 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Safety Reasoning and Grounding for Open-World Robots
Feb 24, 2026Robots are increasingly operating in open-world environments where safe behavior depends on context: the same hallway may require different navigation strategies when crowded versus empty, or during an emergency versus normal operations. Traditional safety approaches enforce fixed constraints in user-specified contexts, limiting their ability to handle the open-ended contextual variability of real-world deployment. We address this gap via CORE, a safety framework that enables online contextual reasoning, grounding, and enforcement without prior knowledge of the environment (e.g., maps or safety specifications). CORE uses a vision-language model (VLM) to continuously reason about context-dependent safety rules directly from visual observations, grounds these rules in the physical environment, and enforces the resulting spatially-defined safe sets via control barrier functions. We provide probabilistic safety guarantees for CORE that account for perceptual uncertainty, and we demonstrate through simulation and real-world experiments that CORE enforces contextually appropriate behavior in unseen environments, significantly outperforming prior semantic safety methods that lack online contextual reasoning. Ablation studies validate our theoretical guarantees and underscore the importance of both VLM-based reasoning and spatial grounding for enforcing contextual safety in novel settings. We provide additional resources at https://zacravichandran.github.io/CORE.
Multi-Round Human-AI Collaboration with User-Specified Requirements
Feb 19, 2026As humans increasingly rely on multiround conversational AI for high stakes decisions, principled frameworks are needed to ensure such interactions reliably improve decision quality. We adopt a human centric view governed by two principles: counterfactual harm, ensuring the AI does not undermine human strengths, and complementarity, ensuring it adds value where the human is prone to err. We formalize these concepts via user defined rules, allowing users to specify exactly what harm and complementarity mean for their specific task. We then introduce an online, distribution free algorithm with finite sample guarantees that enforces the user-specified constraints over the collaboration dynamics. We evaluate our framework across two interactive settings: LLM simulated collaboration on a medical diagnostic task and a human crowdsourcing study on a pictorial reasoning task. We show that our online procedure maintains prescribed counterfactual harm and complementarity violation rates even under nonstationary interaction dynamics. Moreover, tightening or loosening these constraints produces predictable shifts in downstream human accuracy, confirming that the two principles serve as practical levers for steering multi-round collaboration toward better decision quality without the need to model or constrain human behavior.
When to Trust the Cheap Check: Weak and Strong Verification for Reasoning
Feb 19, 2026Reasoning with LLMs increasingly unfolds inside a broader verification loop. Internally, systems use cheap checks, such as self-consistency or proxy rewards, which we call weak verification. Externally, users inspect outputs and steer the model through feedback until results are trustworthy, which we call strong verification. These signals differ sharply in cost and reliability: strong verification can establish trust but is resource-intensive, while weak verification is fast and scalable but noisy and imperfect. We formalize this tension through weak--strong verification policies, which decide when to accept or reject based on weak verification and when to defer to strong verification. We introduce metrics capturing incorrect acceptance, incorrect rejection, and strong-verification frequency. Over population, we show that optimal policies admit a two-threshold structure and that calibration and sharpness govern the value of weak verifiers. Building on this, we develop an online algorithm that provably controls acceptance and rejection errors without assumptions on the query stream, the language model, or the weak verifier.
Robust Policy Optimization to Prevent Catastrophic Forgetting
Feb 09, 2026Large language models are commonly trained through multi-stage post-training: first via RLHF, then fine-tuned for other downstream objectives. Yet even small downstream updates can compromise earlier learned behaviors (e.g., safety), exposing a brittleness known as catastrophic forgetting. This suggests standard RLHF objectives do not guarantee robustness to future adaptation. To address it, most prior work designs downstream-time methods to preserve previously learned behaviors. We argue that preventing this requires pre-finetuning robustness: the base policy should avoid brittle high-reward solutions whose reward drops sharply under standard fine-tuning. We propose Fine-tuning Robust Policy Optimization (FRPO), a robust RLHF framework that optimizes reward not only at the current policy, but across a KL-bounded neighborhood of policies reachable by downstream adaptation. The key idea is to ensure reward stability under policy shifts via a max-min formulation. By modifying GRPO, we develop an algorithm with no extra computation, and empirically show it substantially reduces safety degradation across multiple base models and downstream fine-tuning regimes (SFT and RL) while preserving downstream task performance. We further study a math-focused RL setting, demonstrating that FRPO preserves accuracy under subsequent fine-tuning.
