 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying & Interactively Refining Ambiguous User Goals for Data Visualization Code Generation
Oct 10, 2025Establishing shared goals is a fundamental step in human-AI communication. However, ambiguities can lead to outputs that seem correct but fail to reflect the speaker's intent. In this paper, we explore this issue with a focus on the data visualization domain, where ambiguities in natural language impact the generation of code that visualizes data. The availability of multiple views on the contextual (e.g., the intended plot and the code rendering the plot) allows for a unique and comprehensive analysis of diverse ambiguity types. We develop a taxonomy of types of ambiguity that arise in this task and propose metrics to quantify them. Using Matplotlib problems from the DS-1000 dataset, we demonstrate that our ambiguity metrics better correlate with human annotations than uncertainty baselines. Our work also explores how multi-turn dialogue can reduce ambiguity, therefore, improve code accuracy by better matching user goals. We evaluate three pragmatic models to inform our dialogue strategies: Gricean Cooperativity, Discourse Representation Theory, and Questions under Discussion. A simulated user study reveals how pragmatic dialogues reduce ambiguity and enhance code accuracy, highlighting the value of multi-turn exchanges in code generation.
mrCAD: Multimodal Refinement of Computer-aided Designs
Apr 28, 2025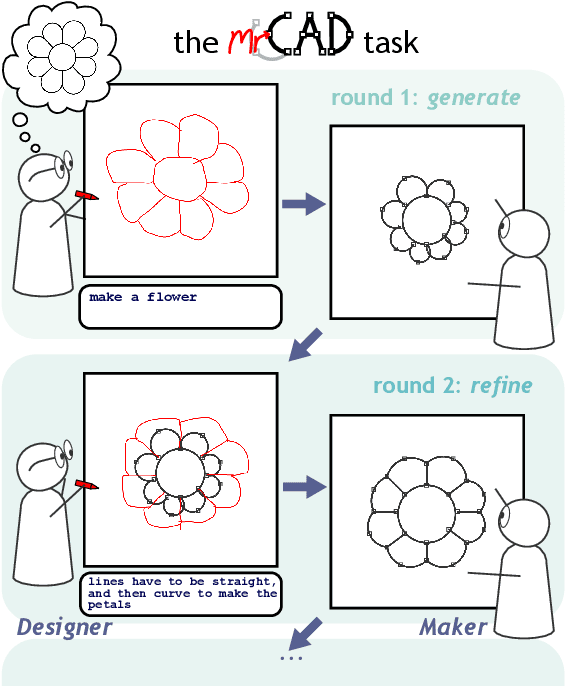
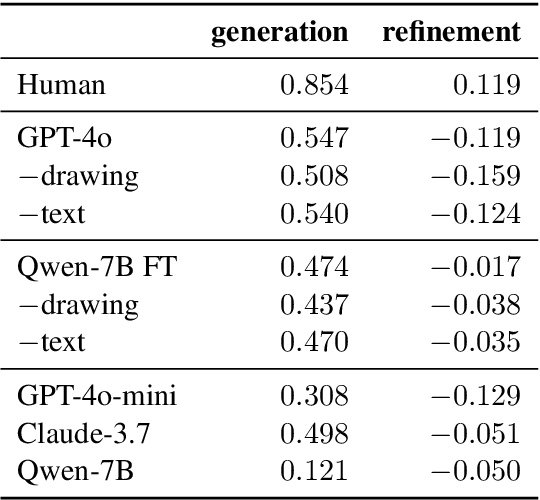
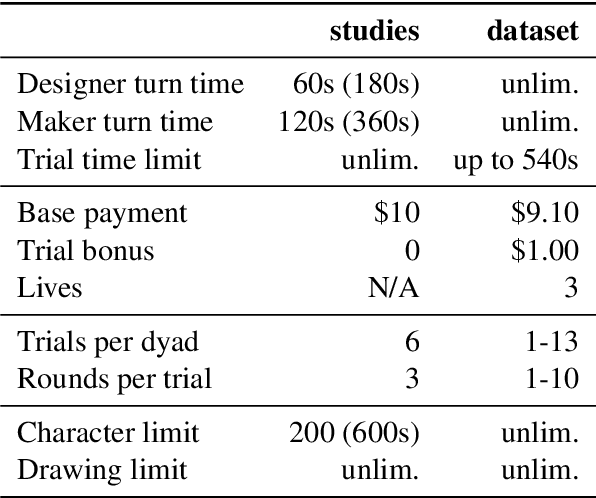
A key feature of human collaboration is the ability to iteratively refine the concepts we have communicated. In contrast, while generative AI excels at the \textit{generation} of content, it often struggles to make specific language-guided \textit{modifications} of its prior outputs. To bridge the gap between how humans and machines perform edits, we present mrCAD, a dataset of multimodal instructions in a communication game. In each game, players created computer aided designs (CADs) and refined them over several rounds to match specific target designs. Only one player, the Designer, could see the target, and they must instruct the other player, the Maker, using text, drawing, or a combination of modalities. mrCAD consists of 6,082 communication games, 15,163 instruction-execution rounds, played between 1,092 pairs of human players. We analyze the dataset and find that generation and refinement instructions differ in their composition of drawing and text. Using the mrCAD task as a benchmark, we find that state-of-the-art VLMs are better at following generation instructions than refinement instructions. These results lay a foundation for analyzing and modeling a multimodal language of refinement that is not represented in previous datasets.
