 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Representation of Norms
Jan 06, 2026Autonomous systems (AS) powered by AI components are increasingly integrated into the fabric of our daily lives and society, raising concerns about their ethical and social impact. To be considered trustworthy, AS must adhere to ethical principles and values. This has led to significant research on the identification and incorporation of ethical requirements in AS system design. A recent development in this area is the introduction of SLEEC (Social, Legal, Ethical, Empathetic, and Cultural) rules, which provide a comprehensive framework for representing ethical and other normative considerations. This paper proposes a logical representation of SLEEC rules and presents a methodology to embed these ethical requirements using test-score semantics and fuzzy logic. The use of fuzzy logic is motivated by the view of ethics as a domain of possibilities, which allows the resolution of ethical dilemmas that AI systems may encounter. The proposed approach is illustrated through a case study.
RobEthiChor: Automated Context-aware Ethics-based Negotiation for Autonomous Robots
Jul 30, 2025The presence of autonomous systems is growing at a fast pace and it is impacting many aspects of our lives. Designed to learn and act independently, these systems operate and perform decision-making without human intervention. However, they lack the ability to incorporate users' ethical preferences, which are unique for each individual in society and are required to personalize the decision-making processes. This reduces user trust and prevents autonomous systems from behaving according to the moral beliefs of their end-users. When multiple systems interact with differing ethical preferences, they must negotiate to reach an agreement that satisfies the ethical beliefs of all the parties involved and adjust their behavior consequently. To address this challenge, this paper proposes RobEthiChor, an approach that enables autonomous systems to incorporate user ethical preferences and contextual factors into their decision-making through ethics-based negotiation. RobEthiChor features a domain-agnostic reference architecture for designing autonomous systems capable of ethic-based negotiating. The paper also presents RobEthiChor-Ros, an implementation of RobEthiChor within the Robot Operating System (ROS), which can be deployed on robots to provide them with ethics-based negotiation capabilities. To evaluate our approach, we deployed RobEthiChor-Ros on real robots and ran scenarios where a pair of robots negotiate upon resource contention. Experimental results demonstrate the feasibility and effectiveness of the system in realizing ethics-based negotiation. RobEthiChor allowed robots to reach an agreement in more than 73\% of the scenarios with an acceptable negotiation time (0.67s on average). Experiments also demonstrate that the negotiation approach implemented in RobEthiChor is scalable.
Social, Legal, Ethical, Empathetic, and Cultural Rules: Compilation and Reasoning (Extended Version)
Dec 15, 2023
The rise of AI-based and autonomous systems is raising concerns and apprehension due to potential negative repercussions stemming from their behavior or decisions. These systems must be designed to comply with the human contexts in which they will operate. To this extent, Townsend et al. (2022) introduce the concept of SLEEC (social, legal, ethical, empathetic, or cultural) rules that aim to facilitate the formulation, verification, and enforcement of the rules AI-based and autonomous systems should obey. They lay out a methodology to elicit them and to let philosophers, lawyers, domain experts, and others to formulate them in natural language. To enable their effective use in AI systems, it is necessary to translate these rules systematically into a formal language that supports automated reasoning. In this study, we first conduct a linguistic analysis of the SLEEC rules pattern, which justifies the translation of SLEEC rules into classical logic. Then we investigate the computational complexity of reasoning about SLEEC rules and show how logical programming frameworks can be employed to implement SLEEC rules in practical scenarios. The result is a readily applicable strategy for implementing AI systems that conform to norms expressed as SLEEC rules.
