 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIXPOSE: Mobile Malware Detection via Intention-Behaviour Discrepancy Analysis
Dec 16, 2025



We introduce UIXPOSE, a source-code-agnostic framework that operates on both compiled and open-source apps. This framework applies Intention Behaviour Alignment (IBA) to mobile malware analysis, aligning UI-inferred intent with runtime semantics. Previous work either infers intent statically, e.g., permission-centric, or widget-level or monitors coarse dynamic signals (endpoints, partial resource usage) that miss content and context. UIXPOSE infers an intent vector from each screen using vision-language models and knowledge structures and combines decoded network payloads, heap/memory signals, and resource utilisation traces into a behaviour vector. Their alignment, calculated at runtime, can both detect misbehaviour and highlight exploration of behaviourally rich paths. In three real-world case studies, UIXPOSE reveals covert exfiltration and hidden background activity that evade metadata-only baselines, demonstrating how IBA improves dynamic detection.
A Formally Verified Robustness Certifier for Neural Networks (Extended Version)
May 11, 2025



Neural networks are often susceptible to minor perturbations in input that cause them to misclassify. A recent solution to this problem is the use of globally-robust neural networks, which employ a function to certify that the classification of an input cannot be altered by such a perturbation. Outputs that pass this test are called certified robust. However, to the authors' knowledge, these certification functions have not yet been verified at the implementation level. We demonstrate how previous unverified implementations are exploitably unsound in certain circumstances. Moreover, they often rely on approximation-based algorithms, such as power iteration, that (perhaps surprisingly) do not guarantee soundness. To provide assurance that a given output is robust, we implemented and formally verified a certification function for globally-robust neural networks in Dafny. We describe the program, its specifications, and the important design decisions taken for its implementation and verification, as well as our experience applying it in practice.
Semantic-guided Search for Efficient Program Repair with Large Language Models
Oct 22, 2024



In this paper, we first show that increases in beam size of even just small-sized LLM (1B-7B parameters) require an extensive GPU resource consumption, leading to up to 80% of recurring crashes due to memory overloads in LLM-based APR. Seemingly simple solutions to reduce memory consumption are (1) to quantize LLM models, i.e., converting the weights of a LLM from high-precision values to lower-precision ones. and (2) to make beam search sequential, i.e., forwarding each beam through the model sequentially and then concatenate them back into a single model output. However, we show that these approaches still do not work via both theoretical analysis and experiments. To address this, we introduce FLAMES, a novel LLM-based APR technique that employs semantic-guided patch generation to enhance repair effectiveness and memory efficiency. Unlike conventional methods that rely on beam search, FLAMES utilizes greedy decoding to enhance memory efficiency while steering the search to more potentially good repair candidates via a semantic-guided best-first search algorithm. At each decoding step, FLAMES uses semantic feedback from test validation such as the number of passing and failing test cases to select the most promising token to explore further. Our empirical evaluation on the Defects4J and HumanEval-Java datasets shows that FLAMES not only substantially reduces memory consumption by up to 83% compared to conventional LLM-based APR, but also accelerates the repair process. Remarkably, FLAMES successfully generated 133 and 103 correct fixes for 333 and 163 bugs in the Defects4J and HumanEval-Java datasets, respectively. This suggests that FLAMES is not only more efficient but also outperforms state-of-the-art techniques, fixing at least 10 and 11 more bugs than SOTA baselines in the Defects4J and HumanEval-Java datasets, respectively.
Evaluating Program Repair with Semantic-Preserving Transformations: A Naturalness Assessment
Feb 19, 2024



In this paper, we investigate the naturalness of semantic-preserving transformations and their impacts on the evaluation of NPR. To achieve this, we conduct a two-stage human study, including (1) interviews with senior software developers to establish the first concrete criteria for assessing the naturalness of code transformations and (2) a survey involving 10 developers to assess the naturalness of 1178 transformations, i.e., pairs of original and transformed programs, applied to 225 real-world bugs. Our findings reveal that nearly 60% and 20% of these transformations are considered natural and unnatural with substantially high agreement among human annotators. Furthermore, the unnatural code transformations introduce a 25.2% false alarm rate on robustness of five well-known NPR systems. Additionally, the performance of the NPR systems drops notably when evaluated using natural transformations, i.e., a drop of up to 22.9% and 23.6% in terms of the numbers of correct and plausible patches generated by these systems. These results highlight the importance of robustness testing by considering naturalness of code transformations, which unveils true effectiveness of NPR systems. Finally, we conduct an exploration study on automating the assessment of naturalness of code transformations by deriving a new naturalness metric based on Cross-Entropy. Based on our naturalness metric, we can effectively assess naturalness for code transformations automatically with an AUC of 0.7.
Symbol Correctness in Deep Neural Networks Containing Symbolic Layers
Feb 06, 2024


