 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerish or Flourish? A Holistic Evaluation of Large Language Models for Code Generation in Functional Programming
Jan 05, 2026Functional programming provides strong foundations for developing reliable and secure software systems, yet its adoption remains not widespread due to the steep learning curve. Recent advances in Large Language Models (LLMs) for code generation present new opportunities to lower these barriers. However, extensive evaluations of LLMs largely focus on imperative programming languages, and their capabilities in functional programming languages (FP) remain underexplored. To address this gap, we introduce FPEval, a holistic evaluation framework built on FPBench, a new benchmark of 721 programming tasks across three difficulty levels on three mainstream FP languages: Haskell, Ocaml and Scala. FPEval provides compehensive evaluation infrastructures with both test validations with comprehensive test suites and static analysis tools to assess both functional correctness and code style and maintainability. Using this framework, we evaluate state-of-the-art LLMs, including GPT-3.5, GPT-4o, and GPT-5, for code generation in functional programming languages and Java as an imperative baseline. Our results demonstrate that LLM performance in functional programming improves substantially with model advancement; however, error rates remain significantly higher in purely functional languages (Haskell and OCaml) than in hybrid (Scala) or imperative (Java) languages. Moreover, LLMs frequently generate non-idiomatic functional code that follows imperative patterns, raising concerns about code style and long-term maintainability. Finally, we show that LLMs can partially self-repair both correctness and quality issues when provided with static analysis feedback and hand-crafted instructions for common types of issues.
DoorDet: Semi-Automated Multi-Class Door Detection Dataset via Object Detection and Large Language Models
Aug 11, 2025



Accurate detection and classification of diverse door types in floor plans drawings is critical for multiple applications, such as building compliance checking, and indoor scene understanding. Despite their importance, publicly available datasets specifically designed for fine-grained multi-class door detection remain scarce. In this work, we present a semi-automated pipeline that leverages a state-of-the-art object detector and a large language model (LLM) to construct a multi-class door detection dataset with minimal manual effort. Doors are first detected as a unified category using a deep object detection model. Next, an LLM classifies each detected instance based on its visual and contextual features. Finally, a human-in-the-loop stage ensures high-quality labels and bounding boxes. Our method significantly reduces annotation cost while producing a dataset suitable for benchmarking neural models in floor plan analysis. This work demonstrates the potential of combining deep learning and multimodal reasoning for efficient dataset construction in complex real-world domains.
From Empirical Evaluation to Context-Aware Enhancement: Repairing Regression Errors with LLMs
Jun 16, 2025

