 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerish or Flourish? A Holistic Evaluation of Large Language Models for Code Generation in Functional Programming
Jan 05, 2026Functional programming provides strong foundations for developing reliable and secure software systems, yet its adoption remains not widespread due to the steep learning curve. Recent advances in Large Language Models (LLMs) for code generation present new opportunities to lower these barriers. However, extensive evaluations of LLMs largely focus on imperative programming languages, and their capabilities in functional programming languages (FP) remain underexplored. To address this gap, we introduce FPEval, a holistic evaluation framework built on FPBench, a new benchmark of 721 programming tasks across three difficulty levels on three mainstream FP languages: Haskell, Ocaml and Scala. FPEval provides compehensive evaluation infrastructures with both test validations with comprehensive test suites and static analysis tools to assess both functional correctness and code style and maintainability. Using this framework, we evaluate state-of-the-art LLMs, including GPT-3.5, GPT-4o, and GPT-5, for code generation in functional programming languages and Java as an imperative baseline. Our results demonstrate that LLM performance in functional programming improves substantially with model advancement; however, error rates remain significantly higher in purely functional languages (Haskell and OCaml) than in hybrid (Scala) or imperative (Java) languages. Moreover, LLMs frequently generate non-idiomatic functional code that follows imperative patterns, raising concerns about code style and long-term maintainability. Finally, we show that LLMs can partially self-repair both correctness and quality issues when provided with static analysis feedback and hand-crafted instructions for common types of issues.
LEGION: Harnessing Pre-trained Language Models for GitHub Topic Recommendations with Distribution-Balance Loss
Mar 09, 2024



Open-source development has revolutionized the software industry by promoting collaboration, transparency, and community-driven innovation. Today, a vast amount of various kinds of open-source software, which form networks of repositories, is often hosted on GitHub - a popular software development platform. To enhance the discoverability of the repository networks, i.e., groups of similar repositories, GitHub introduced repository topics in 2017 that enable users to more easily explore relevant projects by type, technology, and more. It is thus crucial to accurately assign topics for each GitHub repository. Current methods for automatic topic recommendation rely heavily on TF-IDF for encoding textual data, presenting challenges in understanding semantic nuances. This paper addresses the limitations of existing techniques by proposing Legion, a novel approach that leverages Pre-trained Language Models (PTMs) for recommending topics for GitHub repositories. The key novelty of Legion is three-fold. First, Legion leverages the extensive capabilities of PTMs in language understanding to capture contextual information and semantic meaning in GitHub repositories. Second, Legion overcomes the challenge of long-tailed distribution, which results in a bias toward popular topics in PTMs, by proposing a Distribution-Balanced Loss (DB Loss) to better train the PTMs. Third, Legion employs a filter to eliminate vague recommendations, thereby improving the precision of PTMs. Our empirical evaluation on a benchmark dataset of real-world GitHub repositories shows that Legion can improve vanilla PTMs by up to 26% on recommending GitHubs topics. Legion also can suggest GitHub topics more precisely and effectively than the state-of-the-art baseline with an average improvement of 20% and 5% in terms of Precision and F1-score, respectively.
