 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiRisk: Multiple Risk Control via Iterative Score Thresholding
Dec 31, 2025As generative AI systems are increasingly deployed in real-world applications, regulating multiple dimensions of model behavior has become essential. We focus on test-time filtering: a lightweight mechanism for behavior control that compares performance scores to estimated thresholds, and modifies outputs when these bounds are violated. We formalize the problem of enforcing multiple risk constraints with user-defined priorities, and introduce two efficient dynamic programming algorithms that leverage this sequential structure. The first, MULTIRISK-BASE, provides a direct finite-sample procedure for selecting thresholds, while the second, MULTIRISK, leverages data exchangeability to guarantee simultaneous control of the risks. Under mild assumptions, we show that MULTIRISK achieves nearly tight control of all constraint risks. The analysis requires an intricate iterative argument, upper bounding the risks by introducing several forms of intermediate symmetrized risk functions, and carefully lower bounding the risks by recursively counting jumps in symmetrized risk functions between appropriate risk levels. We evaluate our framework on a three-constraint Large Language Model alignment task using the PKU-SafeRLHF dataset, where the goal is to maximize helpfulness subject to multiple safety constraints, and where scores are generated by a Large Language Model judge and a perplexity filter. Our experimental results show that our algorithm can control each individual risk at close to the target level.
Foundations of Top-$k$ Decoding For Language Models
May 25, 2025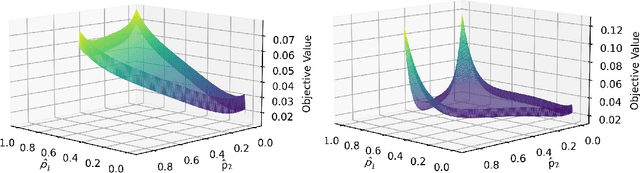

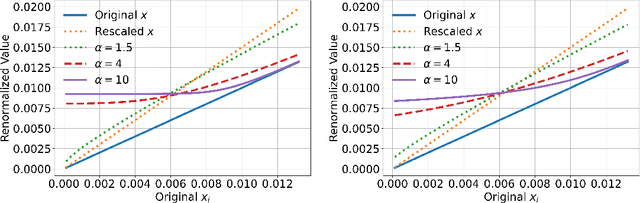

Top-$k$ decoding is a widely used method for sampling from LLMs: at each token, only the largest $k$ next-token-probabilities are kept, and the next token is sampled after re-normalizing them to sum to unity. Top-$k$ and other sampling methods are motivated by the intuition that true next-token distributions are sparse, and the noisy LLM probabilities need to be truncated. However, to our knowledge, a precise theoretical motivation for the use of top-$k$ decoding is missing. In this work, we develop a theoretical framework that both explains and generalizes top-$k$ decoding. We view decoding at a fixed token as the recovery of a sparse probability distribution. We consider \emph{Bregman decoders} obtained by minimizing a separable Bregman divergence (for both the \emph{primal} and \emph{dual} cases) with a sparsity-inducing $\ell_0$ regularization. Despite the combinatorial nature of the objective, we show how to optimize it efficiently for a large class of divergences. We show that the optimal decoding strategies are greedy, and further that the loss function is discretely convex in $k$, so that binary search provably and efficiently finds the optimal $k$. We show that top-$k$ decoding arises as a special case for the KL divergence, and identify new decoding strategies that have distinct behaviors (e.g., non-linearly up-weighting larger probabilities after re-normalization).
Likelihood-Ratio Regularized Quantile Regression: Adapting Conformal Prediction to High-Dimensional Covariate Shifts
Feb 18, 2025We consider the problem of conformal prediction under covariate shift. Given labeled data from a source domain and unlabeled data from a covariate shifted target domain, we seek to construct prediction sets with valid marginal coverage in the target domain. Most existing methods require estimating the unknown likelihood ratio function, which can be prohibitive for high-dimensional data such as images. To address this challenge, we introduce the likelihood ratio regularized quantile regression (LR-QR) algorithm, which combines the pinball loss with a novel choice of regularization in order to construct a threshold function without directly estimating the unknown likelihood ratio. We show that the LR-QR method has coverage at the desired level in the target domain, up to a small error term that we can control. Our proofs draw on a novel analysis of coverage via stability bounds from learning theory. Our experiments demonstrate that the LR-QR algorithm outperforms existing methods on high-dimensional prediction tasks, including a regression task for the Communities and Crime dataset, and an image classification task from the WILDS repository.