Towards Reducible Uncertainty Modeling for Reliable Large Language Model Agents
Feb 04, 2026Uncertainty quantification (UQ) for large language models (LLMs) is a key building block for safety guardrails of daily LLM applications. Yet, even as LLM agents are increasingly deployed in highly complex tasks, most UQ research still centers on single-turn question-answering. We argue that UQ research must shift to realistic settings with interactive agents, and that a new principled framework for agent UQ is needed. This paper presents the first general formulation of agent UQ that subsumes broad classes of existing UQ setups. Under this formulation, we show that prior works implicitly treat LLM UQ as an uncertainty accumulation process, a viewpoint that breaks down for interactive agents in an open world. In contrast, we propose a novel perspective, a conditional uncertainty reduction process, that explicitly models reducible uncertainty over an agent's trajectory by highlighting "interactivity" of actions. From this perspective, we outline a conceptual framework to provide actionable guidance for designing UQ in LLM agent setups. Finally, we conclude with practical implications of the agent UQ in frontier LLM development and domain-specific applications, as well as open remaining problems.
MultiRisk: Multiple Risk Control via Iterative Score Thresholding
Dec 31, 2025As generative AI systems are increasingly deployed in real-world applications, regulating multiple dimensions of model behavior has become essential. We focus on test-time filtering: a lightweight mechanism for behavior control that compares performance scores to estimated thresholds, and modifies outputs when these bounds are violated. We formalize the problem of enforcing multiple risk constraints with user-defined priorities, and introduce two efficient dynamic programming algorithms that leverage this sequential structure. The first, MULTIRISK-BASE, provides a direct finite-sample procedure for selecting thresholds, while the second, MULTIRISK, leverages data exchangeability to guarantee simultaneous control of the risks. Under mild assumptions, we show that MULTIRISK achieves nearly tight control of all constraint risks. The analysis requires an intricate iterative argument, upper bounding the risks by introducing several forms of intermediate symmetrized risk functions, and carefully lower bounding the risks by recursively counting jumps in symmetrized risk functions between appropriate risk levels. We evaluate our framework on a three-constraint Large Language Model alignment task using the PKU-SafeRLHF dataset, where the goal is to maximize helpfulness subject to multiple safety constraints, and where scores are generated by a Large Language Model judge and a perplexity filter. Our experimental results show that our algorithm can control each individual risk at close to the target level.
Benchmarking Misuse Mitigation Against Covert Adversaries