Invalidator: Automated Patch Correctness Assessment via Semantic and Syntactic Reasoning
Jan 03, 2023

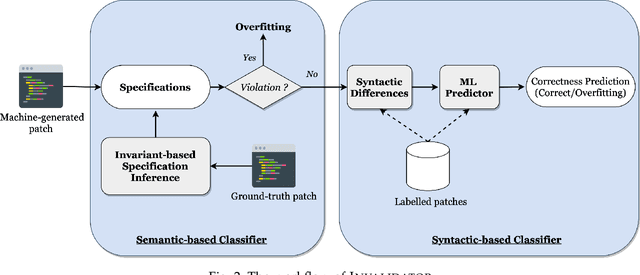
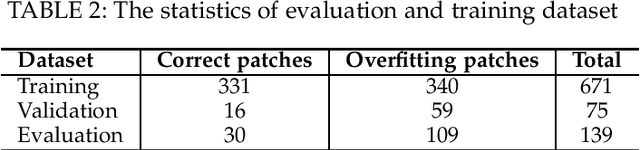
In this paper, we propose a novel technique, namely INVALIDATOR, to automatically assess the correctness of APR-generated patches via semantic and syntactic reasoning. INVALIDATOR reasons about program semantic via program invariants while it also captures program syntax via language semantic learned from large code corpus using the pre-trained language model. Given a buggy program and the developer-patched program, INVALIDATOR infers likely invariants on both programs. Then, INVALIDATOR determines that a APR-generated patch overfits if: (1) it violates correct specifications or (2) maintains errors behaviors of the original buggy program. In case our approach fails to determine an overfitting patch based on invariants, INVALIDATOR utilizes a trained model from labeled patches to assess patch correctness based on program syntax. The benefit of INVALIDATOR is three-fold. First, INVALIDATOR is able to leverage both semantic and syntactic reasoning to enhance its discriminant capability. Second, INVALIDATOR does not require new test cases to be generated but instead only relies on the current test suite and uses invariant inference to generalize the behaviors of a program. Third, INVALIDATOR is fully automated. We have conducted our experiments on a dataset of 885 patches generated on real-world programs in Defects4J. Experiment results show that INVALIDATOR correctly classified 79% overfitting patches, accounting for 23% more overfitting patches being detected by the best baseline. INVALIDATOR also substantially outperforms the best baselines by 14% and 19% in terms of Accuracy and F-Measure, respectively.
Usability and Aesthetics: Better Together for Automated Repair of Web Pages
Jan 01, 2022
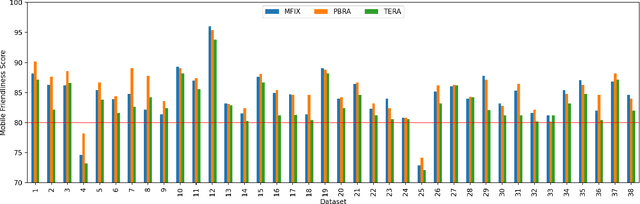
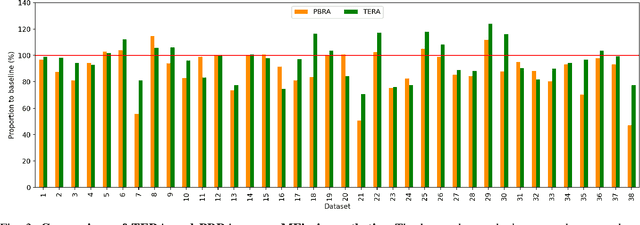
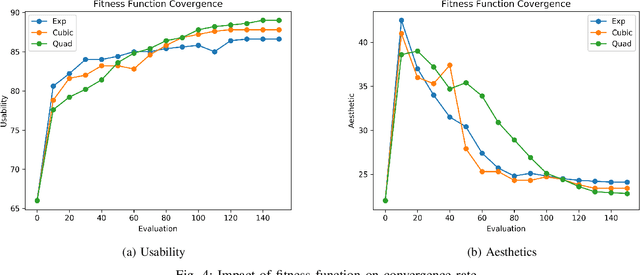
With the recent explosive growth of mobile devices such as smartphones or tablets, guaranteeing consistent web appearance across all environments has become a significant problem. This happens simply because it is hard to keep track of the web appearance on different sizes and types of devices that render the web pages. Therefore, fixing the inconsistent appearance of web pages can be difficult, and the cost incurred can be huge, e.g., poor user experience and financial loss due to it. Recently, automated web repair techniques have been proposed to automatically resolve inconsistent web page appearance, focusing on improving usability. However, generated patches tend to disrupt the webpage's layout, rendering the repaired webpage aesthetically unpleasing, e.g., distorted images or misalignment of components. In this paper, we propose an automated repair approach for web pages based on meta-heuristic algorithms that can assure both usability and aesthetics. The key novelty that empowers our approach is a novel fitness function that allows us to optimistically evolve buggy web pages to find the best solution that optimizes both usability and aesthetics at the same time. Empirical evaluations show that our approach is able to successfully resolve mobile-friendly problems in 94% of the evaluation subjects, significantly outperforming state-of-the-art baseline techniques in terms of both usability and aesthetics.
