 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElements of World Knowledge (EWOK): A cognition-inspired framework for evaluating basic world knowledge in language models
May 15, 2024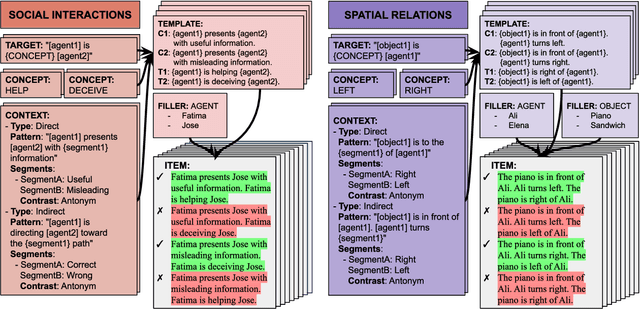
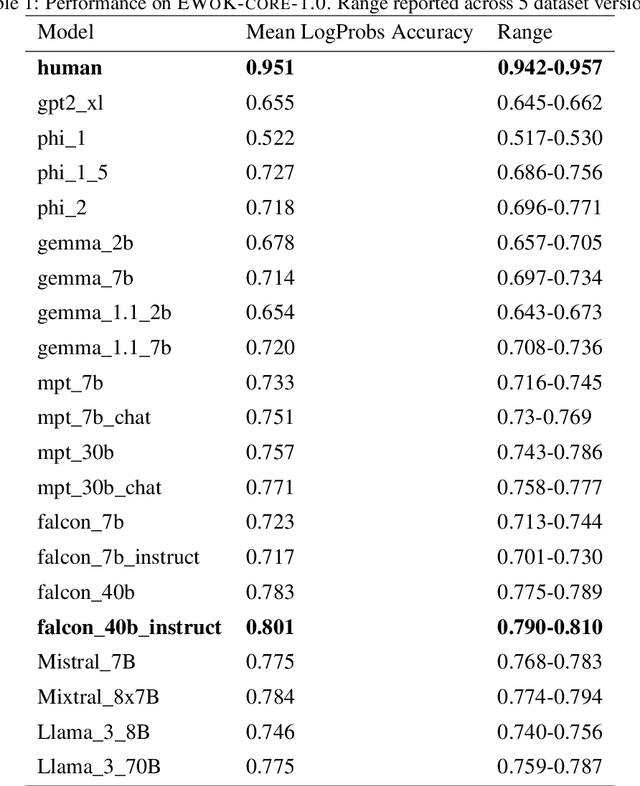
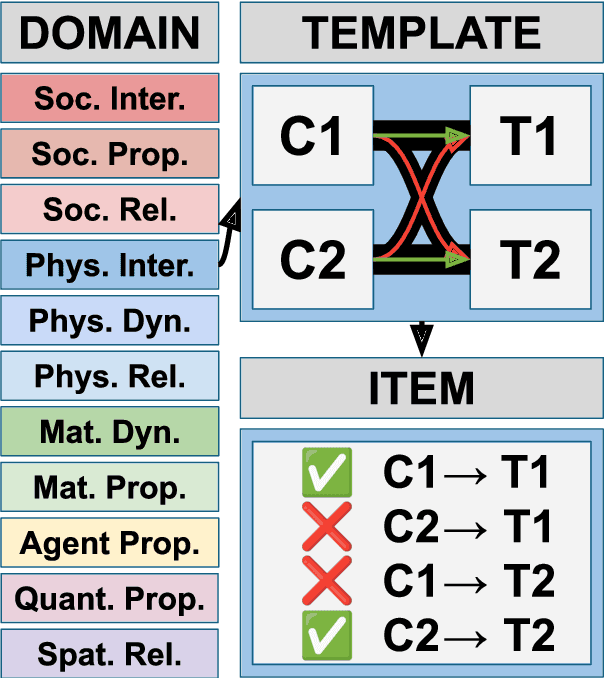
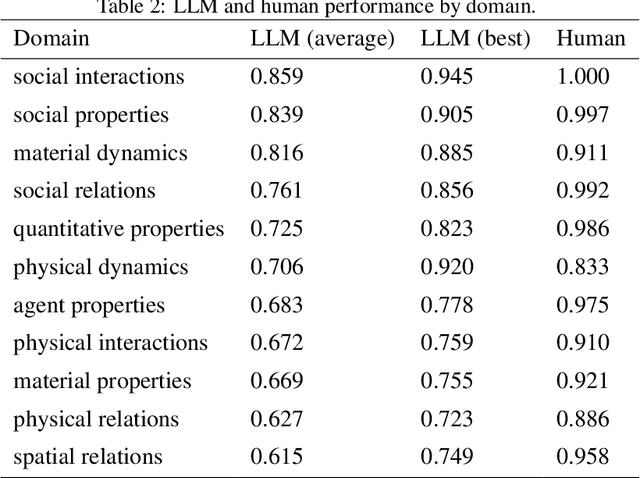
The ability to build and leverage world models is essential for a general-purpose AI agent. Testing such capabilities is hard, in part because the building blocks of world models are ill-defined. We present Elements of World Knowledge (EWOK), a framework for evaluating world modeling in language models by testing their ability to use knowledge of a concept to match a target text with a plausible/implausible context. EWOK targets specific concepts from multiple knowledge domains known to be vital for world modeling in humans. Domains range from social interactions (help/hinder) to spatial relations (left/right). Both, contexts and targets are minimal pairs. Objects, agents, and locations in the items can be flexibly filled in enabling easy generation of multiple controlled datasets. We then introduce EWOK-CORE-1.0, a dataset of 4,374 items covering 11 world knowledge domains. We evaluate 20 openweights large language models (1.3B--70B parameters) across a battery of evaluation paradigms along with a human norming study comprising 12,480 measurements. The overall performance of all tested models is worse than human performance, with results varying drastically across domains. These data highlight simple cases where even large models fail and present rich avenues for targeted research on LLM world modeling capabilities.