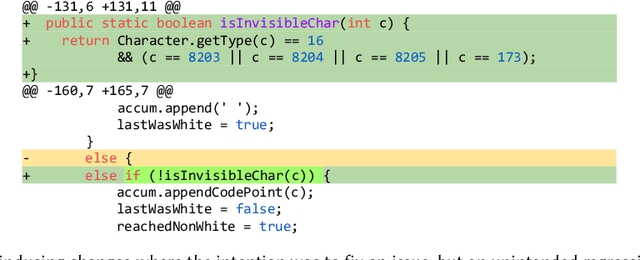
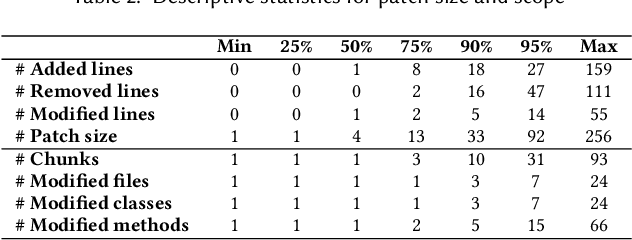
[...] Since then, various APR approaches, especially those leveraging the power of large language models (LLMs), have been rapidly developed to fix general software bugs. Unfortunately, the effectiveness of these advanced techniques in the context of regression bugs remains largely unexplored. This gap motivates the need for an empirical study evaluating the effectiveness of modern APR techniques in fixing real-world regression bugs. In this work, we conduct an empirical study of APR techniques on Java regression bugs. To facilitate our study, we introduce RegMiner4APR, a high-quality benchmark of Java regression bugs integrated into a framework designed to facilitate APR research. The current benchmark includes 99 regression bugs collected from 32 widely used real-world Java GitHub repositories. We begin by conducting an in-depth analysis of the benchmark, demonstrating its diversity and quality. Building on this foundation, we empirically evaluate the capabilities of APR to regression bugs by assessing both traditional APR tools and advanced LLM-based APR approaches. Our experimental results show that classical APR tools fail to repair any bugs, while LLM-based APR approaches exhibit promising potential. Motivated by these results, we investigate impact of incorporating bug-inducing change information into LLM-based APR approaches for fixing regression bugs. Our results highlight that this context-aware enhancement significantly improves the performance of LLM-based APR, yielding 1.8x more successful repairs compared to using LLM-based APR without such context.
Large Language Models for Computer-Aided Design: A Survey
May 13, 2025Large Language Models (LLMs) have seen rapid advancements in recent years, with models like ChatGPT and DeepSeek, showcasing their remarkable capabilities across diverse domains. While substantial research has been conducted on LLMs in various fields, a comprehensive review focusing on their integration with Computer-Aided Design (CAD) remains notably absent. CAD is the industry standard for 3D modeling and plays a vital role in the design and development of products across different industries. As the complexity of modern designs increases, the potential for LLMs to enhance and streamline CAD workflows presents an exciting frontier. This article presents the first systematic survey exploring the intersection of LLMs and CAD. We begin by outlining the industrial significance of CAD, highlighting the need for AI-driven innovation. Next, we provide a detailed overview of the foundation of LLMs. We also examine both closed-source LLMs as well as publicly available models. The core of this review focuses on the various applications of LLMs in CAD, providing a taxonomy of six key areas where these models are making considerable impact. Finally, we propose several promising future directions for further advancements, which offer vast opportunities for innovation and are poised to shape the future of CAD technology. Github: https://github.com/lichengzhanguom/LLMs-CAD-Survey-Taxonomy
Semantic-guided Search for Efficient Program Repair with Large Language Models
Oct 22, 2024



In this paper, we first show that increases in beam size of even just small-sized LLM (1B-7B parameters) require an extensive GPU resource consumption, leading to up to 80% of recurring crashes due to memory overloads in LLM-based APR. Seemingly simple solutions to reduce memory consumption are (1) to quantize LLM models, i.e., converting the weights of a LLM from high-precision values to lower-precision ones. and (2) to make beam search sequential, i.e., forwarding each beam through the model sequentially and then concatenate them back into a single model output. However, we show that these approaches still do not work via both theoretical analysis and experiments. To address this, we introduce FLAMES, a novel LLM-based APR technique that employs semantic-guided patch generation to enhance repair effectiveness and memory efficiency. Unlike conventional methods that rely on beam search, FLAMES utilizes greedy decoding to enhance memory efficiency while steering the search to more potentially good repair candidates via a semantic-guided best-first search algorithm. At each decoding step, FLAMES uses semantic feedback from test validation such as the number of passing and failing test cases to select the most promising token to explore further. Our empirical evaluation on the Defects4J and HumanEval-Java datasets shows that FLAMES not only substantially reduces memory consumption by up to 83% compared to conventional LLM-based APR, but also accelerates the repair process. Remarkably, FLAMES successfully generated 133 and 103 correct fixes for 333 and 163 bugs in the Defects4J and HumanEval-Java datasets, respectively. This suggests that FLAMES is not only more efficient but also outperforms state-of-the-art techniques, fixing at least 10 and 11 more bugs than SOTA baselines in the Defects4J and HumanEval-Java datasets, respectively.
Comparison of Static Application Security Testing Tools and Large Language Models for Repo-level Vulnerability Detection
Jul 23, 2024



