 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAA-X: Unified Localized Artifact Attention for Quality-Agnostic and Generalizable Face Forgery Detection
Apr 05, 2026In this paper, we propose Localized Artifact Attention X (LAA-X), a novel deepfake detection framework that is both robust to high-quality forgeries and capable of generalizing to unseen manipulations. Existing approaches typically rely on binary classifiers coupled with implicit attention mechanisms, which often fail to generalize beyond known manipulations. In contrast, LAA-X introduces an explicit attention strategy based on a multi-task learning framework combined with blending-based data synthesis. Auxiliary tasks are designed to guide the model toward localized, artifact-prone (i.e., vulnerable) regions. The proposed framework is compatible with both CNN and transformer backbones, resulting in two different versions, namely, LAA-Net and LAA-Former, respectively. Despite being trained only on real and pseudo-fake samples, LAA-X competes with state-of-the-art methods across multiple benchmarks. Code and pre-trained weights for LAA-Net\footnote{https://github.com/10Ring/LAA-Net} and LAA-Former\footnote{https://github.com/10Ring/LAA-Former} are publicly available.
VirDA: Reusing Backbone for Unsupervised Domain Adaptation with Visual Reprogramming
Oct 02, 2025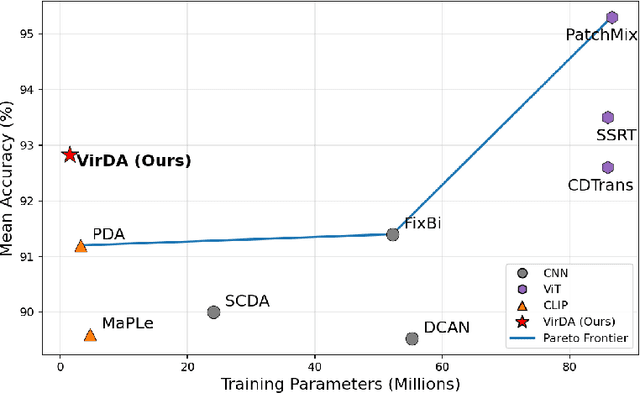
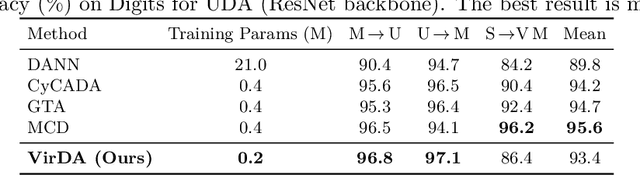
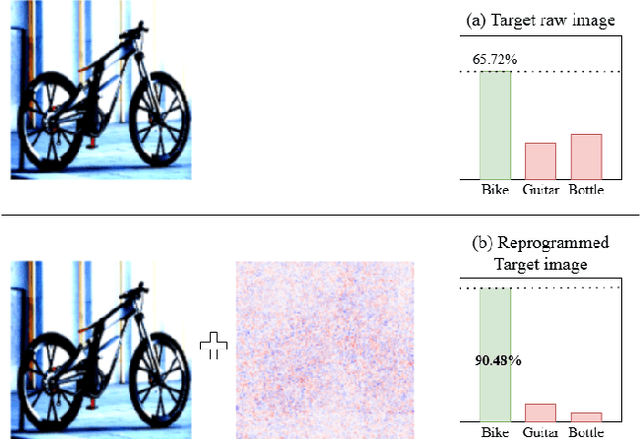
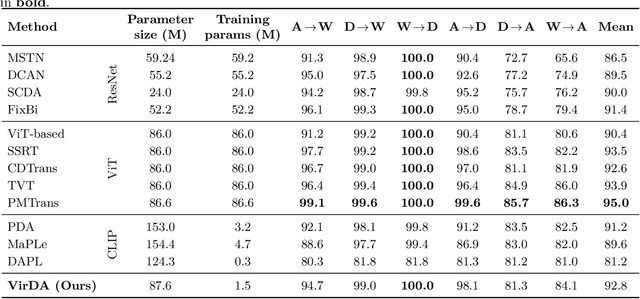
Existing UDA pipelines fine-tune already well-trained backbone parameters for every new source-and-target pair, resulting in the number of training parameters and storage memory growing linearly with each new pair, and also preventing the reuse of these well-trained backbone parameters. Inspired by recent implications that existing backbones have textural biases, we propose making use of domain-specific textural bias for domain adaptation via visual reprogramming, namely VirDA.Instead of fine-tuning the full backbone, VirDA prepends a domain-specific visual reprogramming layer to the backbone. This layer produces visual prompts that act as an added textural bias to the input image, adapting its ``style'' to a target domain. To optimize these visual reprogramming layers, we use multiple objective functions that optimize the intra- and inter-domain distribution differences when domain-adapting visual prompts are applied. This process does not require modifying the backbone parameters, allowing the same backbone to be reused across different domains. We evaluate VirDA on Office-31 and obtain 92.8% mean accuracy with only 1.5M trainable parameters. VirDA surpasses PDA, the state-of-the-art parameter-efficient UDA baseline, by +1.6% accuracy while using just 46% of its parameters. Compared with full-backbone fine-tuning, VirDA outperforms CDTrans and FixBi by +0.2% and +1.4%, respectively, while requiring only 1.7% and 2.8% of their trainable parameters. Relative to the strongest current methods (PMTrans and TVT), VirDA uses ~1.7% of their parameters and trades off only 2.2% and 1.1% accuracy, respectively.