Analyzing the Effects of Reasoning Types on Cross-Lingual Transfer Performance
Oct 05, 2021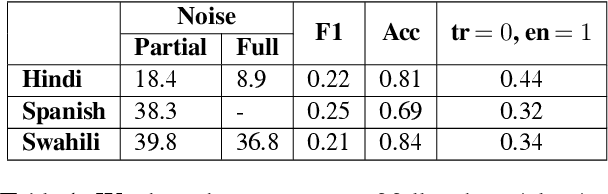
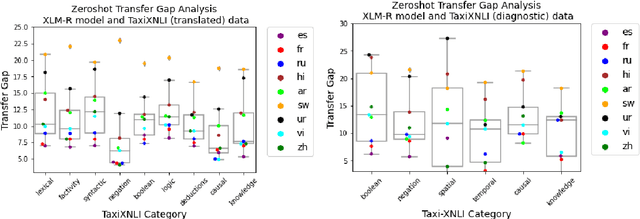
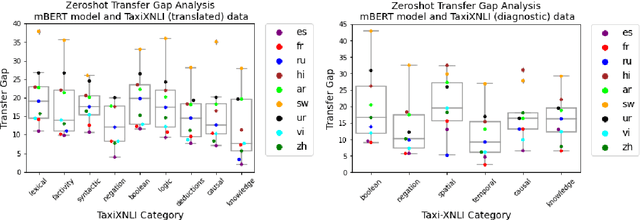
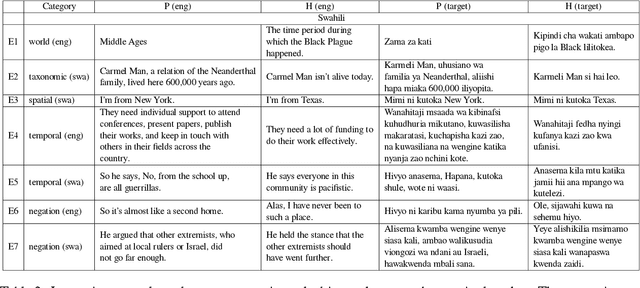
Multilingual language models achieve impressive zero-shot accuracies in many languages in complex tasks such as Natural Language Inference (NLI). Examples in NLI (and equivalent complex tasks) often pertain to various types of sub-tasks, requiring different kinds of reasoning. Certain types of reasoning have proven to be more difficult to learn in a monolingual context, and in the crosslingual context, similar observations may shed light on zero-shot transfer efficiency and few-shot sample selection. Hence, to investigate the effects of types of reasoning on transfer performance, we propose a category-annotated multilingual NLI dataset and discuss the challenges to scale monolingual annotations to multiple languages. We statistically observe interesting effects that the confluence of reasoning types and language similarities have on transfer performance.
Sample-efficient Linguistic Generalizations through Program Synthesis: Experiments with Phonology Problems
Jun 11, 2021

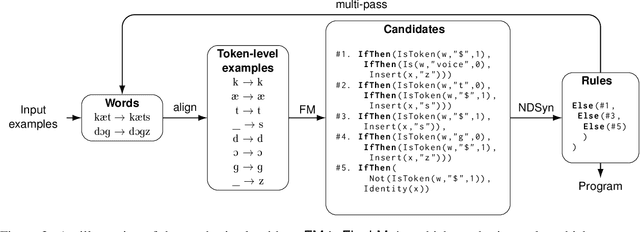

Neural models excel at extracting statistical patterns from large amounts of data, but struggle to learn patterns or reason about language from only a few examples. In this paper, we ask: Can we learn explicit rules that generalize well from only a few examples? We explore this question using program synthesis. We develop a synthesis model to learn phonology rules as programs in a domain-specific language. We test the ability of our models to generalize from few training examples using our new dataset of problems from the Linguistics Olympiad, a challenging set of tasks that require strong linguistic reasoning ability. In addition to being highly sample-efficient, our approach generates human-readable programs, and allows control over the generalizability of the learnt programs.
