 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaia2: Benchmarking LLM Agents on Dynamic and Asynchronous Environments
Feb 12, 2026We introduce Gaia2, a benchmark for evaluating large language model agents in realistic, asynchronous environments. Unlike prior static or synchronous evaluations, Gaia2 introduces scenarios where environments evolve independently of agent actions, requiring agents to operate under temporal constraints, adapt to noisy and dynamic events, resolve ambiguity, and collaborate with other agents. Each scenario is paired with a write-action verifier, enabling fine-grained, action-level evaluation and making Gaia2 directly usable for reinforcement learning from verifiable rewards. Our evaluation of state-of-the-art proprietary and open-source models shows that no model dominates across capabilities: GPT-5 (high) reaches the strongest overall score of 42% pass@1 but fails on time-sensitive tasks, Claude-4 Sonnet trades accuracy and speed for cost, Kimi-K2 leads among open-source models with 21% pass@1. These results highlight fundamental trade-offs between reasoning, efficiency, robustness, and expose challenges in closing the "sim2real" gap. Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform and designed to be easy to extend. By releasing Gaia2 alongside the foundational ARE framework, we aim to provide the community with a flexible infrastructure for developing, benchmarking, and training the next generation of practical agent systems.
AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
Nov 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse domains, but their training remains resource- and time-intensive, requiring massive compute power and careful orchestration of training procedures. Model souping-the practice of averaging weights from multiple models of the same architecture-has emerged as a promising pre- and post-training technique that can enhance performance without expensive retraining. In this paper, we introduce Soup Of Category Experts (SoCE), a principled approach for model souping that utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance. Contrary to previous uniform-averaging approaches, our method leverages the observation that benchmark categories often exhibit low inter-correlations in model performance. SoCE identifies "expert" models for each weakly-correlated category cluster and combines them using optimized weighted averaging rather than uniform weights. We demonstrate that the proposed method improves performance and robustness across multiple domains, including multilingual capabilities, tool calling, and math and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
Revisiting SVD to generate powerful Node Embeddings for Recommendation Systems
Oct 05, 2021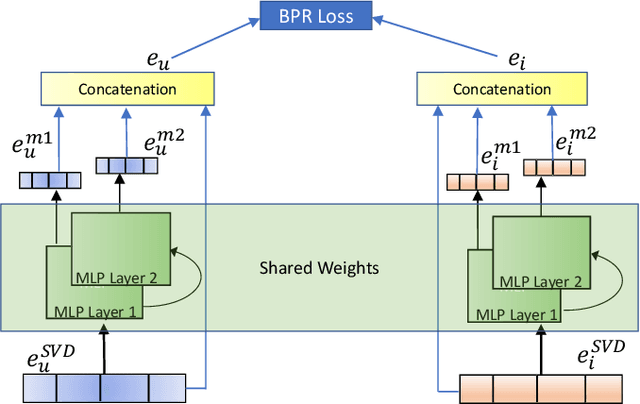



Graph Representation Learning (GRL) is an upcoming and promising area in recommendation systems. In this paper, we revisit the Singular Value Decomposition (SVD) of adjacency matrix for embedding generation of users and items and use a two-layer neural network on top of these embeddings to learn relevance between user-item pairs. Inspired by the success of higher-order learning in GRL, we further propose an extension of this method to include two-hop neighbors for SVD through the second order of the adjacency matrix and demonstrate improved performance compared with the simple SVD method which only uses one-hop neighbors. Empirical validation on three publicly available datasets of recommendation system demonstrates that the proposed methods, despite being simple, beat many state-of-the-art methods and for two of three datasets beats all of them up to a margin of 10%. Through our research, we want to shed light on the effectiveness of matrix factorization approaches, specifically SVD, in the deep learning era and show that these methods still contribute as important baselines in recommendation systems.
