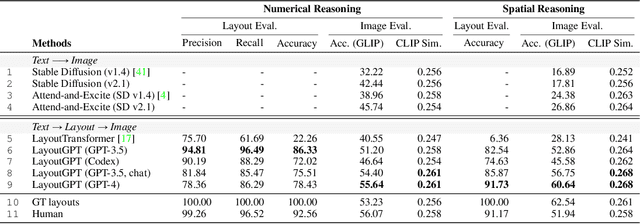

Attaining a high degree of user controllability in visual generation often requires intricate, fine-grained inputs like layouts. However, such inputs impose a substantial burden on users when compared to simple text inputs. To address the issue, we study how Large Language Models (LLMs) can serve as visual planners by generating layouts from text conditions, and thus collaborate with visual generative models. We propose LayoutGPT, a method to compose in-context visual demonstrations in style sheet language to enhance the visual planning skills of LLMs. LayoutGPT can generate plausible layouts in multiple domains, ranging from 2D images to 3D indoor scenes. LayoutGPT also shows superior performance in converting challenging language concepts like numerical and spatial relations to layout arrangements for faithful text-to-image generation. When combined with a downstream image generation model, LayoutGPT outperforms text-to-image models/systems by 20-40% and achieves comparable performance as human users in designing visual layouts for numerical and spatial correctness. Lastly, LayoutGPT achieves comparable performance to supervised methods in 3D indoor scene synthesis, demonstrating its effectiveness and potential in multiple visual domains.
Discriminative Diffusion Models as Few-shot Vision and Language Learners
May 18, 2023


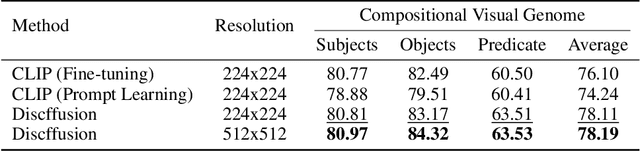
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis
Dec 09, 2022



Large-scale diffusion models have achieved state-of-the-art results on text-to-image synthesis (T2I) tasks. Despite their ability to generate high-quality yet creative images, we observe that attribution-binding and compositional capabilities are still considered major challenging issues, especially when involving multiple objects. In this work, we improve the compositional skills of T2I models, specifically more accurate attribute binding and better image compositions. To do this, we incorporate linguistic structures with the diffusion guidance process based on the controllable properties of manipulating cross-attention layers in diffusion-based T2I models. We observe that keys and values in cross-attention layers have strong semantic meanings associated with object layouts and content. Therefore, we can better preserve the compositional semantics in the generated image by manipulating the cross-attention representations based on linguistic insights. Built upon Stable Diffusion, a SOTA T2I model, our structured cross-attention design is efficient that requires no additional training samples. We achieve better compositional skills in qualitative and quantitative results, leading to a 5-8% advantage in head-to-head user comparison studies. Lastly, we conduct an in-depth analysis to reveal potential causes of incorrect image compositions and justify the properties of cross-attention layers in the generation process.
CPL: Counterfactual Prompt Learning for Vision and Language Models
Oct 19, 2022
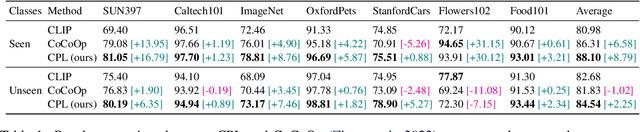
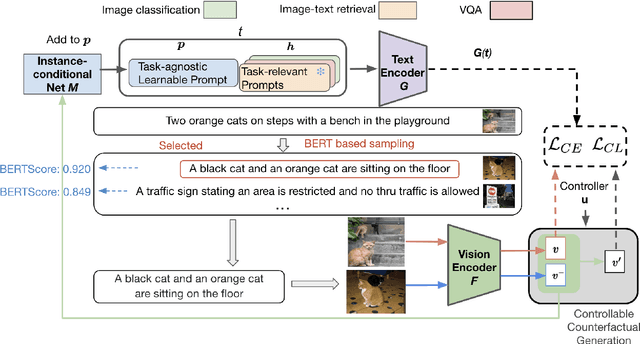
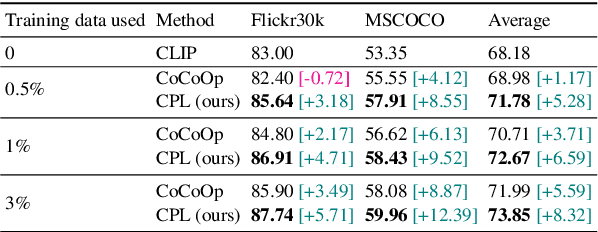
Prompt tuning is a new few-shot transfer learning technique that only tunes the learnable prompt for pre-trained vision and language models such as CLIP. However, existing prompt tuning methods tend to learn spurious or entangled representations, which leads to poor generalization to unseen concepts. Towards non-spurious and efficient prompt learning from limited examples, this paper presents a novel \underline{\textbf{C}}ounterfactual \underline{\textbf{P}}rompt \underline{\textbf{L}}earning (CPL) method for vision and language models, which simultaneously employs counterfactual generation and contrastive learning in a joint optimization framework. Particularly, CPL constructs counterfactual by identifying minimal non-spurious feature change between semantically-similar positive and negative samples that causes concept change, and learns more generalizable prompt representation from both factual and counterfactual examples via contrastive learning. Extensive experiments demonstrate that CPL can obtain superior few-shot performance on different vision and language tasks than previous prompt tuning methods on CLIP. On image classification, we achieve 3.55\% average relative improvement on unseen classes across seven datasets; on image-text retrieval and visual question answering, we gain up to 4.09\% and 25.08\% relative improvements across three few-shot scenarios on unseen test sets respectively.