 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Embodied AI Reliable: A Community Agenda from Testing to Formal Verification
Jun 02, 2026Embodied AI systems are increasingly deployed in open-world environments, yet ensuring their reliability remains a fundamental challenge. Drawing on discussions from the AAAI'26 Bridge Program on "Making Embodied AI Reliable with Testing and Formal Verification", this article argues that reliability in embodied AI is inherently a lifecycle assurance problem arising from uncertainty, human interaction, and emergent behaviors across tightly coupled system components. We identify three complementary directions toward reliable embodied AI: (1) trustworthy scenario-based testing supported by validated specifications and meaningful coverage metrics, (2) compositional verification enabled by structured symbolic representations of system behavior and environmental context, and (3) runtime assurance mechanisms capable of adapting to uncertainty and distribution shifts during deployment. Rather than treating these approaches independently, we advocate integrated assurance workflows that connect testing, verification, and runtime adaptation through shared neuro-symbolic representations and continuous feedback across the system lifecycle. Such integration provides a foundation for building trustworthy embodied AI systems that can operate safely and reliably in complex real-world environments.
CONCUR: Benchmarking LLMs for Concurrent Code Generation
Mar 04, 2026Leveraging Large Language Models (LLMs) for code generation has increasingly emerged as a common practice in the domain of software engineering. Relevant benchmarks have been established to evaluate the code generation capabilities of LLMs. However, existing benchmarks focus primarily on sequential code, lacking the ability to effectively evaluate LLMs on concurrent code generation. Compared to sequential code, concurrent code exhibits greater complexity and possesses unique types of bugs, such as deadlocks and race conditions, that do not occur in sequential code. Therefore, a benchmark for evaluating sequential code generation cannot be useful for evaluating concurrent code generation with LLMs. To address this gap, we designed a benchmark CONCUR specifically aimed at evaluating the capability of LLMs to generate concurrent code. CONCUR consists of a base set of 43 concurrency problems derived from a standard concurrency textbook, together with 72 validated mutant variants, resulting in 115 total problems. The base problems serve as the semantic core of the benchmark, while the mutants expand linguistic and structural diversity. We conducted an evaluation of a range of LLMs on CONCUR, highlighting limitations of current models. Overall, our work provides a novel direction for evaluating the capability of LLMs to generate code with focus on concurrency.
AI Software Engineer: Programming with Trust
Feb 19, 2025
Large Language Models (LLMs) have shown surprising proficiency in generating code snippets, promising to automate large parts of software engineering via artificial intelligence (AI). We argue that successfully deploying AI software engineers requires a level of trust equal to or even greater than the trust established by human-driven software engineering practices. The recent trend toward LLM agents offers a path toward integrating the power of LLMs to create new code with the power of analysis tools to increase trust in the code. This opinion piece comments on whether LLM agents could dominate software engineering workflows in the future and whether the focus of programming will shift from programming at scale to programming with trust.
Concept-based Analysis of Neural Networks via Vision-Language Models
Apr 10, 2024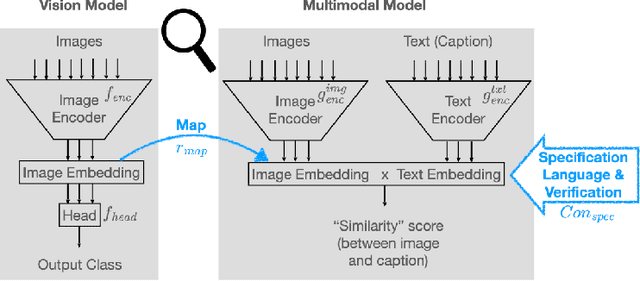
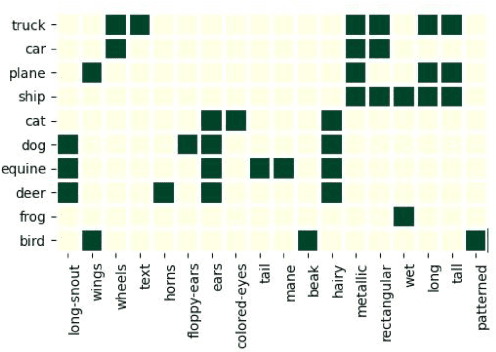
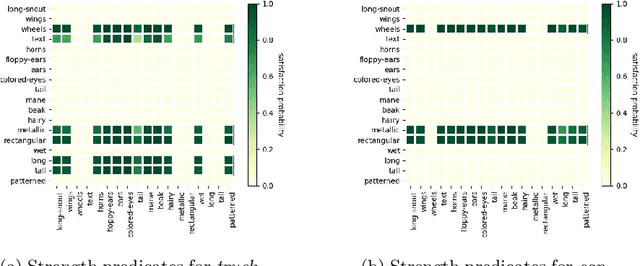
The analysis of vision-based deep neural networks (DNNs) is highly desirable but it is very challenging due to the difficulty of expressing formal specifications for vision tasks and the lack of efficient verification procedures. In this paper, we propose to leverage emerging multimodal, vision-language, foundation models (VLMs) as a lens through which we can reason about vision models. VLMs have been trained on a large body of images accompanied by their textual description, and are thus implicitly aware of high-level, human-understandable concepts describing the images. We describe a logical specification language $\texttt{Con}_{\texttt{spec}}$ designed to facilitate writing specifications in terms of these concepts. To define and formally check $\texttt{Con}_{\texttt{spec}}$ specifications, we build a map between the internal representations of a given vision model and a VLM, leading to an efficient verification procedure of natural-language properties for vision models. We demonstrate our techniques on a ResNet-based classifier trained on the RIVAL-10 dataset using CLIP as the multimodal model.
