 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD method for entropy error function with smoothing l0 regularization for neural networks
May 28, 2024The entropy error function has been widely used in neural networks. Nevertheless, the network training based on this error function generally leads to a slow convergence rate, and can easily be trapped in a local minimum or even with the incorrect saturation problem in practice. In fact, there are many results based on entropy error function in neural network and its applications. However, the theory of such an algorithm and its convergence have not been fully studied so far. To tackle the issue, we propose a novel entropy function with smoothing l0 regularization for feed-forward neural networks. Using real-world datasets, we performed an empirical evaluation to demonstrate that the newly conceived algorithm allows us to substantially improve the prediction performance of the considered neural networks. More importantly, the experimental results also show that our proposed function brings in more precise classifications, compared to well-founded baselines. Our work is novel as it enables neural networks to learn effectively, producing more accurate predictions compared to state-of-the-art algorithms. In this respect, we expect that the algorithm will contribute to existing studies in the field, advancing research in Machine Learning and Deep Learning.
LEGION: Harnessing Pre-trained Language Models for GitHub Topic Recommendations with Distribution-Balance Loss
Mar 09, 2024



Open-source development has revolutionized the software industry by promoting collaboration, transparency, and community-driven innovation. Today, a vast amount of various kinds of open-source software, which form networks of repositories, is often hosted on GitHub - a popular software development platform. To enhance the discoverability of the repository networks, i.e., groups of similar repositories, GitHub introduced repository topics in 2017 that enable users to more easily explore relevant projects by type, technology, and more. It is thus crucial to accurately assign topics for each GitHub repository. Current methods for automatic topic recommendation rely heavily on TF-IDF for encoding textual data, presenting challenges in understanding semantic nuances. This paper addresses the limitations of existing techniques by proposing Legion, a novel approach that leverages Pre-trained Language Models (PTMs) for recommending topics for GitHub repositories. The key novelty of Legion is three-fold. First, Legion leverages the extensive capabilities of PTMs in language understanding to capture contextual information and semantic meaning in GitHub repositories. Second, Legion overcomes the challenge of long-tailed distribution, which results in a bias toward popular topics in PTMs, by proposing a Distribution-Balanced Loss (DB Loss) to better train the PTMs. Third, Legion employs a filter to eliminate vague recommendations, thereby improving the precision of PTMs. Our empirical evaluation on a benchmark dataset of real-world GitHub repositories shows that Legion can improve vanilla PTMs by up to 26% on recommending GitHubs topics. Legion also can suggest GitHub topics more precisely and effectively than the state-of-the-art baseline with an average improvement of 20% and 5% in terms of Precision and F1-score, respectively.
