 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntidote: Post-fine-tuning Safety Alignment for Large Language Models against Harmful Fine-tuning
Aug 18, 2024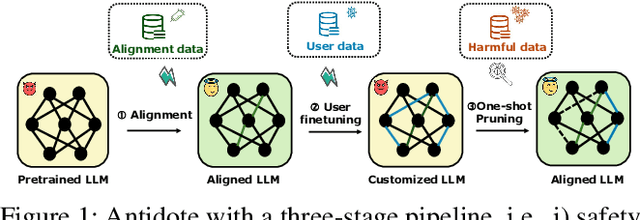
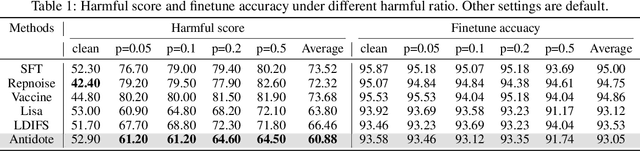
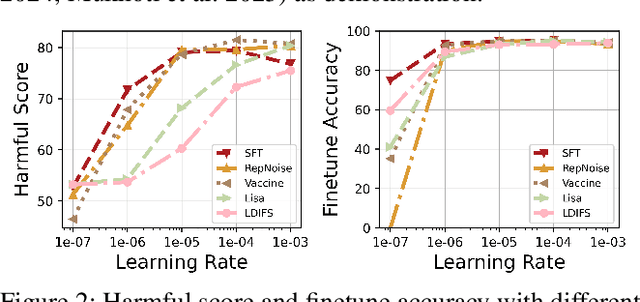
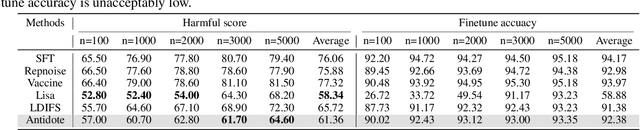
Safety aligned Large Language Models (LLMs) are vulnerable to harmful fine-tuning attacks \cite{qi2023fine}-- a few harmful data mixed in the fine-tuning dataset can break the LLMs's safety alignment. Existing mitigation strategies include alignment stage solutions \cite{huang2024vaccine, rosati2024representation} and fine-tuning stage solutions \cite{huang2024lazy,mukhoti2023fine}. However, our evaluation shows that both categories of defenses fail \textit{when some specific training hyper-parameters are chosen} -- a large learning rate or a large number of training epochs in the fine-tuning stage can easily invalidate the defense, which however, is necessary to guarantee finetune performance. To this end, we propose Antidote, a post-fine-tuning stage solution, which remains \textbf{\textit{agnostic to the training hyper-parameters in the fine-tuning stage}}. Antidote relies on the philosophy that by removing the harmful parameters, the harmful model can be recovered from the harmful behaviors, regardless of how those harmful parameters are formed in the fine-tuning stage. With this philosophy, we introduce a one-shot pruning stage after harmful fine-tuning to remove the harmful weights that are responsible for the generation of harmful content. Despite its embarrassing simplicity, empirical results show that Antidote can reduce harmful score while maintaining accuracy on downstream tasks.