 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Decision Support for AI Agents
Jun 10, 2026Traditionally, decision support studies how humans use machine learning models to make better decisions. In modern agentic systems, this division of roles is increasingly reversed: AI agents act on behalf of users, while humans and tools becomes support mechanisms around them. This role reversal brings reliability concerns to the forefront, since agentic errors can be consequential and agent behavior must remain aligned with human goals and constraints. Departing from the classical view of decision support, we revisit its two basic principles, the cost--value tradeoff of seeking support and the role of uncertainty quantification, in a setting where AI agents are the central actors. We propose a framework for strategic decision support for AI agents through an optimization problem that minimizes support usage subject to controlling a counterfactual missed-support error: the probability that the agent acts alone on instances where support would have materially improved its output. At the population level, we show that the optimal policy is a threshold rule on the value of support. Building on this structure, we develop an online algorithm that adaptively thresholds such a score and uses randomized exploration to control missed-support error without distributional assumptions. We further introduce a calibration-on-the-fly method that reduces unnecessary support calls online. We instantiate this framework across diverse scenarios, including information gathering, human--AI collaboration, and tool use, showing how each can be modeled through the same strategic decision-support lens. Experiments across these settings show that our method reliably controls the target error while substantially reducing support usage in practice.
Conformal Risk-Averse Decision Making with Action Conditional Guarantee
Jun 04, 2026Reliable decision making pipelines powered by machine learning models require uncertainty quantification (UQ) methods that come with explicit safety guarantees. Conformal prediction provides such UQ by wrapping ML predictions into prediction sets, and recent work by Kiyani et al. (2025b) established that these sets can be translated into optimal risk-averse decision policies -- yet only inheriting marginal safety guarantees. We generalize and strengthen their results by (i) introducing action-conditional conformal prediction, which yields safety guarantees conditioned explicitly on each action taken by the decision maker, (ii) showing that action-conditional prediction sets serve as a proxy for the feasible decision space for risk-averse decision makers aiming to optimize action-conditional value-at-risk, and (iii) proposing a principled finite-sample algorithm based on pinball-loss minimization, connecting the framework of Gibbs et al. (2025) to action-conditional guarantees. Experiments on two real-world datasets confirm that our approach significantly improves action-conditional performance over conformal baselines.
When to Trust the Cheap Check: Weak and Strong Verification for Reasoning
Feb 19, 2026Reasoning with LLMs increasingly unfolds inside a broader verification loop. Internally, systems use cheap checks, such as self-consistency or proxy rewards, which we call weak verification. Externally, users inspect outputs and steer the model through feedback until results are trustworthy, which we call strong verification. These signals differ sharply in cost and reliability: strong verification can establish trust but is resource-intensive, while weak verification is fast and scalable but noisy and imperfect. We formalize this tension through weak--strong verification policies, which decide when to accept or reject based on weak verification and when to defer to strong verification. We introduce metrics capturing incorrect acceptance, incorrect rejection, and strong-verification frequency. Over population, we show that optimal policies admit a two-threshold structure and that calibration and sharpness govern the value of weak verifiers. Building on this, we develop an online algorithm that provably controls acceptance and rejection errors without assumptions on the query stream, the language model, or the weak verifier.
Multi-Round Human-AI Collaboration with User-Specified Requirements
Feb 19, 2026As humans increasingly rely on multiround conversational AI for high stakes decisions, principled frameworks are needed to ensure such interactions reliably improve decision quality. We adopt a human centric view governed by two principles: counterfactual harm, ensuring the AI does not undermine human strengths, and complementarity, ensuring it adds value where the human is prone to err. We formalize these concepts via user defined rules, allowing users to specify exactly what harm and complementarity mean for their specific task. We then introduce an online, distribution free algorithm with finite sample guarantees that enforces the user-specified constraints over the collaboration dynamics. We evaluate our framework across two interactive settings: LLM simulated collaboration on a medical diagnostic task and a human crowdsourcing study on a pictorial reasoning task. We show that our online procedure maintains prescribed counterfactual harm and complementarity violation rates even under nonstationary interaction dynamics. Moreover, tightening or loosening these constraints produces predictable shifts in downstream human accuracy, confirming that the two principles serve as practical levers for steering multi-round collaboration toward better decision quality without the need to model or constrain human behavior.