Software vulnerabilities pose significant security challenges and potential risks to society, necessitating extensive efforts in automated vulnerability detection. There are two popular lines of work to address automated vulnerability detection. On one hand, Static Application Security Testing (SAST) is usually utilized to scan source code for security vulnerabilities, especially in industries. On the other hand, deep learning (DL)-based methods, especially since the introduction of large language models (LLMs), have demonstrated their potential in software vulnerability detection. However, there is no comparative study between SAST tools and LLMs, aiming to determine their effectiveness in vulnerability detection, understand the pros and cons of both SAST and LLMs, and explore the potential combination of these two families of approaches. In this paper, we compared 15 diverse SAST tools with 12 popular or state-of-the-art open-source LLMs in detecting software vulnerabilities from repositories of three popular programming languages: Java, C, and Python. The experimental results showed that SAST tools obtain low vulnerability detection rates with relatively low false positives, while LLMs can detect up 90\% to 100\% of vulnerabilities but suffer from high false positives. By further ensembling the SAST tools and LLMs, the drawbacks of both SAST tools and LLMs can be mitigated to some extent. Our analysis sheds light on both the current progress and future directions for software vulnerability detection.
VRDSynth: Synthesizing Programs for Multilingual Visually Rich Document Information Extraction
Jul 09, 2024
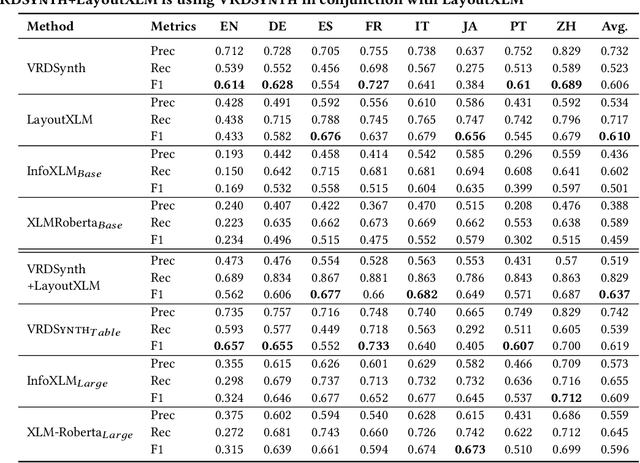

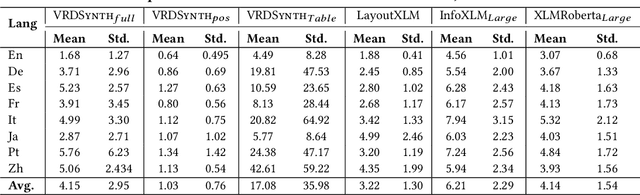
Businesses need to query visually rich documents (VRDs) like receipts, medical records, and insurance forms to make decisions. Existing techniques for extracting entities from VRDs struggle with new layouts or require extensive pre-training data. We introduce VRDSynth, a program synthesis method to automatically extract entity relations from multilingual VRDs without pre-training data. To capture the complexity of VRD domain, we design a domain-specific language (DSL) to capture spatial and textual relations to describe the synthesized programs. Along with this, we also derive a new synthesis algorithm utilizing frequent spatial relations, search space pruning, and a combination of positive, negative, and exclusive programs to improve coverage. We evaluate VRDSynth on the FUNSD and XFUND benchmarks for semantic entity linking, consisting of 1,592 forms in 8 languages. VRDSynth outperforms state-of-the-art pre-trained models (LayoutXLM, InfoXLMBase, and XLMRobertaBase) in 5, 6, and 7 out of 8 languages, respectively, improving the F1 score by 42% over LayoutXLM in English. To test the extensibility of the model, we further improve VRDSynth with automated table recognition, creating VRDSynth(Table), and compare it with extended versions of the pre-trained models, InfoXLM(Large) and XLMRoberta(Large). VRDSynth(Table) outperforms these baselines in 4 out of 8 languages and in average F1 score. VRDSynth also significantly reduces memory footprint (1M and 380MB vs. 1.48GB and 3GB for LayoutXLM) while maintaining similar time efficiency.
LEGION: Harnessing Pre-trained Language Models for GitHub Topic Recommendations with Distribution-Balance Loss
Mar 09, 2024