The NazoNazo Benchmark: A Cost-Effective and Extensible Test of Insight-Based Reasoning in LLMs
Sep 18, 2025Benchmark saturation and contamination undermine confidence in LLM evaluation. We present Nazonazo, a cost-effective and extensible benchmark built from Japanese children's riddles to test insight-based reasoning. Items are short (mostly one sentence), require no specialized domain knowledge, and can be generated at scale, enabling rapid refresh of blind sets when leakage is suspected. We evaluate 38 frontier models and 126 adults on 120 riddles. No model except for GPT-5 is comparable to human performance, which achieves a 52.9% mean accuracy. Model comparison on extended 201 items shows that reasoning models significantly outperform non-reasoning peers, while model size shows no reliable association with accuracy. Beyond aggregate accuracy, an informal candidate-tracking analysis of thought logs reveals many cases of verification failure: models often produce the correct solution among intermediate candidates yet fail to select it as the final answer, which we illustrate with representative examples observed in multiple models. Nazonazo thus offers a cost-effective, scalable, and easily renewable benchmark format that addresses the current evaluation crisis while also suggesting a recurrent meta-cognitive weakness, providing clear targets for future control and calibration methods.
Vulnerability-Aware Spatio-Temporal Learning for Generalizable and Interpretable Deepfake Video Detection
Jan 02, 2025



Detecting deepfake videos is highly challenging due to the complex intertwined spatial and temporal artifacts in forged sequences. Most recent approaches rely on binary classifiers trained on both real and fake data. However, such methods may struggle to focus on important artifacts, which can hinder their generalization capability. Additionally, these models often lack interpretability, making it difficult to understand how predictions are made. To address these issues, we propose FakeSTormer, offering two key contributions. First, we introduce a multi-task learning framework with additional spatial and temporal branches that enable the model to focus on subtle spatio-temporal artifacts. These branches also provide interpretability by highlighting video regions that may contain artifacts. Second, we propose a video-level data synthesis algorithm that generates pseudo-fake videos with subtle artifacts, providing the model with high-quality samples and ground truth data for our spatial and temporal branches. Extensive experiments on several challenging benchmarks demonstrate the competitiveness of our approach compared to recent state-of-the-art methods. The code is available at https://github.com/10Ring/FakeSTormer.
Combining Induction and Transduction for Abstract Reasoning
Nov 04, 2024When learning an input-output mapping from very few examples, is it better to first infer a latent function that explains the examples, or is it better to directly predict new test outputs, e.g. using a neural network? We study this question on ARC, a highly diverse dataset of abstract reasoning tasks. We train neural models for induction (inferring latent functions) and transduction (directly predicting the test output for a given test input). Our models are trained on synthetic data generated by prompting LLMs to produce Python code specifying a function to be inferred, plus a stochastic subroutine for generating inputs to that function. We find inductive and transductive models solve very different problems, despite training on the same problems, and despite sharing the same neural architecture.