Inferring Properties of Graph Neural Networks
Jan 08, 2024



We propose GNNInfer, the first automatic property inference technique for GNNs. To tackle the challenge of varying input structures in GNNs, GNNInfer first identifies a set of representative influential structures that contribute significantly towards the prediction of a GNN. Using these structures, GNNInfer converts each pair of an influential structure and the GNN to their equivalent FNN and then leverages existing property inference techniques to effectively capture properties of the GNN that are specific to the influential structures. GNNINfer then generalizes the captured properties to any input graphs that contain the influential structures. Finally, GNNInfer improves the correctness of the inferred properties by building a model (either a decision tree or linear regression) that estimates the deviation of GNN output from the inferred properties given full input graphs. The learned model helps GNNInfer extend the inferred properties with constraints to the input and output of the GNN, obtaining stronger properties that hold on full input graphs. Our experiments show that GNNInfer is effective in inferring likely properties of popular real-world GNNs, and more importantly, these inferred properties help effectively defend against GNNs' backdoor attacks. In particular, out of the 13 ground truth properties, GNNInfer re-discovered 8 correct properties and discovered likely correct properties that approximate the remaining 5 ground truth properties. Using properties inferred by GNNInfer to defend against the state-of-the-art backdoor attack technique on GNNs, namely UGBA, experiments show that GNNInfer's defense success rate is up to 30 times better than existing baselines.
Transfer Attacks and Defenses for Large Language Models on Coding Tasks
Nov 22, 2023


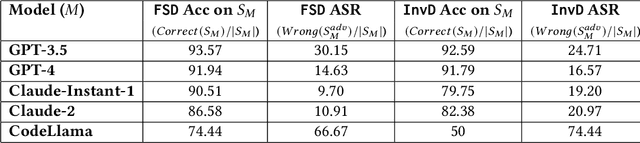
Modern large language models (LLMs), such as ChatGPT, have demonstrated impressive capabilities for coding tasks including writing and reasoning about code. They improve upon previous neural network models of code, such as code2seq or seq2seq, that already demonstrated competitive results when performing tasks such as code summarization and identifying code vulnerabilities. However, these previous code models were shown vulnerable to adversarial examples, i.e. small syntactic perturbations that do not change the program's semantics, such as the inclusion of "dead code" through false conditions or the addition of inconsequential print statements, designed to "fool" the models. LLMs can also be vulnerable to the same adversarial perturbations but a detailed study on this concern has been lacking so far. In this paper we aim to investigate the effect of adversarial perturbations on coding tasks with LLMs. In particular, we study the transferability of adversarial examples, generated through white-box attacks on smaller code models, to LLMs. Furthermore, to make the LLMs more robust against such adversaries without incurring the cost of retraining, we propose prompt-based defenses that involve modifying the prompt to include additional information such as examples of adversarially perturbed code and explicit instructions for reversing adversarial perturbations. Our experiments show that adversarial examples obtained with a smaller code model are indeed transferable, weakening the LLMs' performance. The proposed defenses show promise in improving the model's resilience, paving the way to more robust defensive solutions for LLMs in code-related applications.
Is Certifying $\ell_p$ Robustness Still Worthwhile?
