 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProspective Compression in Human Abstraction Learning
May 11, 2026A core challenge in program synthesis is online library learning: the incremental acquisition of reusable abstractions under uncertainty about future task demands. Existing algorithms treat library learning as retrospective compression over a static task distribution, where the learned library is determined by the corpus of past tasks. However, real-world learning domains are often non-stationary, with tasks arising from a generative process that evolves over time. We propose and test the hypothesis that in non-stationary domains human library learning selects abstractions prospectively: targeting compression of future tasks. We study this question using the Pattern Builder Task, a visual program synthesis paradigm in which participants construct increasingly complex geometric patterns from a small set of primitives, transformations, and custom helpers that carry forward across trials. Using this task, we conduct two experiments with complementary latent curricula, designed to dissociate between behaviors consistent with prospective compression, and alternative library learning accounts. Using six computational models spanning online library learning strategies, we show that human abstraction behavior reflects sensitivity to latent, non-stationary structure in the task-generating process. This behavior is consistent with prospective compression, and cannot be captured by existing retrospective compression-based algorithms, or inductive biases modeled by LLM-based program synthesis.
Bongards at the Boundary of Perception and Reasoning: Programs or Language?
Feb 03, 2026Vision-Language Models (VLMs) have made great strides in everyday visual tasks, such as captioning a natural image, or answering commonsense questions about such images. But humans possess the puzzling ability to deploy their visual reasoning abilities in radically new situations, a skill rigorously tested by the classic set of visual reasoning challenges known as the Bongard problems. We present a neurosymbolic approach to solving these problems: given a hypothesized solution rule for a Bongard problem, we leverage LLMs to generate parameterized programmatic representations for the rule and perform parameter fitting using Bayesian optimization. We evaluate our method on classifying Bongard problem images given the ground truth rule, as well as on solving the problems from scratch.
mrCAD: Multimodal Refinement of Computer-aided Designs
Apr 28, 2025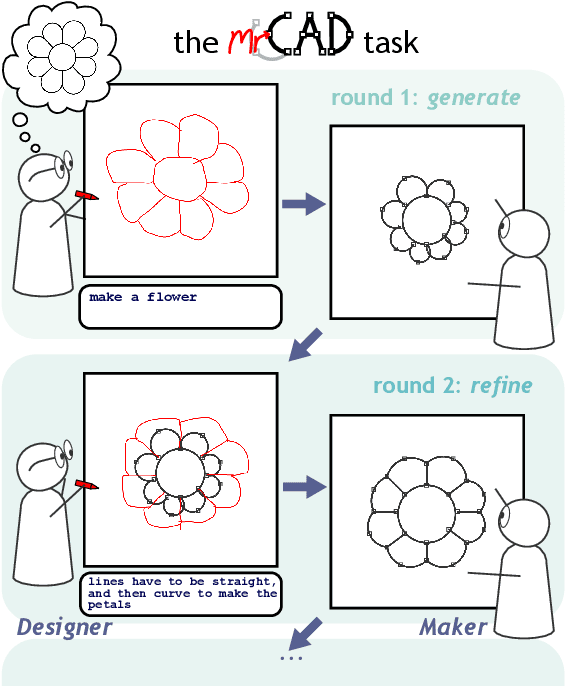
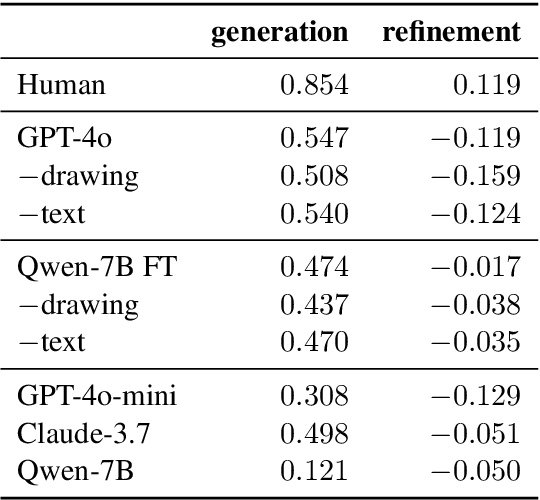
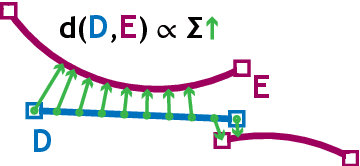
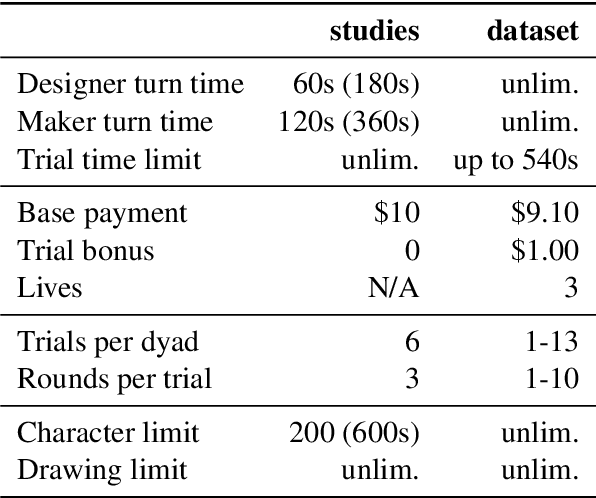