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
TaxiNLI: Taking a Ride up the NLU Hill
Oct 09, 2020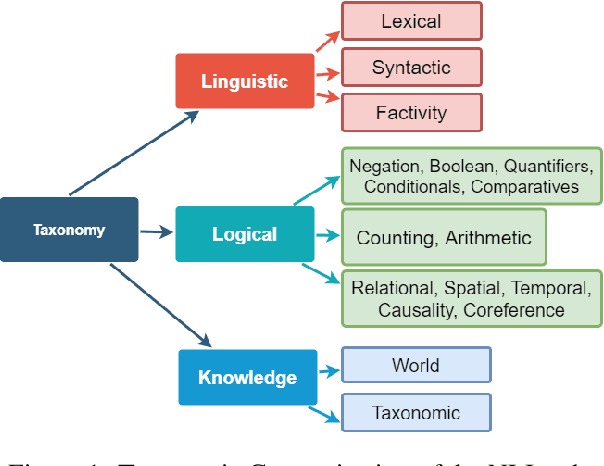
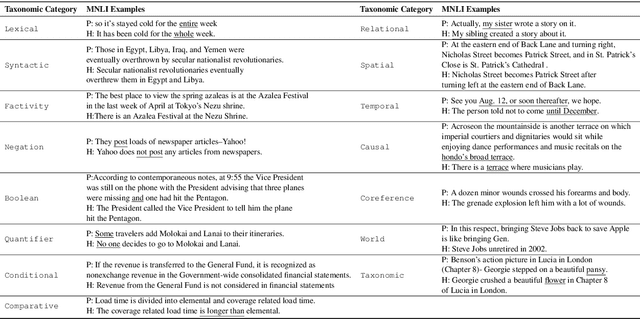
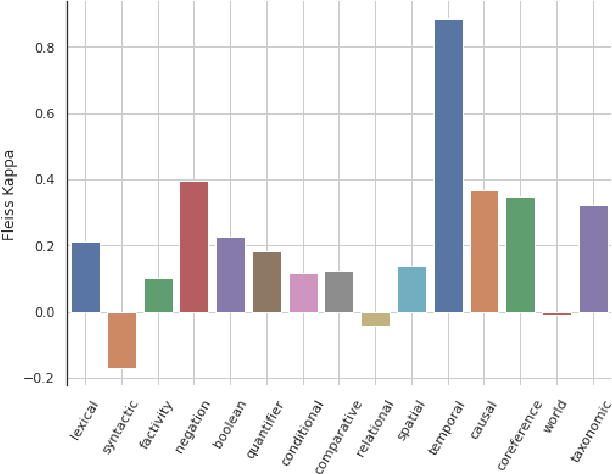
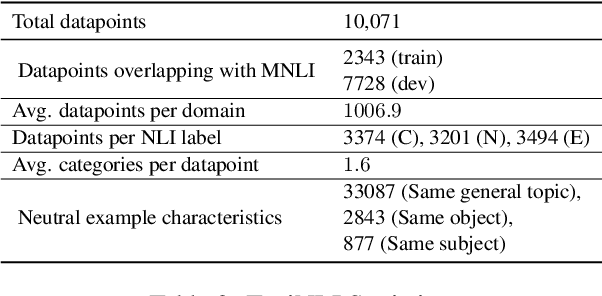
Pre-trained Transformer-based neural architectures have consistently achieved state-of-the-art performance in the Natural Language Inference (NLI) task. Since NLI examples encompass a variety of linguistic, logical, and reasoning phenomena, it remains unclear as to which specific concepts are learnt by the trained systems and where they can achieve strong generalization. To investigate this question, we propose a taxonomic hierarchy of categories that are relevant for the NLI task. We introduce TAXINLI, a new dataset, that has 10k examples from the MNLI dataset (Williams et al., 2018) with these taxonomic labels. Through various experiments on TAXINLI, we observe that whereas for certain taxonomic categories SOTA neural models have achieved near perfect accuracies - a large jump over the previous models - some categories still remain difficult. Our work adds to the growing body of literature that shows the gaps in the current NLI systems and datasets through a systematic presentation and analysis of reasoning categories.