Oct 13, 2023
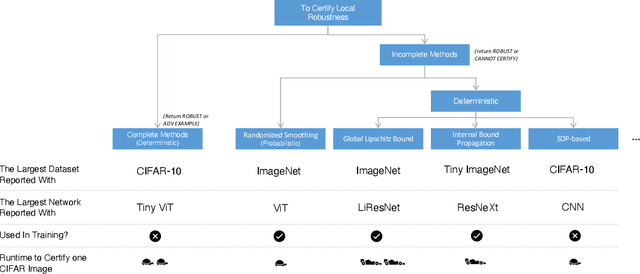

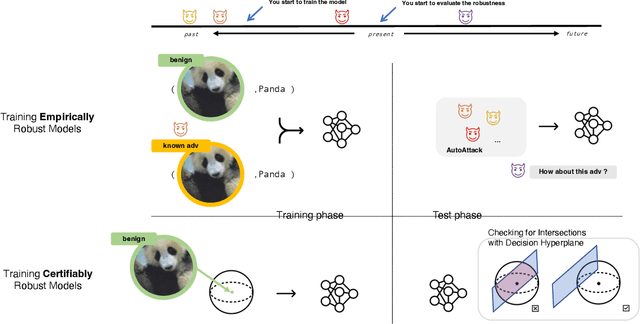
Over the years, researchers have developed myriad attacks that exploit the ubiquity of adversarial examples, as well as defenses that aim to guard against the security vulnerabilities posed by such attacks. Of particular interest to this paper are defenses that provide provable guarantees against the class of $\ell_p$-bounded attacks. Certified defenses have made significant progress, taking robustness certification from toy models and datasets to large-scale problems like ImageNet classification. While this is undoubtedly an interesting academic problem, as the field has matured, its impact in practice remains unclear, thus we find it useful to revisit the motivation for continuing this line of research. There are three layers to this inquiry, which we address in this paper: (1) why do we care about robustness research? (2) why do we care about the $\ell_p$-bounded threat model? And (3) why do we care about certification as opposed to empirical defenses? In brief, we take the position that local robustness certification indeed confers practical value to the field of machine learning. We focus especially on the latter two questions from above. With respect to the first of the two, we argue that the $\ell_p$-bounded threat model acts as a minimal requirement for safe application of models in security-critical domains, while at the same time, evidence has mounted suggesting that local robustness may lead to downstream external benefits not immediately related to robustness. As for the second, we argue that (i) certification provides a resolution to the cat-and-mouse game of adversarial attacks; and furthermore, that (ii) perhaps contrary to popular belief, there may not exist a fundamental trade-off between accuracy, robustness, and certifiability, while moreover, certified training techniques constitute a particularly promising way for learning robust models.
Assumption Generation for the Verification of Learning-Enabled Autonomous Systems
May 27, 2023Providing safety guarantees for autonomous systems is difficult as these systems operate in complex environments that require the use of learning-enabled components, such as deep neural networks (DNNs) for visual perception. DNNs are hard to analyze due to their size (they can have thousands or millions of parameters), lack of formal specifications (DNNs are typically learnt from labeled data, in the absence of any formal requirements), and sensitivity to small changes in the environment. We present an assume-guarantee style compositional approach for the formal verification of system-level safety properties of such autonomous systems. Our insight is that we can analyze the system in the absence of the DNN perception components by automatically synthesizing assumptions on the DNN behaviour that guarantee the satisfaction of the required safety properties. The synthesized assumptions are the weakest in the sense that they characterize the output sequences of all the possible DNNs that, plugged into the autonomous system, guarantee the required safety properties. The assumptions can be leveraged as run-time monitors over a deployed DNN to guarantee the safety of the overall system; they can also be mined to extract local specifications for use during training and testing of DNNs. We illustrate our approach on a case study taken from the autonomous airplanes domain that uses a complex DNN for perception.