Jun 06, 2025Existing language model safety evaluations focus on overt attacks and low-stakes tasks. Realistic attackers can subvert current safeguards by requesting help on small, benign-seeming tasks across many independent queries. Because individual queries do not appear harmful, the attack is hard to {detect}. However, when combined, these fragments uplift misuse by helping the attacker complete hard and dangerous tasks. Toward identifying defenses against such strategies, we develop Benchmarks for Stateful Defenses (BSD), a data generation pipeline that automates evaluations of covert attacks and corresponding defenses. Using this pipeline, we curate two new datasets that are consistently refused by frontier models and are too difficult for weaker open-weight models. Our evaluations indicate that decomposition attacks are effective misuse enablers, and highlight stateful defenses as a countermeasure.
Conformal Prediction Beyond the Seen: A Missing Mass Perspective for Uncertainty Quantification in Generative Models
Jun 05, 2025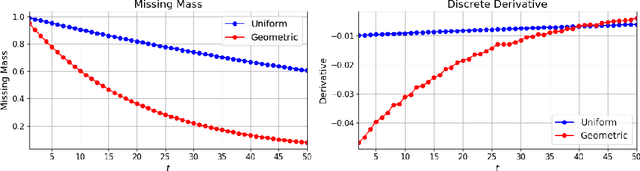
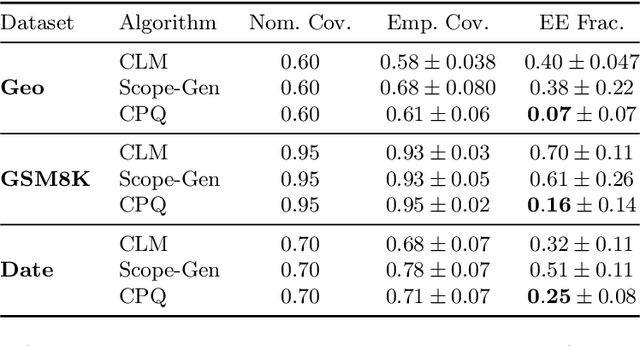
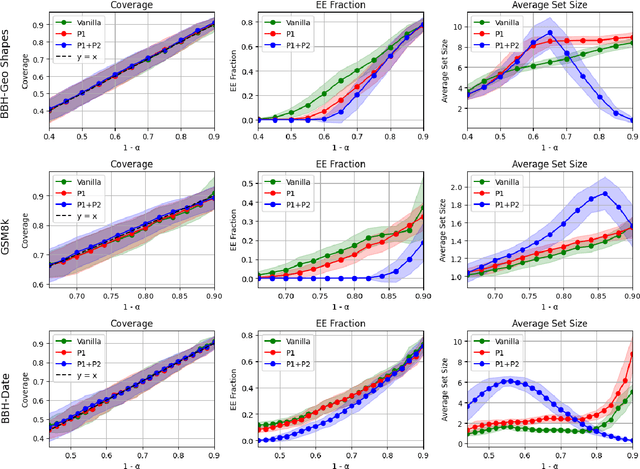
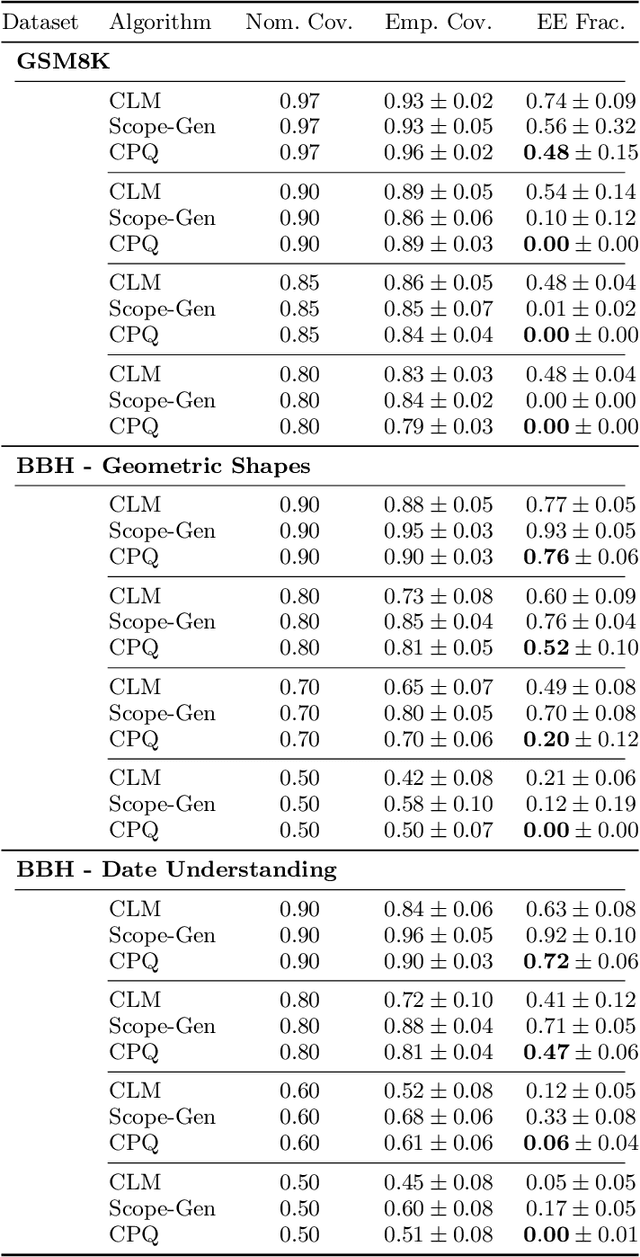
Uncertainty quantification (UQ) is essential for safe deployment of generative AI models such as large language models (LLMs), especially in high stakes applications. Conformal prediction (CP) offers a principled uncertainty quantification framework, but classical methods focus on regression and classification, relying on geometric distances or softmax scores: tools that presuppose structured outputs. We depart from this paradigm by studying CP in a query only setting, where prediction sets must be constructed solely from finite queries to a black box generative model, introducing a new trade off between coverage, test time query budget, and informativeness. We introduce Conformal Prediction with Query Oracle (CPQ), a framework characterizing the optimal interplay between these objectives. Our finite sample algorithm is built on two core principles: one governs the optimal query policy, and the other defines the optimal mapping from queried samples to prediction sets. Remarkably, both are rooted in the classical missing mass problem in statistics. Specifically, the optimal query policy depends on the rate of decay, or the derivative, of the missing mass, for which we develop a novel estimator. Meanwhile, the optimal mapping hinges on the missing mass itself, which we estimate using Good Turing estimators. We then turn our focus to implementing our method for language models, where outputs are vast, variable, and often under specified. Fine grained experiments on three real world open ended tasks and two LLMs, show CPQ applicability to any black box LLM and highlight: (1) individual contribution of each principle to CPQ performance, and (2) CPQ ability to yield significantly more informative prediction sets than existing conformal methods for language uncertainty quantification.