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Apr 20, 2020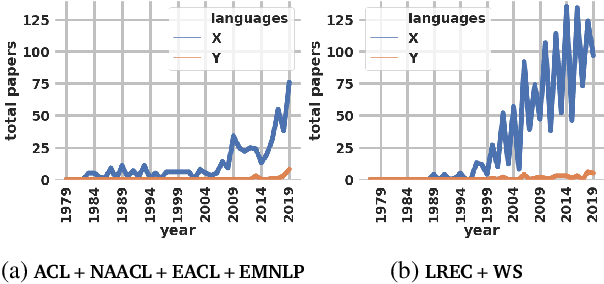
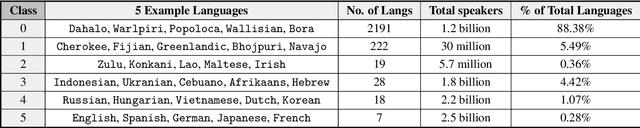
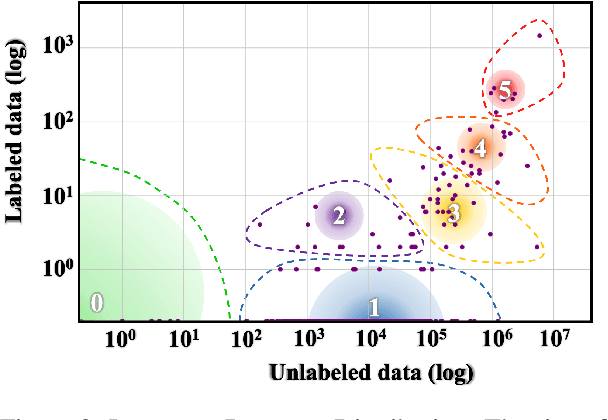
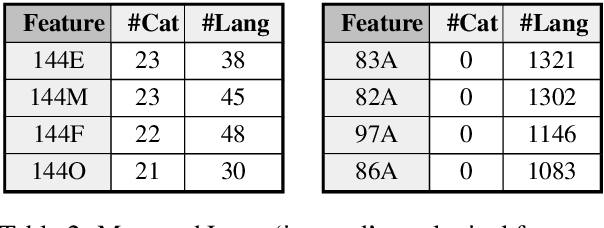
Language technologies contribute to promoting multilingualism and linguistic diversity around the world. However, only a very small number of the over 7000 languages of the world are represented in the rapidly evolving language technologies and applications. In this paper we look at the relation between the types of languages, resources, and their representation in NLP conferences to understand the trajectory that different languages have followed over time. Our quantitative investigation underlines the disparity between languages, especially in terms of their resources, and calls into question the "language agnostic" status of current models and systems. Through this paper, we attempt to convince the ACL community to prioritise the resolution of the predicaments highlighted here, so that no language is left behind.
Rich-Item Recommendations for Rich-Users via GCNN: Exploiting Dynamic and Static Side Information
Jan 28, 2020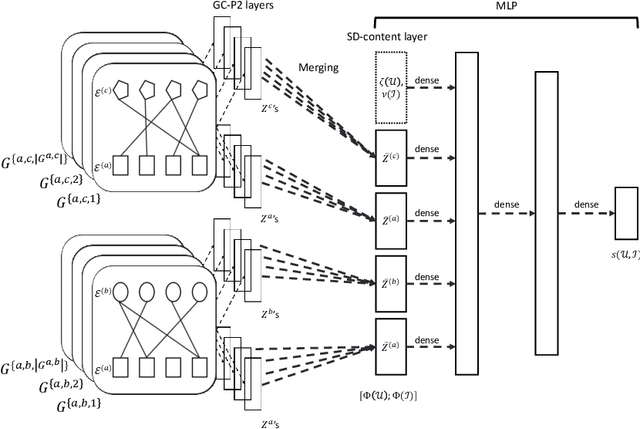
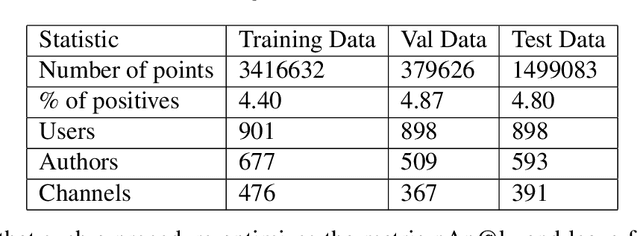
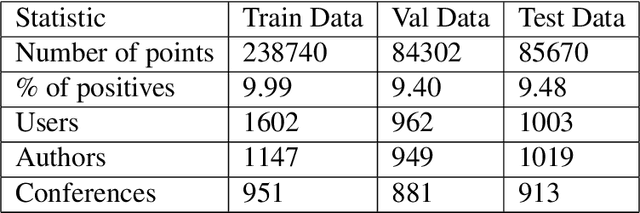
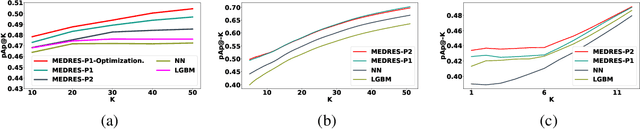
We study the standard problem of recommending relevant items to users; a user is someone who seeks recommendation, and an item is something which should be recommended. In today's modern world, both users and items are 'rich' multi-faceted entities but existing literature, for ease of modeling, views these facets in silos. In this paper, we provide a general formulation of the recommendation problem that captures the complexities of modern systems and encompasses most of the existing recommendation system formulations. In our formulation, each user and item is modeled via a set of static entities and a dynamic component. The relationships between entities are captured by multiple weighted bipartite graphs. To effectively exploit these complex interactions for recommendations, we propose MEDRES -- a multiple graph-CNN based novel deep-learning architecture. In addition, we propose a new metric, pAp@k, that is critical for a variety of classification+ranking scenarios. We also provide an optimization algorithm that directly optimizes the proposed metric and trains MEDRES in an end-to-end framework. We demonstrate the effectiveness of our method on two benchmarks as well as on a message recommendation system deployed in Microsoft Teams where it improves upon the existing production-grade model by 3%.