Open-source development has revolutionized the software industry by promoting collaboration, transparency, and community-driven innovation. Today, a vast amount of various kinds of open-source software, which form networks of repositories, is often hosted on GitHub - a popular software development platform. To enhance the discoverability of the repository networks, i.e., groups of similar repositories, GitHub introduced repository topics in 2017 that enable users to more easily explore relevant projects by type, technology, and more. It is thus crucial to accurately assign topics for each GitHub repository. Current methods for automatic topic recommendation rely heavily on TF-IDF for encoding textual data, presenting challenges in understanding semantic nuances. This paper addresses the limitations of existing techniques by proposing Legion, a novel approach that leverages Pre-trained Language Models (PTMs) for recommending topics for GitHub repositories. The key novelty of Legion is three-fold. First, Legion leverages the extensive capabilities of PTMs in language understanding to capture contextual information and semantic meaning in GitHub repositories. Second, Legion overcomes the challenge of long-tailed distribution, which results in a bias toward popular topics in PTMs, by proposing a Distribution-Balanced Loss (DB Loss) to better train the PTMs. Third, Legion employs a filter to eliminate vague recommendations, thereby improving the precision of PTMs. Our empirical evaluation on a benchmark dataset of real-world GitHub repositories shows that Legion can improve vanilla PTMs by up to 26% on recommending GitHubs topics. Legion also can suggest GitHub topics more precisely and effectively than the state-of-the-art baseline with an average improvement of 20% and 5% in terms of Precision and F1-score, respectively.
Evaluating Program Repair with Semantic-Preserving Transformations: A Naturalness Assessment
Feb 19, 2024



In this paper, we investigate the naturalness of semantic-preserving transformations and their impacts on the evaluation of NPR. To achieve this, we conduct a two-stage human study, including (1) interviews with senior software developers to establish the first concrete criteria for assessing the naturalness of code transformations and (2) a survey involving 10 developers to assess the naturalness of 1178 transformations, i.e., pairs of original and transformed programs, applied to 225 real-world bugs. Our findings reveal that nearly 60% and 20% of these transformations are considered natural and unnatural with substantially high agreement among human annotators. Furthermore, the unnatural code transformations introduce a 25.2% false alarm rate on robustness of five well-known NPR systems. Additionally, the performance of the NPR systems drops notably when evaluated using natural transformations, i.e., a drop of up to 22.9% and 23.6% in terms of the numbers of correct and plausible patches generated by these systems. These results highlight the importance of robustness testing by considering naturalness of code transformations, which unveils true effectiveness of NPR systems. Finally, we conduct an exploration study on automating the assessment of naturalness of code transformations by deriving a new naturalness metric based on Cross-Entropy. Based on our naturalness metric, we can effectively assess naturalness for code transformations automatically with an AUC of 0.7.
Inferring Properties of Graph Neural Networks
Jan 08, 2024



We propose GNNInfer, the first automatic property inference technique for GNNs. To tackle the challenge of varying input structures in GNNs, GNNInfer first identifies a set of representative influential structures that contribute significantly towards the prediction of a GNN. Using these structures, GNNInfer converts each pair of an influential structure and the GNN to their equivalent FNN and then leverages existing property inference techniques to effectively capture properties of the GNN that are specific to the influential structures. GNNINfer then generalizes the captured properties to any input graphs that contain the influential structures. Finally, GNNInfer improves the correctness of the inferred properties by building a model (either a decision tree or linear regression) that estimates the deviation of GNN output from the inferred properties given full input graphs. The learned model helps GNNInfer extend the inferred properties with constraints to the input and output of the GNN, obtaining stronger properties that hold on full input graphs. Our experiments show that GNNInfer is effective in inferring likely properties of popular real-world GNNs, and more importantly, these inferred properties help effectively defend against GNNs' backdoor attacks. In particular, out of the 13 ground truth properties, GNNInfer re-discovered 8 correct properties and discovered likely correct properties that approximate the remaining 5 ground truth properties. Using properties inferred by GNNInfer to defend against the state-of-the-art backdoor attack technique on GNNs, namely UGBA, experiments show that GNNInfer's defense success rate is up to 30 times better than existing baselines.