FakeFormer: Efficient Vulnerability-Driven Transformers for Generalisable Deepfake Detection
Oct 29, 2024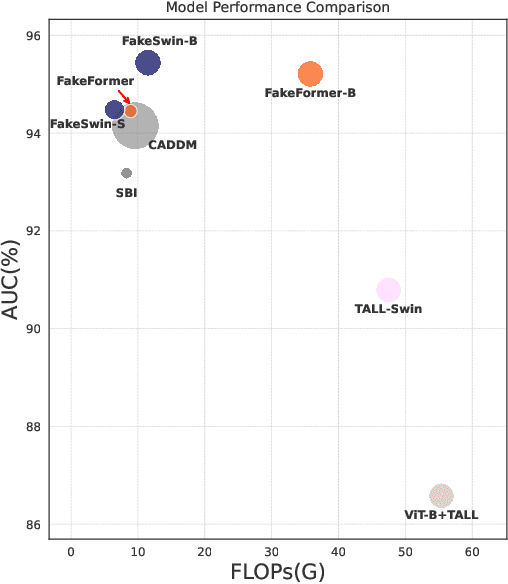

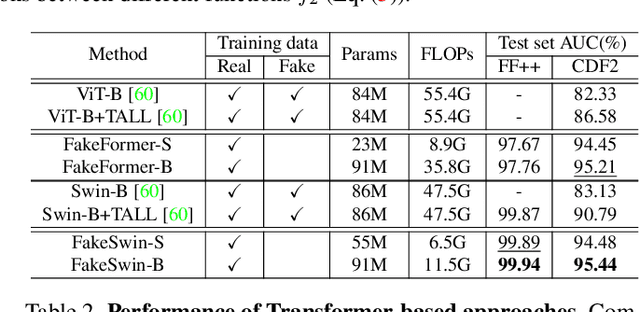
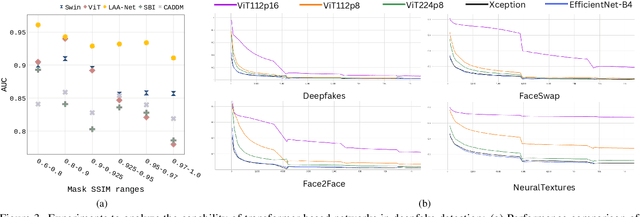
Recently, Vision Transformers (ViTs) have achieved unprecedented effectiveness in the general domain of image classification. Nonetheless, these models remain underexplored in the field of deepfake detection, given their lower performance as compared to Convolution Neural Networks (CNNs) in that specific context. In this paper, we start by investigating why plain ViT architectures exhibit a suboptimal performance when dealing with the detection of facial forgeries. Our analysis reveals that, as compared to CNNs, ViT struggles to model localized forgery artifacts that typically characterize deepfakes. Based on this observation, we propose a deepfake detection framework called FakeFormer, which extends ViTs to enforce the extraction of subtle inconsistency-prone information. For that purpose, an explicit attention learning guided by artifact-vulnerable patches and tailored to ViTs is introduced. Extensive experiments are conducted on diverse well-known datasets, including FF++, Celeb-DF, WildDeepfake, DFD, DFDCP, and DFDC. The results show that FakeFormer outperforms the state-of-the-art in terms of generalization and computational cost, without the need for large-scale training datasets. The code is available at \url{https://github.com/10Ring/FakeFormer}.
KinDEL: DNA-Encoded Library Dataset for Kinase Inhibitors
Oct 11, 2024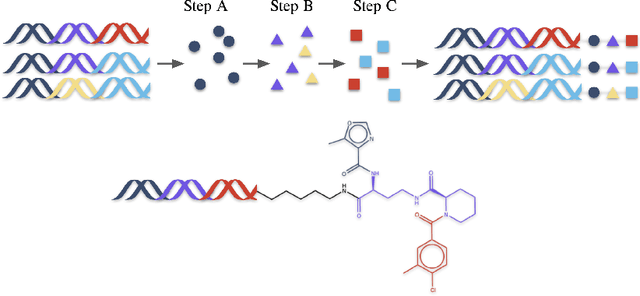

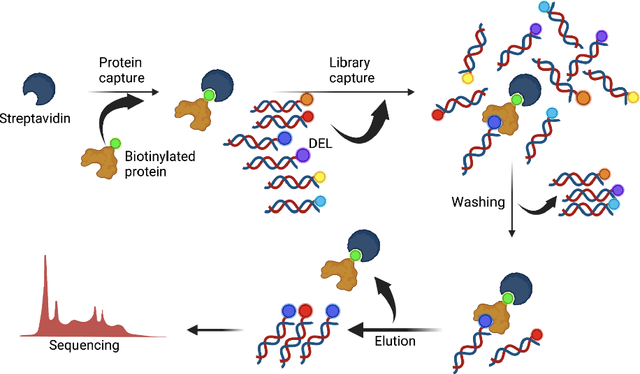
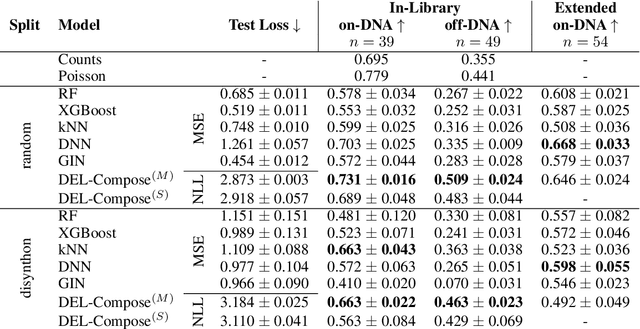
DNA-Encoded Libraries (DEL) are combinatorial small molecule libraries that offer an efficient way to characterize diverse chemical spaces. Selection experiments using DELs are pivotal to drug discovery efforts, enabling high-throughput screens for hit finding. However, limited availability of public DEL datasets hinders the advancement of computational techniques designed to process such data. To bridge this gap, we present KinDEL, one of the first large, publicly available DEL datasets on two kinases: Mitogen-Activated Protein Kinase 14 (MAPK14) and Discoidin Domain Receptor Tyrosine Kinase 1 (DDR1). Interest in this data modality is growing due to its ability to generate extensive supervised chemical data that densely samples around select molecular structures. Demonstrating one such application of the data, we benchmark different machine learning techniques to develop predictive models for hit identification; in particular, we highlight recent structure-based probabilistic approaches. Finally, we provide biophysical assay data, both on- and off-DNA, to validate our models on a smaller subset of molecules. Data and code for our benchmarks can be found at: https://github.com/insitro/kindel.