Toward Certified Robustness Against Real-World Distribution Shifts
Jun 09, 2022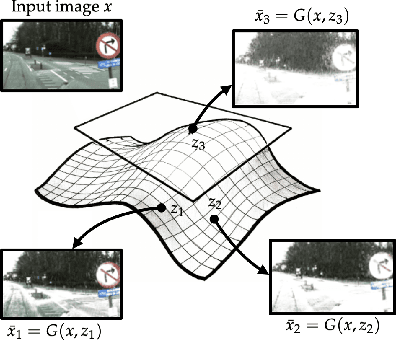
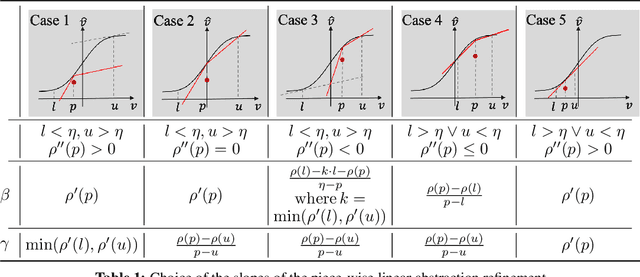
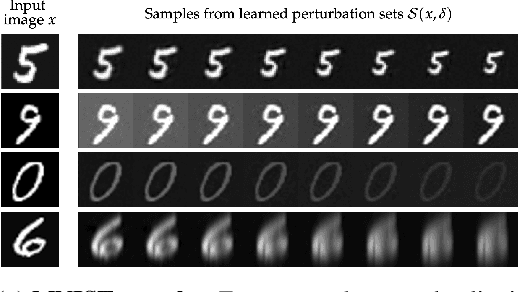
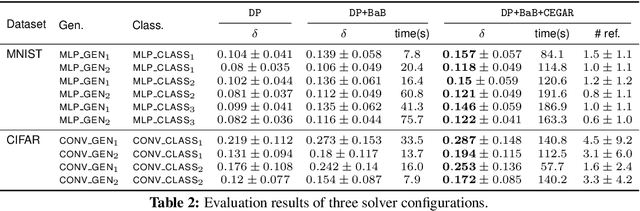
We consider the problem of certifying the robustness of deep neural networks against real-world distribution shifts. To do so, we bridge the gap between hand-crafted specifications and realistic deployment settings by proposing a novel neural-symbolic verification framework, in which we train a generative model to learn perturbations from data and define specifications with respect to the output of the learned model. A unique challenge arising from this setting is that existing verifiers cannot tightly approximate sigmoid activations, which are fundamental to many state-of-the-art generative models. To address this challenge, we propose a general meta-algorithm for handling sigmoid activations which leverages classical notions of counter-example-guided abstraction refinement. The key idea is to "lazily" refine the abstraction of sigmoid functions to exclude spurious counter-examples found in the previous abstraction, thus guaranteeing progress in the verification process while keeping the state-space small. Experiments on the MNIST and CIFAR-10 datasets show that our framework significantly outperforms existing methods on a range of challenging distribution shifts.
On the Perils of Cascading Robust Classifiers
Jun 01, 2022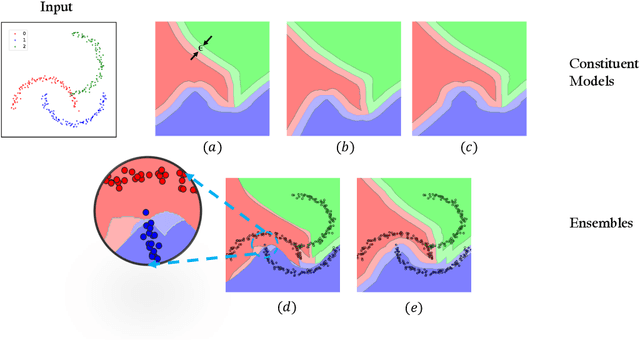
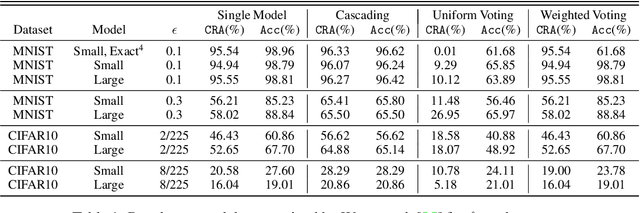
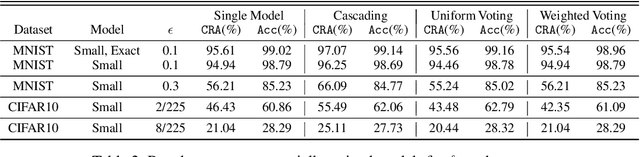
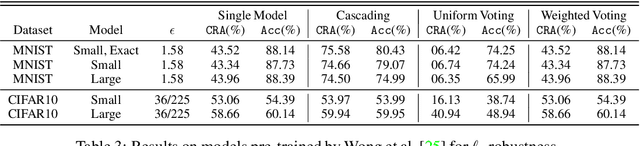
Ensembling certifiably robust neural networks has been shown to be a promising approach for improving the \emph{certified robust accuracy} of neural models. Black-box ensembles that assume only query-access to the constituent models (and their robustness certifiers) during prediction are particularly attractive due to their modular structure. Cascading ensembles are a popular instance of black-box ensembles that appear to improve certified robust accuracies in practice. However, we find that the robustness certifier used by a cascading ensemble is unsound. That is, when a cascading ensemble is certified as locally robust at an input $x$, there can, in fact, be inputs $x'$ in the $\epsilon$-ball centered at $x$, such that the cascade's prediction at $x'$ is different from $x$. We present an alternate black-box ensembling mechanism based on weighted voting which we prove to be sound for robustness certification. Via a thought experiment, we demonstrate that if the constituent classifiers are suitably diverse, voting ensembles can improve certified performance. Our code is available at \url{https://github.com/TristaChi/ensembleKW}.