Is the Pope Catholic? Yes, the Pope is Catholic. Generative Evaluation of Intent Resolution in LLMs
May 14, 2024



Humans often express their communicative intents indirectly or non-literally, which requires their interlocutors -- human or AI -- to understand beyond the literal meaning of words. While most existing work has focused on discriminative evaluations, we present a new approach to generatively evaluate large language models' (LLMs') intention understanding by examining their responses to non-literal utterances. Ideally, an LLM should respond in line with the true intention of a non-literal utterance, not its literal interpretation. Our findings show that LLMs struggle to generate pragmatically relevant responses to non-literal language, achieving only 50-55% accuracy on average. While explicitly providing oracle intentions significantly improves performance (e.g., 75% for Mistral-Instruct), this still indicates challenges in leveraging given intentions to produce appropriate responses. Using chain-of-thought to make models spell out intentions yields much smaller gains (60% for Mistral-Instruct). These findings suggest that LLMs are not yet effective pragmatic interlocutors, highlighting the need for better approaches for modeling intentions and utilizing them for pragmatic generation.
Generating Pragmatic Examples to Train Neural Program Synthesizers
Nov 09, 2023Programming-by-example is the task of synthesizing a program that is consistent with a set of user-provided input-output examples. As examples are often an under-specification of one's intent, a good synthesizer must choose the intended program from the many that are consistent with the given set of examples. Prior work frames program synthesis as a cooperative game between a listener (that synthesizes programs) and a speaker (a user choosing examples), and shows that models of computational pragmatic inference are effective in choosing the user intended programs. However, these models require counterfactual reasoning over a large set of programs and examples, which is infeasible in realistic program spaces. In this paper, we propose a novel way to amortize this search with neural networks. We sample pairs of programs and examples via self-play between listener and speaker models, and use pragmatic inference to choose informative training examples from this sample.We then use the informative dataset to train models to improve the synthesizer's ability to disambiguate user-provided examples without human supervision. We validate our method on the challenging task of synthesizing regular expressions from example strings, and find that our method (1) outperforms models trained without choosing pragmatic examples by 23% (a 51% relative increase) (2) matches the performance of supervised learning on a dataset of pragmatic examples provided by humans, despite using no human data in training.