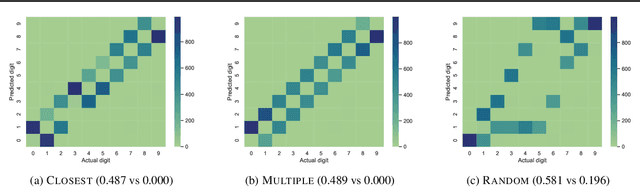
To handle AI tasks that combine perception and logical reasoning, recent work introduces Neurosymbolic Deep Neural Networks (NS-DNNs), which contain -- in addition to traditional neural layers -- symbolic layers: symbolic expressions (e.g., SAT formulas, logic programs) that are evaluated by symbolic solvers during inference. We identify and formalize an intuitive, high-level principle that can guide the design and analysis of NS-DNNs: symbol correctness, the correctness of the intermediate symbols predicted by the neural layers with respect to a (generally unknown) ground-truth symbolic representation of the input data. We demonstrate that symbol correctness is a necessary property for NS-DNN explainability and transfer learning (despite being in general impossible to train for). Moreover, we show that the framework of symbol correctness provides a precise way to reason and communicate about model behavior at neural-symbolic boundaries, and gives insight into the fundamental tradeoffs faced by NS-DNN training algorithms. In doing so, we both identify significant points of ambiguity in prior work, and provide a framework to support further NS-DNN developments.
State Selection Algorithms and Their Impact on The Performance of Stateful Network Protocol Fuzzing
Jan 07, 2022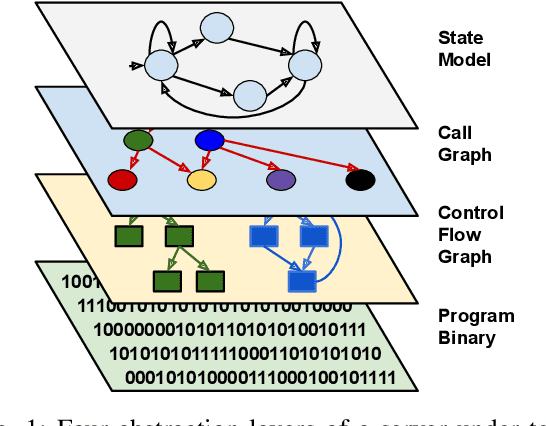
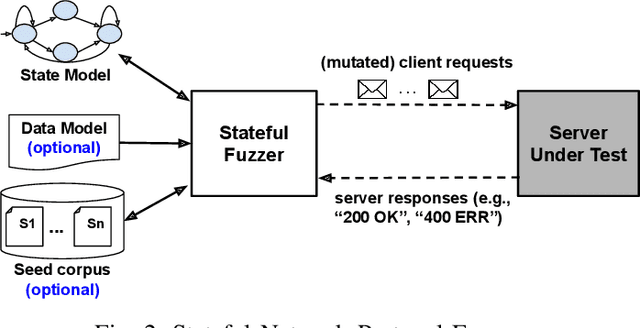
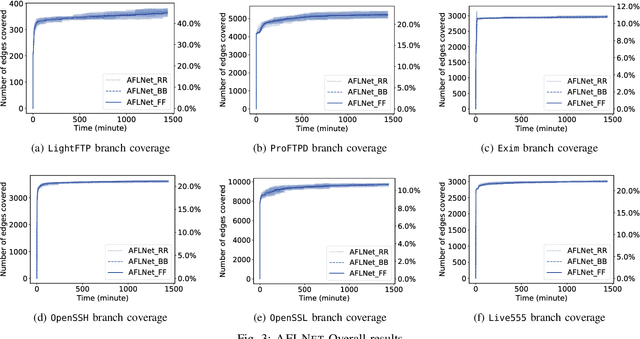

The statefulness property of network protocol implementations poses a unique challenge for testing and verification techniques, including Fuzzing. Stateful fuzzers tackle this challenge by leveraging state models to partition the state space and assist the test generation process. Since not all states are equally important and fuzzing campaigns have time limits, fuzzers need effective state selection algorithms to prioritize progressive states over others. Several state selection algorithms have been proposed but they were implemented and evaluated separately on different platforms, making it hard to achieve conclusive findings. In this work, we evaluate an extensive set of state selection algorithms on the same fuzzing platform that is AFLNet, a state-of-the-art fuzzer for network servers. The algorithm set includes existing ones supported by AFLNet and our novel and principled algorithm called AFLNetLegion. The experimental results on the ProFuzzBench benchmark show that (i) the existing state selection algorithms of AFLNet achieve very similar code coverage, (ii) AFLNetLegion clearly outperforms these algorithms in selected case studies, but (iii) the overall improvement appears insignificant. These are unexpected yet interesting findings. We identify problems and share insights that could open opportunities for future research on this topic.
Legion: Best-First Concolic Testing
Feb 15, 2020

Legion is a grey-box concolic tool that aims to balance the complementary nature of fuzzing and symbolic execution to achieve the best of both worlds. It proposes a variation of Monte Carlo tree search (MCTS) that formulates program exploration as sequential decisionmaking under uncertainty guided by the best-first search strategy. It relies on approximate path-preserving fuzzing, a novel instance of constrained random testing, which quickly generates many diverse inputs that likely target program parts of interest. In Test-Comp 2020, the prototype performed within 90% of the best score in 9 of 22 categories.