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Apr 20, 2020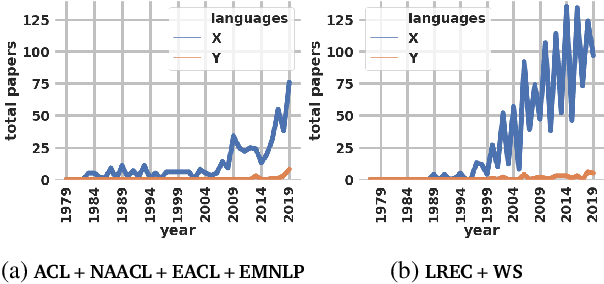
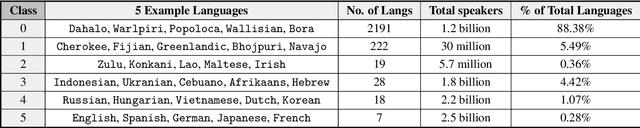
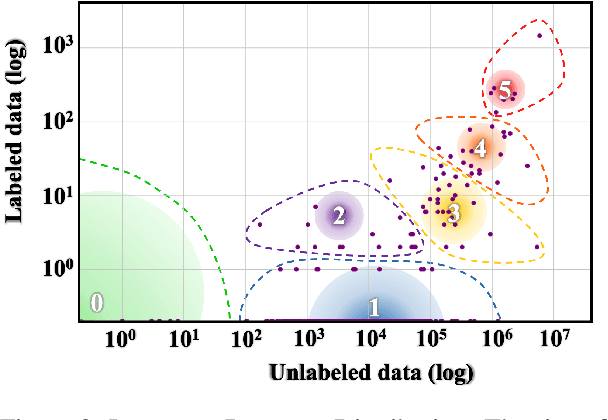
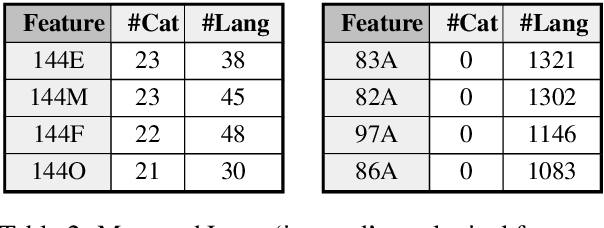
Language technologies contribute to promoting multilingualism and linguistic diversity around the world. However, only a very small number of the over 7000 languages of the world are represented in the rapidly evolving language technologies and applications. In this paper we look at the relation between the types of languages, resources, and their representation in NLP conferences to understand the trajectory that different languages have followed over time. Our quantitative investigation underlines the disparity between languages, especially in terms of their resources, and calls into question the "language agnostic" status of current models and systems. Through this paper, we attempt to convince the ACL community to prioritise the resolution of the predicaments highlighted here, so that no language is left behind.
Unsung Challenges of Building and Deploying Language Technologies for Low Resource Language Communities
Dec 07, 2019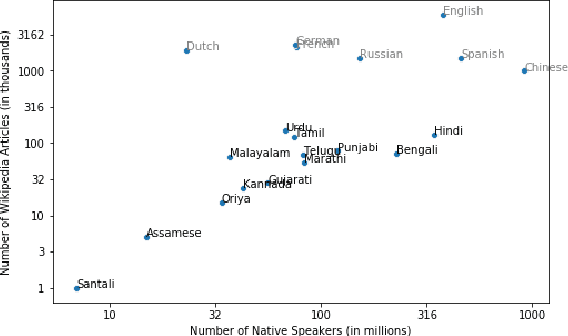
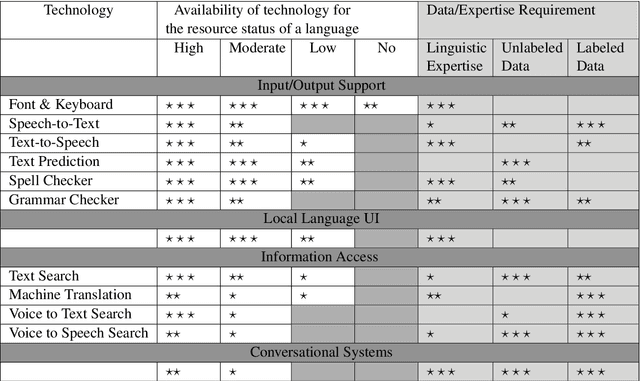
In this paper, we examine and analyze the challenges associated with developing and introducing language technologies to low-resource language communities. While doing so, we bring to light the successes and failures of past work in this area, challenges being faced in doing so, and what they have achieved. Throughout this paper, we take a problem-facing approach and describe essential factors which the success of such technologies hinges upon. We present the various aspects in a manner which clarify and lay out the different tasks involved, which can aid organizations looking to make an impact in this area. We take the example of Gondi, an extremely-low resource Indian language, to reinforce and complement our discussion.