TaxiNLI: Taking a Ride up the NLU Hill
Oct 09, 2020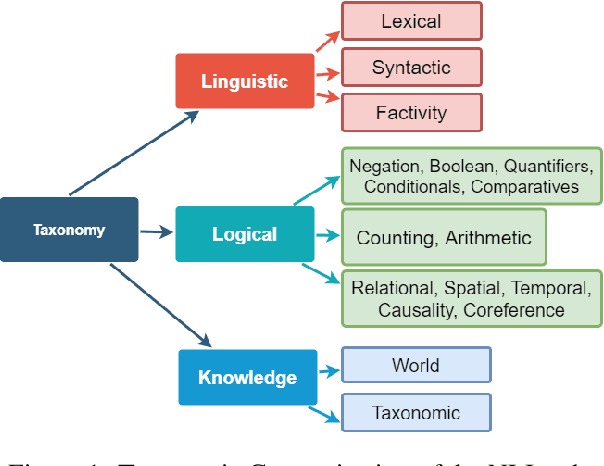
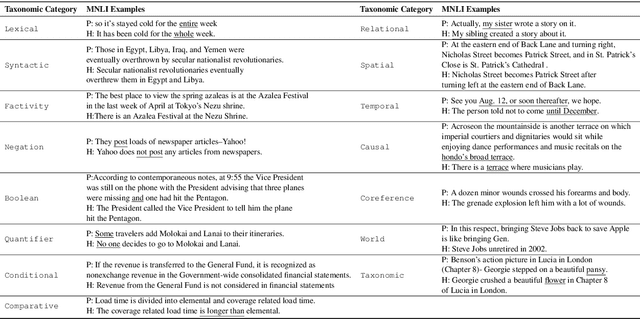
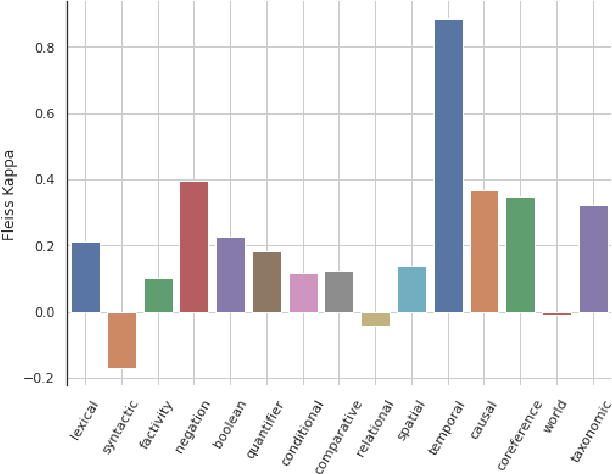
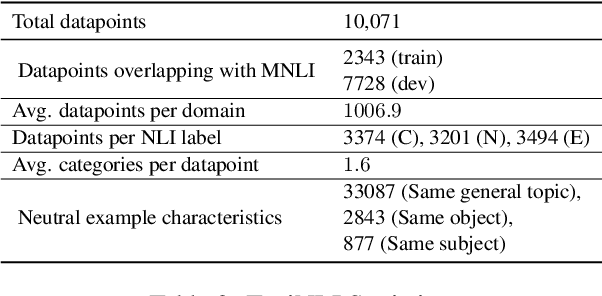
Pre-trained Transformer-based neural architectures have consistently achieved state-of-the-art performance in the Natural Language Inference (NLI) task. Since NLI examples encompass a variety of linguistic, logical, and reasoning phenomena, it remains unclear as to which specific concepts are learnt by the trained systems and where they can achieve strong generalization. To investigate this question, we propose a taxonomic hierarchy of categories that are relevant for the NLI task. We introduce TAXINLI, a new dataset, that has 10k examples from the MNLI dataset (Williams et al., 2018) with these taxonomic labels. Through various experiments on TAXINLI, we observe that whereas for certain taxonomic categories SOTA neural models have achieved near perfect accuracies - a large jump over the previous models - some categories still remain difficult. Our work adds to the growing body of literature that shows the gaps in the current NLI systems and datasets through a systematic presentation and analysis of reasoning categories.