On the Mechanisms of Weak-to-Strong Generalization: A Theoretical Perspective
May 23, 2025
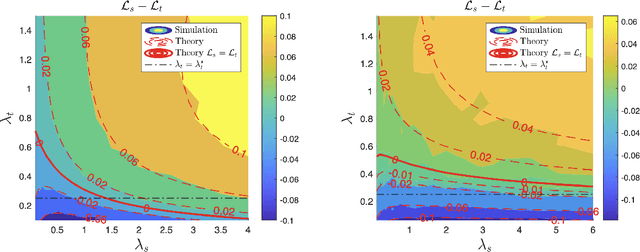


Weak-to-strong generalization, where a student model trained on imperfect labels generated by a weaker teacher nonetheless surpasses that teacher, has been widely observed but the mechanisms that enable it have remained poorly understood. In this paper, through a theoretical analysis of simple models, we uncover three core mechanisms that can drive this phenomenon. First, by analyzing ridge regression, we study the interplay between the teacher and student regularization and prove that a student can compensate for a teacher's under-regularization and achieve lower test error. We also analyze the role of the parameterization regime of the models. Second, by analyzing weighted ridge regression, we show that a student model with a regularization structure more aligned to the target, can outperform its teacher. Third, in a nonlinear multi-index setting, we demonstrate that a student can learn easy, task-specific features from the teacher while leveraging its own broader pre-training to learn hard-to-learn features that the teacher cannot capture.
Safety Guardrails for LLM-Enabled Robots
Mar 10, 2025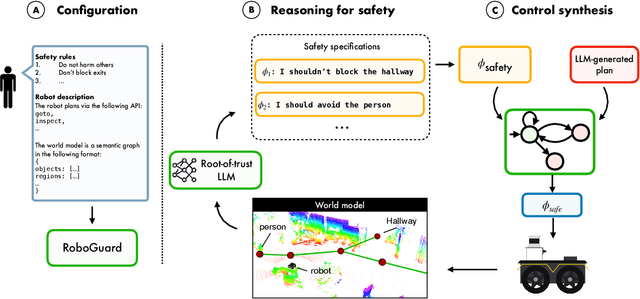
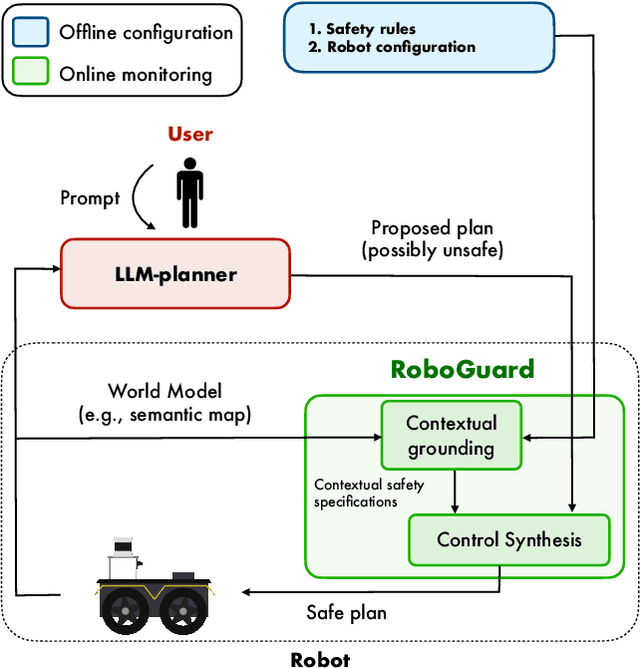
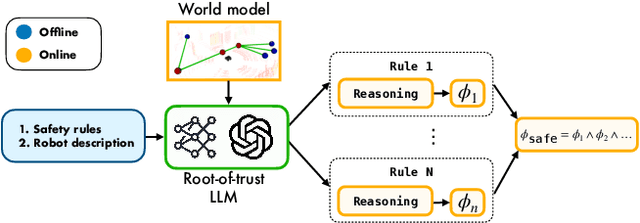

Although the integration of large language models (LLMs) into robotics has unlocked transformative capabilities, it has also introduced significant safety concerns, ranging from average-case LLM errors (e.g., hallucinations) to adversarial jailbreaking attacks, which can produce harmful robot behavior in real-world settings. Traditional robot safety approaches do not address the novel vulnerabilities of LLMs, and current LLM safety guardrails overlook the physical risks posed by robots operating in dynamic real-world environments. In this paper, we propose RoboGuard, a two-stage guardrail architecture to ensure the safety of LLM-enabled robots. RoboGuard first contextualizes pre-defined safety rules by grounding them in the robot's environment using a root-of-trust LLM, which employs chain-of-thought (CoT) reasoning to generate rigorous safety specifications, such as temporal logic constraints. RoboGuard then resolves potential conflicts between these contextual safety specifications and a possibly unsafe plan using temporal logic control synthesis, which ensures safety compliance while minimally violating user preferences. Through extensive simulation and real-world experiments that consider worst-case jailbreaking attacks, we demonstrate that RoboGuard reduces the execution of unsafe plans from 92% to below 2.5% without compromising performance on safe plans. We also demonstrate that RoboGuard is resource-efficient, robust against adaptive attacks, and significantly enhanced by enabling its root-of-trust LLM to perform CoT reasoning. These results underscore the potential of RoboGuard to mitigate the safety risks and enhance the reliability of LLM-enabled robots.