Symbolic Planning and Code Generation for Grounded Dialogue
Oct 26, 2023



Large language models (LLMs) excel at processing and generating both text and code. However, LLMs have had limited applicability in grounded task-oriented dialogue as they are difficult to steer toward task objectives and fail to handle novel grounding. We present a modular and interpretable grounded dialogue system that addresses these shortcomings by composing LLMs with a symbolic planner and grounded code execution. Our system consists of a reader and planner: the reader leverages an LLM to convert partner utterances into executable code, calling functions that perform grounding. The translated code's output is stored to track dialogue state, while a symbolic planner determines the next appropriate response. We evaluate our system's performance on the demanding OneCommon dialogue task, involving collaborative reference resolution on abstract images of scattered dots. Our system substantially outperforms the previous state-of-the-art, including improving task success in human evaluations from 56% to 69% in the most challenging setting.
Amortizing Pragmatic Program Synthesis with Rankings
Sep 01, 2023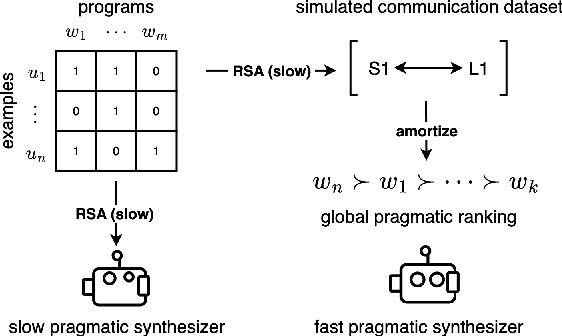
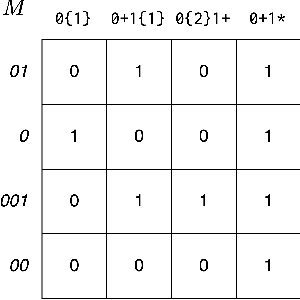
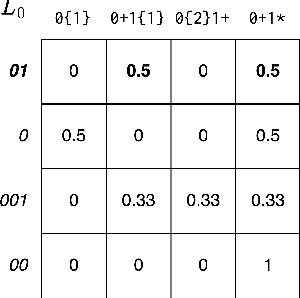
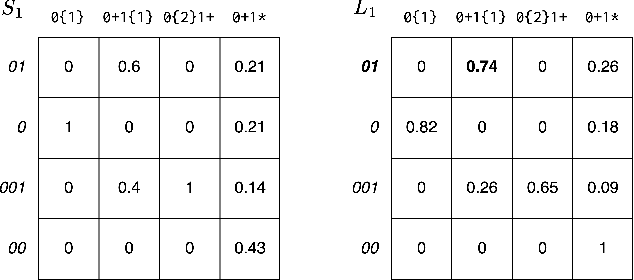
In program synthesis, an intelligent system takes in a set of user-generated examples and returns a program that is logically consistent with these examples. The usage of Rational Speech Acts (RSA) framework has been successful in building \emph{pragmatic} program synthesizers that return programs which -- in addition to being logically consistent -- account for the fact that a user chooses their examples informatively. However, the computational burden of running the RSA algorithm has restricted the application of pragmatic program synthesis to domains with a small number of possible programs. This work presents a novel method of amortizing the RSA algorithm by leveraging a \emph{global pragmatic ranking} -- a single, total ordering of all the hypotheses. We prove that for a pragmatic synthesizer that uses a single demonstration, our global ranking method exactly replicates RSA's ranked responses. We further empirically show that global rankings effectively approximate the full pragmatic synthesizer in an online, multi-demonstration setting. Experiments on two program synthesis domains using our pragmatic ranking method resulted in orders of magnitudes of speed ups compared to the RSA synthesizer, while outperforming the standard, non-pragmatic synthesizer.