Conformal Prediction Beyond the Seen: A Missing Mass Perspective for Uncertainty Quantification in Generative Models
Jun 05, 2025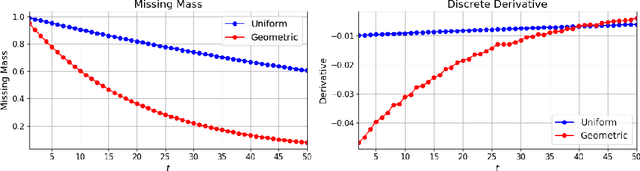
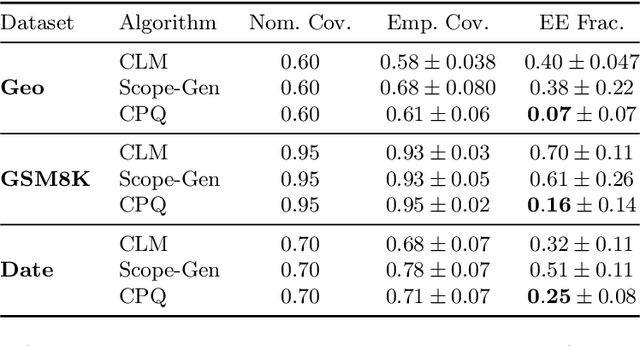
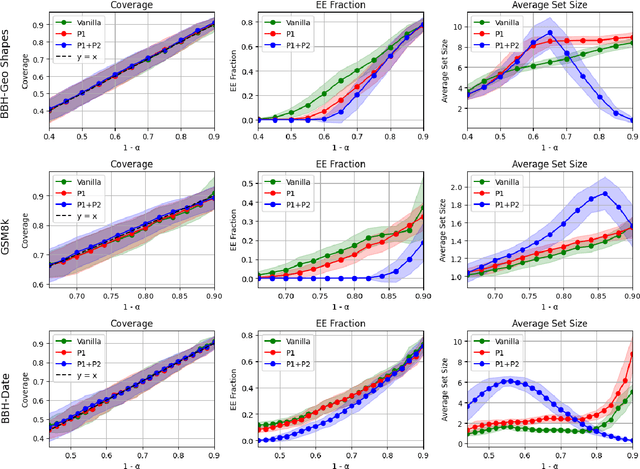
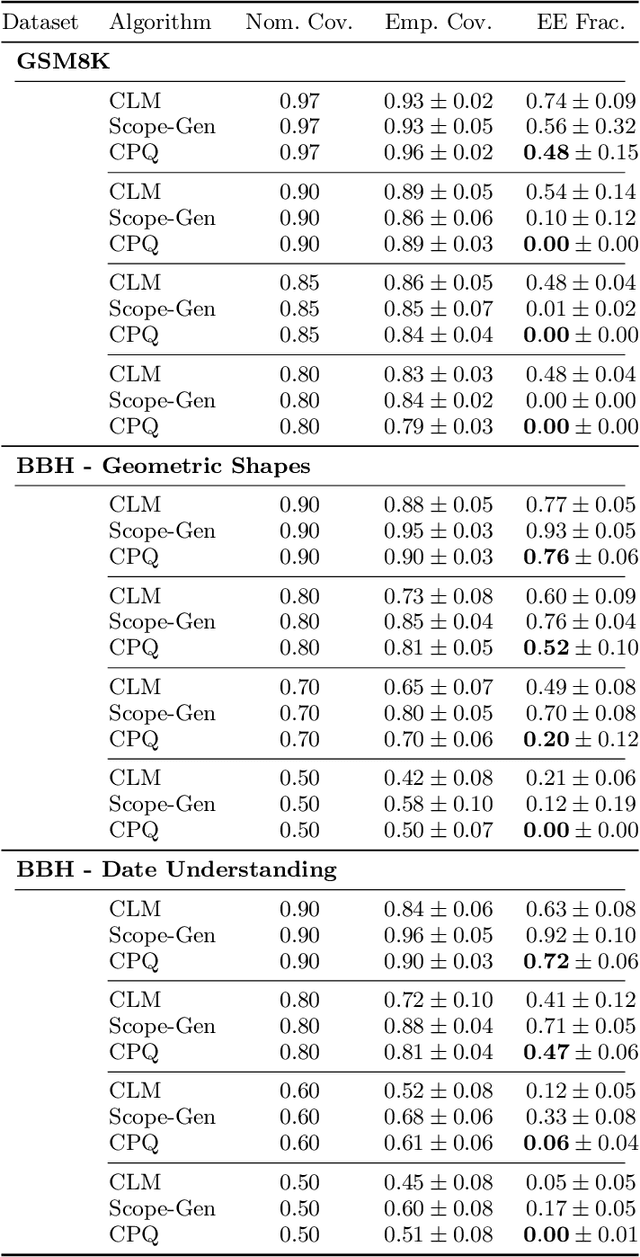
Uncertainty quantification (UQ) is essential for safe deployment of generative AI models such as large language models (LLMs), especially in high stakes applications. Conformal prediction (CP) offers a principled uncertainty quantification framework, but classical methods focus on regression and classification, relying on geometric distances or softmax scores: tools that presuppose structured outputs. We depart from this paradigm by studying CP in a query only setting, where prediction sets must be constructed solely from finite queries to a black box generative model, introducing a new trade off between coverage, test time query budget, and informativeness. We introduce Conformal Prediction with Query Oracle (CPQ), a framework characterizing the optimal interplay between these objectives. Our finite sample algorithm is built on two core principles: one governs the optimal query policy, and the other defines the optimal mapping from queried samples to prediction sets. Remarkably, both are rooted in the classical missing mass problem in statistics. Specifically, the optimal query policy depends on the rate of decay, or the derivative, of the missing mass, for which we develop a novel estimator. Meanwhile, the optimal mapping hinges on the missing mass itself, which we estimate using Good Turing estimators. We then turn our focus to implementing our method for language models, where outputs are vast, variable, and often under specified. Fine grained experiments on three real world open ended tasks and two LLMs, show CPQ applicability to any black box LLM and highlight: (1) individual contribution of each principle to CPQ performance, and (2) CPQ ability to yield significantly more informative prediction sets than existing conformal methods for language uncertainty quantification.
Likelihood-Ratio Regularized Quantile Regression: Adapting Conformal Prediction to High-Dimensional Covariate Shifts
Feb 18, 2025We consider the problem of conformal prediction under covariate shift. Given labeled data from a source domain and unlabeled data from a covariate shifted target domain, we seek to construct prediction sets with valid marginal coverage in the target domain. Most existing methods require estimating the unknown likelihood ratio function, which can be prohibitive for high-dimensional data such as images. To address this challenge, we introduce the