Leveraging Privacy Profiles to Empower Users in the Digital Society
Apr 01, 2022
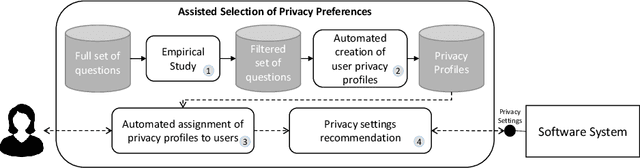
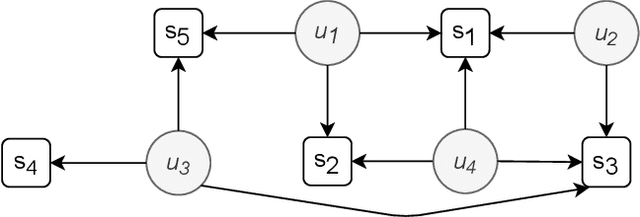
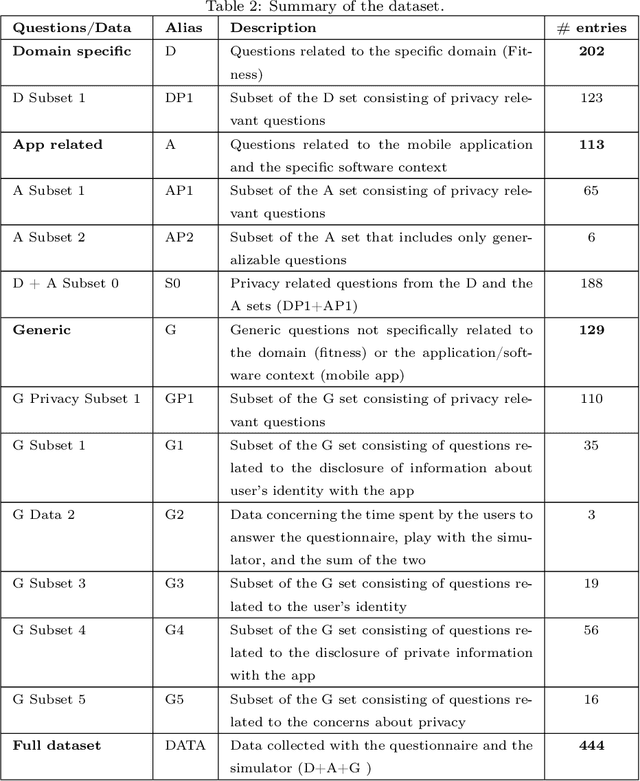
Privacy and ethics of citizens are at the core of the concerns raised by our increasingly digital society. Profiling users is standard practice for software applications triggering the need for users, also enforced by laws, to properly manage privacy settings. Users need to manage software privacy settings properly to protect personally identifiable information and express personal ethical preferences. AI technologies that empower users to interact with the digital world by reflecting their personal ethical preferences can be key enablers of a trustworthy digital society. We focus on the privacy dimension and contribute a step in the above direction through an empirical study on an existing dataset collected from the fitness domain. We find out which set of questions is appropriate to differentiate users according to their preferences. The results reveal that a compact set of semantic-driven questions (about domain-independent privacy preferences) helps distinguish users better than a complex domain-dependent one. This confirms the study's hypothesis that moral attitudes are the relevant piece of information to collect. Based on the outcome, we implement a recommender system to provide users with suitable recommendations related to privacy choices. We then show that the proposed recommender system provides relevant settings to users, obtaining high accuracy.
Unavailable Transit Feed Specification: Making it Available with Recurrent Neural Networks
Feb 20, 2021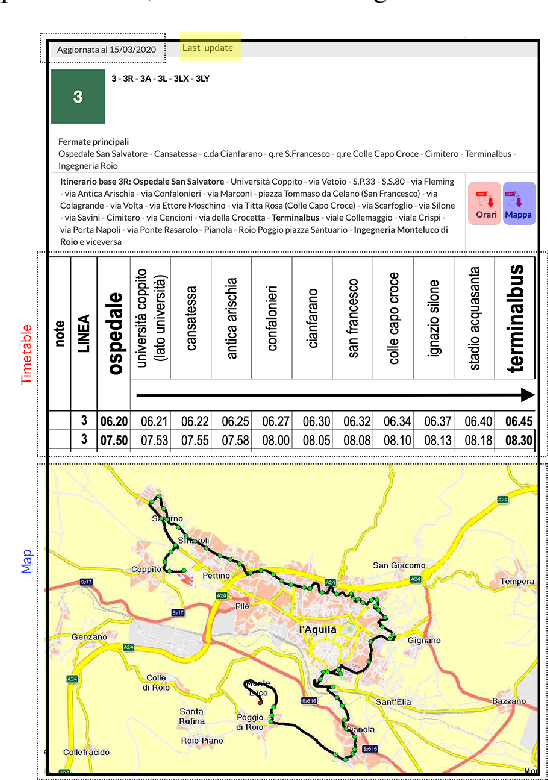
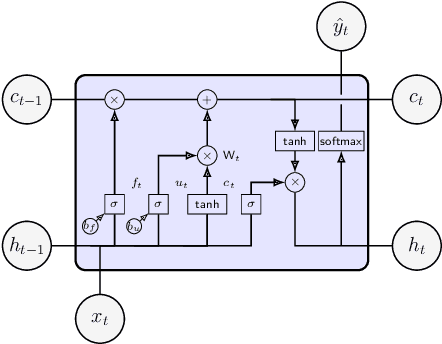


Studies on public transportation in Europe suggest that European inhabitants use buses in ca. 56% of all public transport travels. One of the critical factors affecting such a percentage and more, in general, the demand for public transport services, with an increasing reluctance to use them, is their quality. End-users can perceive quality from various perspectives, including the availability of information, i.e., the access to details about the transit and the provided services. The approach proposed in this paper, using innovative methodologies resorting on data mining and machine learning techniques, aims to make available the unavailable data about public transport. In particular, by mining GPS traces, we manage to reconstruct the complete transit graph of public transport. The approach has been successfully validated on a real dataset collected from the local bus system of the city of L'Aquila (Italy). The experimental results demonstrate that the proposed approach and implemented framework are both effective and efficient, thus being ready for deployment.