* Accepted to ISSRE 2021, Research Track
Toward the Analysis of Graph Neural Networks
Jan 01, 2022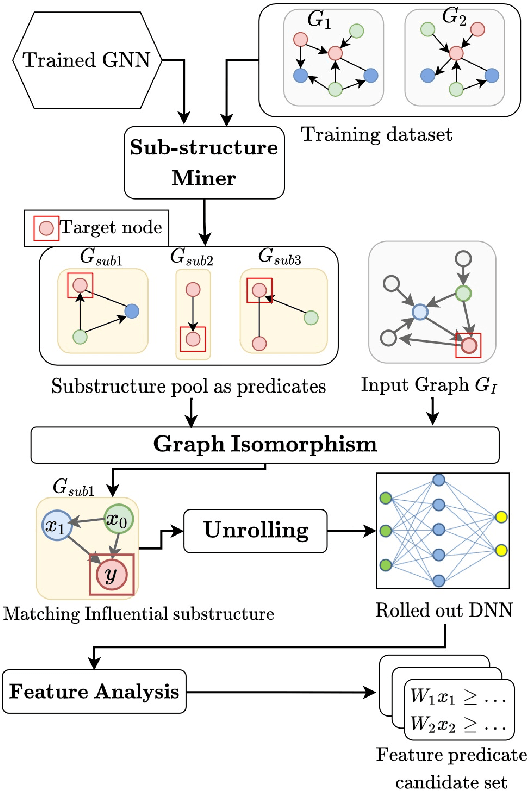
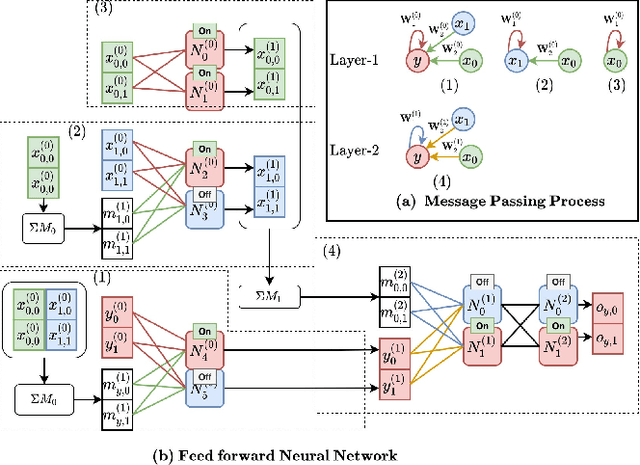
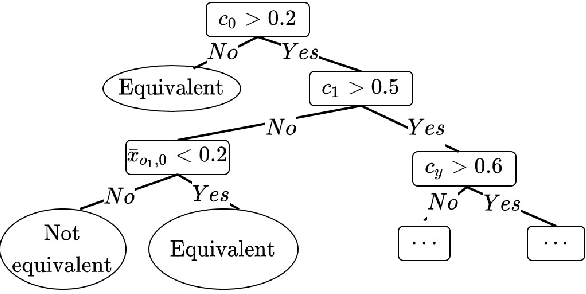
Graph Neural Networks (GNNs) have recently emerged as a robust framework for graph-structured data. They have been applied to many problems such as knowledge graph analysis, social networks recommendation, and even Covid19 detection and vaccine developments. However, unlike other deep neural networks such as Feed Forward Neural Networks (FFNNs), few analyses such as verification and property inferences exist, potentially due to dynamic behaviors of GNNs, which can take arbitrary graphs as input, whereas FFNNs which only take fixed size numerical vectors as inputs. This paper proposes an approach to analyze GNNs by converting them into FFNNs and reusing existing FFNNs analyses. We discuss various designs to ensure the scalability and accuracy of the conversions. We illustrate our method on a study case of node classification. We believe that our approach opens new research directions for understanding and analyzing GNNs.
* Accepted to ICSE 2022, NIER track