A key feature of human collaboration is the ability to iteratively refine the concepts we have communicated. In contrast, while generative AI excels at the \textit{generation} of content, it often struggles to make specific language-guided \textit{modifications} of its prior outputs. To bridge the gap between how humans and machines perform edits, we present mrCAD, a dataset of multimodal instructions in a communication game. In each game, players created computer aided designs (CADs) and refined them over several rounds to match specific target designs. Only one player, the Designer, could see the target, and they must instruct the other player, the Maker, using text, drawing, or a combination of modalities. mrCAD consists of 6,082 communication games, 15,163 instruction-execution rounds, played between 1,092 pairs of human players. We analyze the dataset and find that generation and refinement instructions differ in their composition of drawing and text. Using the mrCAD task as a benchmark, we find that state-of-the-art VLMs are better at following generation instructions than refinement instructions. These results lay a foundation for analyzing and modeling a multimodal language of refinement that is not represented in previous datasets.
Combining Induction and Transduction for Abstract Reasoning
Nov 04, 2024When learning an input-output mapping from very few examples, is it better to first infer a latent function that explains the examples, or is it better to directly predict new test outputs, e.g. using a neural network? We study this question on ARC, a highly diverse dataset of abstract reasoning tasks. We train neural models for induction (inferring latent functions) and transduction (directly predicting the test output for a given test input). Our models are trained on synthetic data generated by prompting LLMs to produce Python code specifying a function to be inferred, plus a stochastic subroutine for generating inputs to that function. We find inductive and transductive models solve very different problems, despite training on the same problems, and despite sharing the same neural architecture.
CadVLM: Bridging Language and Vision in the Generation of Parametric CAD Sketches
Sep 26, 2024



Parametric Computer-Aided Design (CAD) is central to contemporary mechanical design. However, it encounters challenges in achieving precise parametric sketch modeling and lacks practical evaluation metrics suitable for mechanical design. We harness the capabilities of pre-trained foundation models, renowned for their successes in natural language processing and computer vision, to develop generative models specifically for CAD. These models are adept at understanding complex geometries and design reasoning, a crucial advancement in CAD technology. In this paper, we propose CadVLM, an end-to-end vision language model for CAD generation. Our approach involves adapting pre-trained foundation models to manipulate engineering sketches effectively, integrating both sketch primitive sequences and sketch images. Extensive experiments demonstrate superior performance on multiple CAD sketch generation tasks such as CAD autocompletion, CAD autoconstraint, and image conditional generation. To our knowledge, this is the first instance of a multimodal Large Language Model (LLM) being successfully applied to parametric CAD generation, representing a pioneering step in the field of computer-aided mechanical design.
InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Jul 08, 2024Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
DiffVL: Scaling Up Soft Body Manipulation using Vision-Language Driven Differentiable Physics
Dec 11, 2023


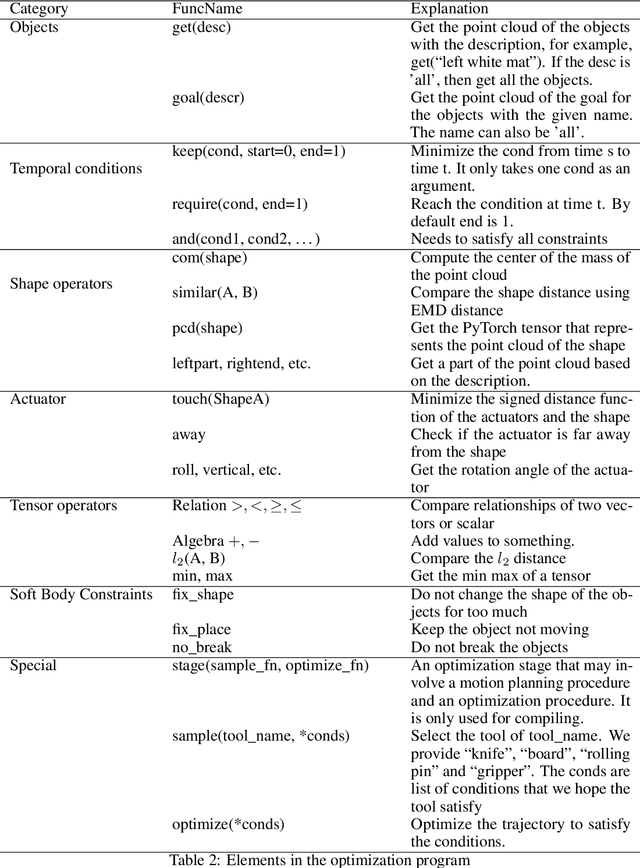
Combining gradient-based trajectory optimization with differentiable physics simulation is an efficient technique for solving soft-body manipulation problems. Using a well-crafted optimization objective, the solver can quickly converge onto a valid trajectory. However, writing the appropriate objective functions requires expert knowledge, making it difficult to collect a large set of naturalistic problems from non-expert users. We introduce DiffVL, a method that enables non-expert users to communicate soft-body manipulation tasks -- a combination of vision and natural language, given in multiple stages -- that can be readily leveraged by a differential physics solver. We have developed GUI tools that enable non-expert users to specify 100 tasks inspired by real-life soft-body manipulations from online videos, which we'll make public. We leverage large language models to translate task descriptions into machine-interpretable optimization objectives. The optimization objectives can help differentiable physics solvers to solve these long-horizon multistage tasks that are challenging for previous baselines.
Generating Pragmatic Examples to Train Neural Program Synthesizers
Nov 09, 2023Programming-by-example is the task of synthesizing a program that is consistent with a set of user-provided input-output examples. As examples are often an under-specification of one's intent, a good synthesizer must choose the intended program from the many that are consistent with the given set of examples. Prior work frames program synthesis as a cooperative game between a listener (that synthesizes programs) and a speaker (a user choosing examples), and shows that models of computational pragmatic inference are effective in choosing the user intended programs. However, these models require counterfactual reasoning over a large set of programs and examples, which is infeasible in realistic program spaces. In this paper, we propose a novel way to amortize this search with neural networks. We sample pairs of programs and examples via self-play between listener and speaker models, and use pragmatic inference to choose informative training examples from this sample.We then use the informative dataset to train models to improve the synthesizer's ability to disambiguate user-provided examples without human supervision. We validate our method on the challenging task of synthesizing regular expressions from example strings, and find that our method (1) outperforms models trained without choosing pragmatic examples by 23% (a 51% relative increase) (2) matches the performance of supervised learning on a dataset of pragmatic examples provided by humans, despite using no human data in training.