Efficient Pragmatic Program Synthesis with Informative Specifications
Apr 05, 2022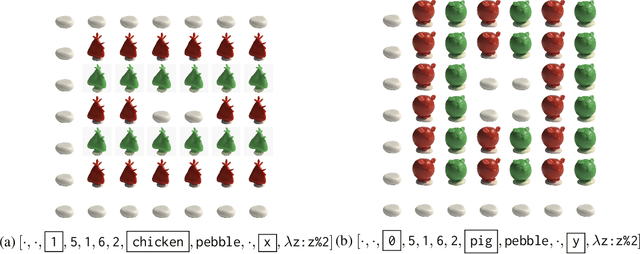
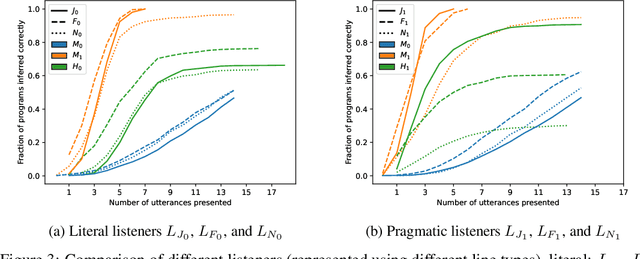
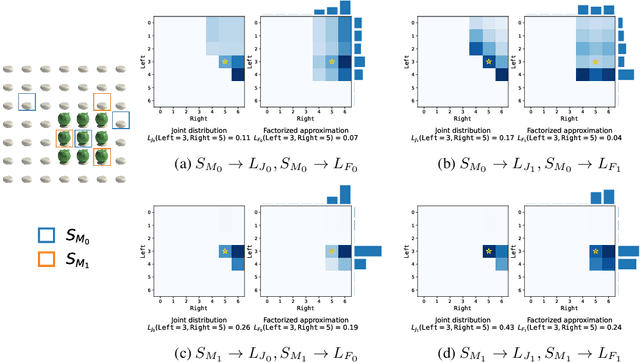
Providing examples is one of the most common way for end-users to interact with program synthesizers. However, program synthesis systems assume that examples consistent with the program are chosen at random, and do not exploit the fact that users choose examples pragmatically. Prior work modeled program synthesis as pragmatic communication, but required an inefficient enumeration of the entire program space. In this paper, we show that it is possible to build a program synthesizer that is both pragmatic and efficient by approximating the joint distribution of programs with a product of independent factors, and performing pragmatic inference on each factor separately. This factored distribution approximates the exact joint distribution well when the examples are given pragmatically, and is compatible with a basic neuro-symbolic program synthesis algorithm. Surprisingly, we find that the synthesizer assuming a factored approximation performs better than a synthesizer assuming an exact joint distribution when evaluated on natural human inputs. This suggests that humans may be assuming a factored distribution while communicating programs.
Sample-efficient Linguistic Generalizations through Program Synthesis: Experiments with Phonology Problems
Jun 11, 2021

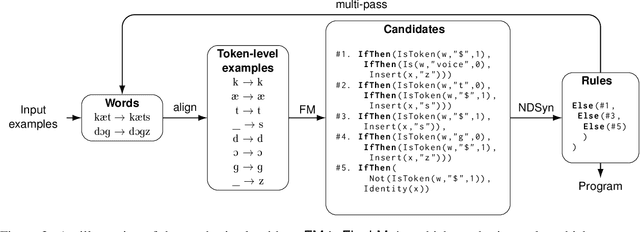

Neural models excel at extracting statistical patterns from large amounts of data, but struggle to learn patterns or reason about language from only a few examples. In this paper, we ask: Can we learn explicit rules that generalize well from only a few examples? We explore this question using program synthesis. We develop a synthesis model to learn phonology rules as programs in a domain-specific language. We test the ability of our models to generalize from few training examples using our new dataset of problems from the Linguistics Olympiad, a challenging set of tasks that require strong linguistic reasoning ability. In addition to being highly sample-efficient, our approach generates human-readable programs, and allows control over the generalizability of the learnt programs.