Evaluating Program Repair with Semantic-Preserving Transformations: A Naturalness Assessment
Feb 19, 2024



In this paper, we investigate the naturalness of semantic-preserving transformations and their impacts on the evaluation of NPR. To achieve this, we conduct a two-stage human study, including (1) interviews with senior software developers to establish the first concrete criteria for assessing the naturalness of code transformations and (2) a survey involving 10 developers to assess the naturalness of 1178 transformations, i.e., pairs of original and transformed programs, applied to 225 real-world bugs. Our findings reveal that nearly 60% and 20% of these transformations are considered natural and unnatural with substantially high agreement among human annotators. Furthermore, the unnatural code transformations introduce a 25.2% false alarm rate on robustness of five well-known NPR systems. Additionally, the performance of the NPR systems drops notably when evaluated using natural transformations, i.e., a drop of up to 22.9% and 23.6% in terms of the numbers of correct and plausible patches generated by these systems. These results highlight the importance of robustness testing by considering naturalness of code transformations, which unveils true effectiveness of NPR systems. Finally, we conduct an exploration study on automating the assessment of naturalness of code transformations by deriving a new naturalness metric based on Cross-Entropy. Based on our naturalness metric, we can effectively assess naturalness for code transformations automatically with an AUC of 0.7.
LAA-Net: Localized Artifact Attention Network for High-Quality Deepfakes Detection
Jan 24, 2024



This paper introduces a novel approach for high-quality deepfake detection called Localized Artifact Attention Network (LAA-Net). Existing methods for high-quality deepfake detection are mainly based on a supervised binary classifier coupled with an implicit attention mechanism. As a result, they do not generalize well to unseen manipulations. To handle this issue, two main contributions are made. First, an explicit attention mechanism within a multi-task learning framework is proposed. By combining heatmap-based and self-consistency attention strategies, LAA-Net is forced to focus on a few small artifact-prone vulnerable regions. Second, an Enhanced Feature Pyramid Network (E-FPN) is proposed as a simple and effective mechanism for spreading discriminative low-level features into the final feature output, with the advantage of limiting redundancy. Experiments performed on several benchmarks show the superiority of our approach in terms of Area Under the Curve (AUC) and Average Precision (AP). The code will be released soon.
Inferring Properties of Graph Neural Networks
Jan 08, 2024



We propose GNNInfer, the first automatic property inference technique for GNNs. To tackle the challenge of varying input structures in GNNs, GNNInfer first identifies a set of representative influential structures that contribute significantly towards the prediction of a GNN. Using these structures, GNNInfer converts each pair of an influential structure and the GNN to their equivalent FNN and then leverages existing property inference techniques to effectively capture properties of the GNN that are specific to the influential structures. GNNINfer then generalizes the captured properties to any input graphs that contain the influential structures. Finally, GNNInfer improves the correctness of the inferred properties by building a model (either a decision tree or linear regression) that estimates the deviation of GNN output from the inferred properties given full input graphs. The learned model helps GNNInfer extend the inferred properties with constraints to the input and output of the GNN, obtaining stronger properties that hold on full input graphs. Our experiments show that GNNInfer is effective in inferring likely properties of popular real-world GNNs, and more importantly, these inferred properties help effectively defend against GNNs' backdoor attacks. In particular, out of the 13 ground truth properties, GNNInfer re-discovered 8 correct properties and discovered likely correct properties that approximate the remaining 5 ground truth properties. Using properties inferred by GNNInfer to defend against the state-of-the-art backdoor attack technique on GNNs, namely UGBA, experiments show that GNNInfer's defense success rate is up to 30 times better than existing baselines.