Learning a Hierarchical Planner from Humans in Multiple Generations
Oct 17, 2023A typical way in which a machine acquires knowledge from humans is by programming. Compared to learning from demonstrations or experiences, programmatic learning allows the machine to acquire a novel skill as soon as the program is written, and, by building a library of programs, a machine can quickly learn how to perform complex tasks. However, as programs often take their execution contexts for granted, they are brittle when the contexts change, making it difficult to adapt complex programs to new contexts. We present natural programming, a library learning system that combines programmatic learning with a hierarchical planner. Natural programming maintains a library of decompositions, consisting of a goal, a linguistic description of how this goal decompose into sub-goals, and a concrete instance of its decomposition into sub-goals. A user teaches the system via curriculum building, by identifying a challenging yet not impossible goal along with linguistic hints on how this goal may be decomposed into sub-goals. The system solves for the goal via hierarchical planning, using the linguistic hints to guide its probability distribution in proposing the right plans. The system learns from this interaction by adding newly found decompositions in the successful search into its library. Simulated studies and a human experiment (n=360) on a controlled environment demonstrate that natural programming can robustly compose programs learned from different users and contexts, adapting faster and solving more complex tasks when compared to programmatic baselines.
Hypothesis Search: Inductive Reasoning with Language Models
Sep 11, 2023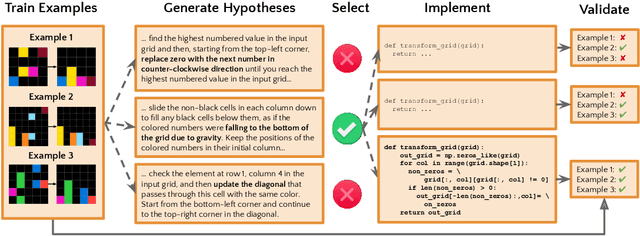

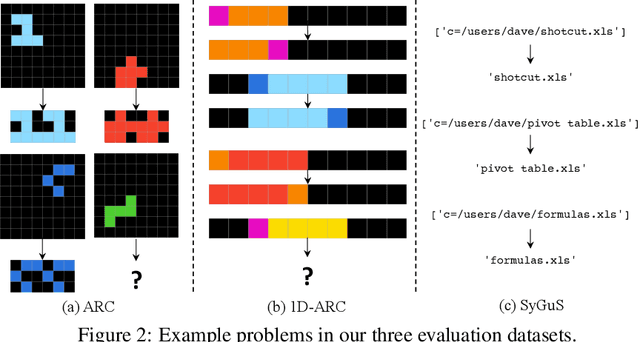
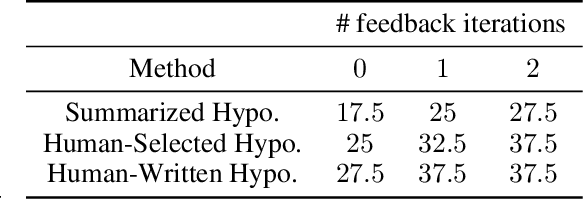
Inductive reasoning is a core problem-solving capacity: humans can identify underlying principles from a few examples, which can then be robustly generalized to novel scenarios. Recent work has evaluated large language models (LLMs) on inductive reasoning tasks by directly prompting them yielding "in context learning." This can work well for straightforward inductive tasks, but performs very poorly on more complex tasks such as the Abstraction and Reasoning Corpus (ARC). In this work, we propose to improve the inductive reasoning ability of LLMs by generating explicit hypotheses at multiple levels of abstraction: we prompt the LLM to propose multiple abstract hypotheses about the problem, in natural language, then implement the natural language hypotheses as concrete Python programs. These programs can be directly verified by running on the observed examples and generalized to novel inputs. Because of the prohibitive cost of generation with state-of-the-art LLMs, we consider a middle step to filter the set of hypotheses that will be implemented into programs: we either ask the LLM to summarize into a smaller set of hypotheses, or ask human annotators to select a subset of the hypotheses. We verify our pipeline's effectiveness on the ARC visual inductive reasoning benchmark, its variant 1D-ARC, and string transformation dataset SyGuS. On a random 40-problem subset of ARC, our automated pipeline using LLM summaries achieves 27.5% accuracy, significantly outperforming the direct prompting baseline (accuracy of 12.5%). With the minimal human input of selecting from LLM-generated candidates, the performance is boosted to 37.5%. (And we argue this is a lower bound on the performance of our approach without filtering.) Our ablation studies show that abstract hypothesis generation and concrete program representations are both beneficial for LLMs to perform inductive reasoning tasks.