Leveraging Privacy Profiles to Empower Users in the Digital Society
Apr 01, 2022
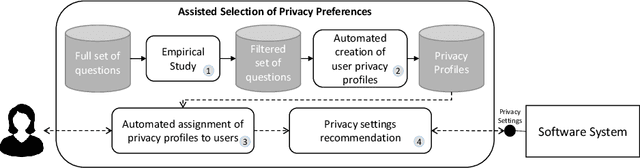
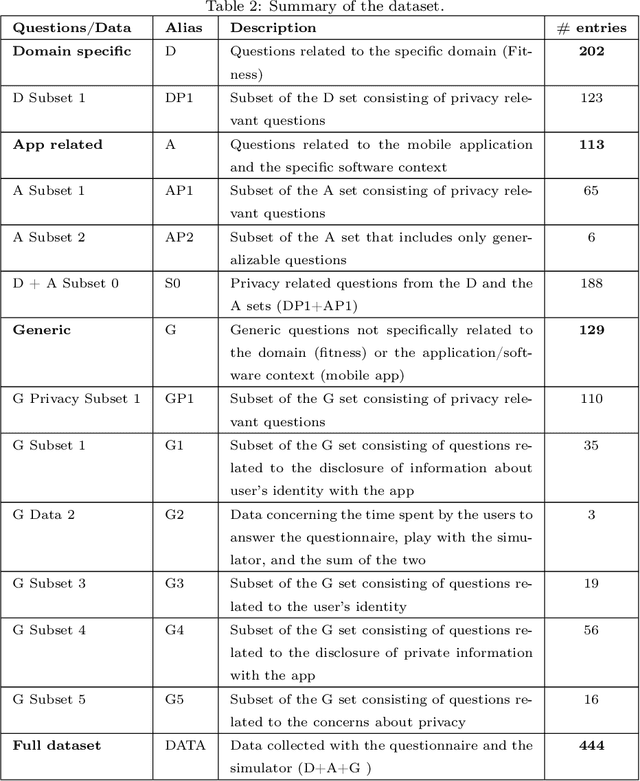
Privacy and ethics of citizens are at the core of the concerns raised by our increasingly digital society. Profiling users is standard practice for software applications triggering the need for users, also enforced by laws, to properly manage privacy settings. Users need to manage software privacy settings properly to protect personally identifiable information and express personal ethical preferences. AI technologies that empower users to interact with the digital world by reflecting their personal ethical preferences can be key enablers of a trustworthy digital society. We focus on the privacy dimension and contribute a step in the above direction through an empirical study on an existing dataset collected from the fitness domain. We find out which set of questions is appropriate to differentiate users according to their preferences. The results reveal that a compact set of semantic-driven questions (about domain-independent privacy preferences) helps distinguish users better than a complex domain-dependent one. This confirms the study's hypothesis that moral attitudes are the relevant piece of information to collect. Based on the outcome, we implement a recommender system to provide users with suitable recommendations related to privacy choices. We then show that the proposed recommender system provides relevant settings to users, obtaining high accuracy.
Exosoul: ethical profiling in the digital world
Mar 30, 2022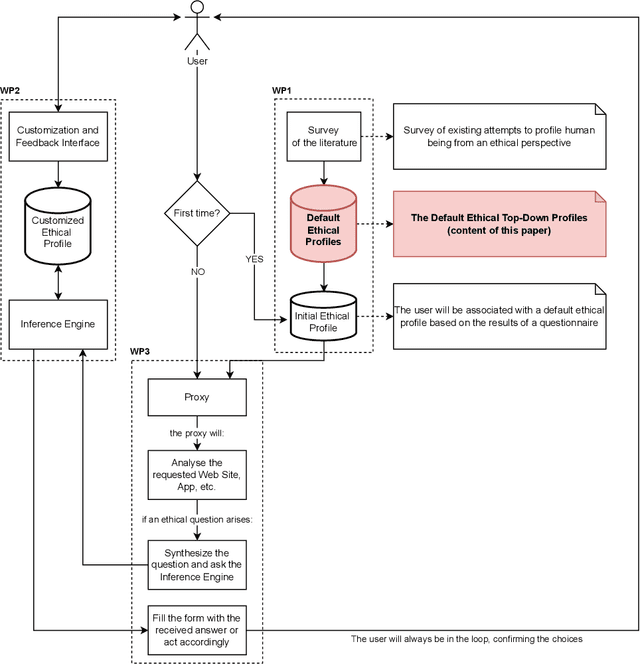



The development and the spread of increasingly autonomous digital technologies in our society pose new ethical challenges beyond data protection and privacy violation. Users are unprotected in their interactions with digital technologies and at the same time autonomous systems are free to occupy the space of decisions that is prerogative of each human being. In this context the multidisciplinary project Exosoul aims at developing a personalized software exoskeleton which mediates actions in the digital world according to the moral preferences of the user. The exoskeleton relies on the ethical profiling of a user, similar in purpose to the privacy profiling proposed in the literature, but aiming at reflecting and predicting general moral preferences. Our approach is hybrid, first based on the identification of profiles in a top-down manner, and then on the refinement of profiles by a personalized data-driven approach. In this work we report our initial experiment on building such top-down profiles. We consider the correlations between ethics positions (idealism and relativism) personality traits (honesty/humility, conscientiousness, Machiavellianism and narcissism) and worldview (normativism), and then we use a clustering approach to create ethical profiles predictive of user's digital behaviors concerning privacy violation, copy-right infringements, caution and protection. Data were collected by administering a questionnaire to 317 young individuals. In the paper we discuss two clustering solutions, one data-driven and one model-driven, in terms of validity and predictive power of digital behavior.