 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvive or Collapse: The Asymmetric Roles of Data Gating and Reward Grounding in Self-Play RL
May 21, 2026Self-play reinforcement learning trains language models on their own generated tasks, co-evolving a proposer and solver without human labels. Recent systems report strong reasoning gains, but collapse and instability are widely observed and poorly understood. The dominant response treats this as a reward-design problem. We argue instead that self-play stability is governed by two distinct levers: a data-level gate that decides which proposer-generated tasks enter the training pool, and the reward signal that updates the policy on tasks already admitted. Through controlled experiments on a Python output-prediction task and a deterministic-DSL twin task that strips pretraining priors, output ambiguity, and executor noise, we find the two levers are asymmetric. A strict gate is sufficient for stability under every reward variant we test, including a self-consistency reward with no access to ground truth; while no reward variant is sufficient once the gate is removed. This asymmetry exposes a counter-intuitive coupling we call the Grounded Proposer Paradox: a proposer with ground-truth access accelerates collapse faster than an ungrounded one when paired with a self-consistency solver, by concentrating training on clean tasks that form the fastest path to a spurious self-consistent attractor. Replacing the binary gate with a continuous strictness parameter $\varepsilon$ further reveals a two-stage phase transition: training-side metrics decouple at low $\varepsilon$, while validation accuracy holds until $\varepsilon$ is much higher. Data-level gating, not reward calibration, is the binding constraint on self-play stability.
EnactToM: An Evolving Benchmark for Functional Theory of Mind in Embodied Agents
May 11, 2026Theory of Mind (ToM), the ability to track others epistemic state, makes humans efficient collaborators. AI agents need the same capacity in multi agent settings, yet existing benchmarks mostly test literal ToM by asking direct belief questions. The ability act optimally on implicit beliefs in embodied environments, called functional ToM, remains largely untested. We introduce EnactToM, an evolving benchmark of 300 embodied multi-agent tasks set in a 3D household with partial observability, private information, and constrained communication. Each task is formally verified for solvability and required epistemic depth, and new tasks are generated increase difficulty as models improve. On the hard split, all seven evaluated frontier models score 0.0% Pass^3 on functional task completion, while averaging 45.0% on literal belief probes. Manual analysis traces 93% of sampled failures to epistemic coordination breakdowns such as withheld information, ignored partner constraints, and misallocated messages, providing a concrete target for future work.
Proactive Agent Research Environment: Simulating Active Users to Evaluate Proactive Assistants
Apr 01, 2026Proactive agents that anticipate user needs and autonomously execute tasks hold great promise as digital assistants, yet the lack of realistic user simulation frameworks hinders their development. Existing approaches model apps as flat tool-calling APIs, failing to capture the stateful and sequential nature of user interaction in digital environments and making realistic user simulation infeasible. We introduce Proactive Agent Research Environment (Pare), a framework for building and evaluating proactive agents in digital environments. Pare models applications as finite state machines with stateful navigation and state-dependent action space for the user simulator, enabling active user simulation. Building on this foundation, we present Pare-Bench, a benchmark of 143 diverse tasks spanning communication, productivity, scheduling, and lifestyle apps, designed to test context observation, goal inference, intervention timing, and multi-app orchestration.
TermiGen: High-Fidelity Environment and Robust Trajectory Synthesis for Terminal Agents
Feb 06, 2026Executing complex terminal tasks remains a significant challenge for open-weight LLMs, constrained by two fundamental limitations. First, high-fidelity, executable training environments are scarce: environments synthesized from real-world repositories are not diverse and scalable, while trajectories synthesized by LLMs suffer from hallucinations. Second, standard instruction tuning uses expert trajectories that rarely exhibit simple mistakes common to smaller models. This creates a distributional mismatch, leaving student models ill-equipped to recover from their own runtime failures. To bridge these gaps, we introduce TermiGen, an end-to-end pipeline for synthesizing verifiable environments and resilient expert trajectories. Termi-Gen first generates functionally valid tasks and Docker containers via an iterative multi-agent refinement loop. Subsequently, we employ a Generator-Critic protocol that actively injects errors during trajectory collection, synthesizing data rich in error-correction cycles. Fine-tuned on this TermiGen-generated dataset, our TermiGen-Qwen2.5-Coder-32B achieves a 31.3% pass rate on TerminalBench. This establishes a new open-weights state-of-the-art, outperforming existing baselines and notably surpassing capable proprietary models such as o4-mini. Dataset is avaiable at https://github.com/ucsb-mlsec/terminal-bench-env.
DevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
Training LLMs with LogicReward for Faithful and Rigorous Reasoning
Dec 20, 2025
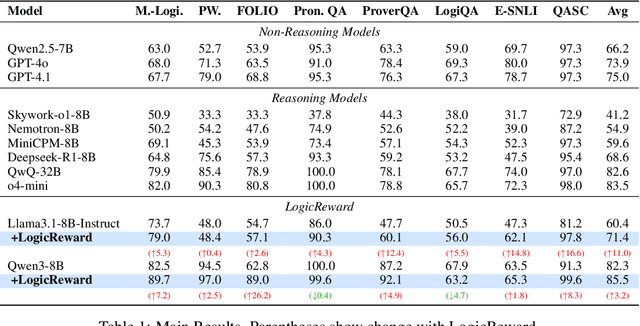
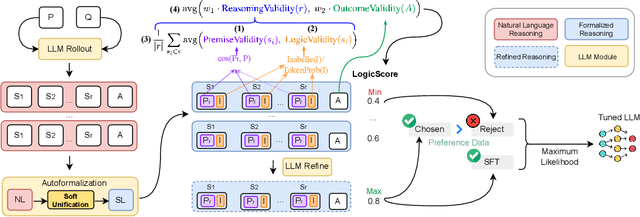

Although LLMs exhibit strong reasoning capabilities, existing training methods largely depend on outcome-based feedback, which can produce correct answers with flawed reasoning. Prior work introduces supervision on intermediate steps but still lacks guarantees of logical soundness, which is crucial in high-stakes scenarios where logical consistency is paramount. To address this, we propose LogicReward, a novel reward system that guides model training by enforcing step-level logical correctness with a theorem prover. We further introduce Autoformalization with Soft Unification, which reduces natural language ambiguity and improves formalization quality, enabling more effective use of the theorem prover. An 8B model trained on data constructed with LogicReward surpasses GPT-4o and o4-mini by 11.6\% and 2\% on natural language inference and logical reasoning tasks with simple training procedures. Further analysis shows that LogicReward enhances reasoning faithfulness, improves generalizability to unseen tasks such as math and commonsense reasoning, and provides a reliable reward signal even without ground-truth labels. We will release all data and code at https://llm-symbol.github.io/LogicReward.
Dynamic Evaluation for Oversensitivity in LLMs
Oct 21, 2025Oversensitivity occurs when language models defensively reject prompts that are actually benign. This behavior not only disrupts user interactions but also obscures the boundary between harmful and harmless content. Existing benchmarks rely on static datasets that degrade overtime as models evolve, leading to data contamination and diminished evaluative power. To address this, we develop a framework that dynamically generates model-specific challenging datasets, capturing emerging defensive patterns and aligning with each model's unique behavior. Building on this approach, we construct OVERBENCH, a benchmark that aggregates these datasets across diverse LLM families, encompassing 450,000 samples from 25 models. OVERBENCH provides a dynamic and evolving perspective on oversensitivity, allowing for continuous monitoring of defensive triggers as models advance, highlighting vulnerabilities that static datasets overlook.
LEDOM: An Open and Fundamental Reverse Language Model
Jul 02, 2025We introduce LEDOM, the first purely reverse language model, trained autoregressively on 435B tokens with 2B and 7B parameter variants, which processes sequences in reverse temporal order through previous token prediction. For the first time, we present the reverse language model as a potential foundational model across general tasks, accompanied by a set of intriguing examples and insights. Based on LEDOM, we further introduce a novel application: Reverse Reward, where LEDOM-guided reranking of forward language model outputs leads to substantial performance improvements on mathematical reasoning tasks. This approach leverages LEDOM's unique backward reasoning capability to refine generation quality through posterior evaluation. Our findings suggest that LEDOM exhibits unique characteristics with broad application potential. We will release all models, training code, and pre-training data to facilitate future research.
MAGPIE: A dataset for Multi-AGent contextual PrIvacy Evaluation
Jun 25, 2025The proliferation of LLM-based agents has led to increasing deployment of inter-agent collaboration for tasks like scheduling, negotiation, resource allocation etc. In such systems, privacy is critical, as agents often access proprietary tools and domain-specific databases requiring strict confidentiality. This paper examines whether LLM-based agents demonstrate an understanding of contextual privacy. And, if instructed, do these systems preserve inference time user privacy in non-adversarial multi-turn conversation. Existing benchmarks to evaluate contextual privacy in LLM-agents primarily assess single-turn, low-complexity tasks where private information can be easily excluded. We first present a benchmark - MAGPIE comprising 158 real-life high-stakes scenarios across 15 domains. These scenarios are designed such that complete exclusion of private data impedes task completion yet unrestricted information sharing could lead to substantial losses. We then evaluate the current state-of-the-art LLMs on (a) their understanding of contextually private data and (b) their ability to collaborate without violating user privacy. Empirical experiments demonstrate that current models, including GPT-4o and Claude-2.7-Sonnet, lack robust understanding of contextual privacy, misclassifying private data as shareable 25.2\% and 43.6\% of the time. In multi-turn conversations, these models disclose private information in 59.9\% and 50.5\% of cases even under explicit privacy instructions. Furthermore, multi-agent systems fail to complete tasks in 71\% of scenarios. These results underscore that current models are not aligned towards both contextual privacy preservation and collaborative task-solving.
Semantic Scheduling for LLM Inference
Jun 13, 2025Conventional operating system scheduling algorithms are largely content-ignorant, making decisions based on factors such as latency or fairness without considering the actual intents or semantics of processes. Consequently, these algorithms often do not prioritize tasks that require urgent attention or carry higher importance, such as in emergency management scenarios. However, recent advances in language models enable semantic analysis of processes, allowing for more intelligent and context-aware scheduling decisions. In this paper, we introduce the concept of semantic scheduling in scheduling of requests from large language models (LLM), where the semantics of the process guide the scheduling priorities. We present a novel scheduling algorithm with optimal time complexity, designed to minimize the overall waiting time in LLM-based prompt scheduling. To illustrate its effectiveness, we present a medical emergency management application, underscoring the potential benefits of semantic scheduling for critical, time-sensitive tasks. The code and data are available at https://github.com/Wenyueh/latency_optimization_with_priority_constraints.