likelihood ratio regularized quantile regression (LR-QR) algorithm, which combines the pinball loss with a novel choice of regularization in order to construct a threshold function without directly estimating the unknown likelihood ratio. We show that the LR-QR method has coverage at the desired level in the target domain, up to a small error term that we can control. Our proofs draw on a novel analysis of coverage via stability bounds from learning theory. Our experiments demonstrate that the LR-QR algorithm outperforms existing methods on high-dimensional prediction tasks, including a regression task for the Communities and Crime dataset, and an image classification task from the WILDS repository.
Decision Theoretic Foundations for Conformal Prediction: Optimal Uncertainty Quantification for Risk-Averse Agents
Feb 04, 2025



A fundamental question in data-driven decision making is how to quantify the uncertainty of predictions in ways that can usefully inform downstream action. This interface between prediction uncertainty and decision-making is especially important in risk-sensitive domains, such as medicine. In this paper, we develop decision-theoretic foundations that connect uncertainty quantification using prediction sets with risk-averse decision-making. Specifically, we answer three fundamental questions: (1) What is the correct notion of uncertainty quantification for risk-averse decision makers? We prove that prediction sets are optimal for decision makers who wish to optimize their value at risk. (2) What is the optimal policy that a risk averse decision maker should use to map prediction sets to actions? We show that a simple max-min decision policy is optimal for risk-averse decision makers. Finally, (3) How can we derive prediction sets that are optimal for such decision makers? We provide an exact characterization in the population regime and a distribution free finite-sample construction. Answering these questions naturally leads to an algorithm, Risk-Averse Calibration (RAC), which follows a provably optimal design for deriving action policies from predictions. RAC is designed to be both practical-capable of leveraging the quality of predictions in a black-box manner to enhance downstream utility-and safe-adhering to a user-defined risk threshold and optimizing the corresponding risk quantile of the user's downstream utility. Finally, we experimentally demonstrate the significant advantages of RAC in applications such as medical diagnosis and recommendation systems. Specifically, we show that RAC achieves a substantially improved trade-off between safety and utility, offering higher utility compared to existing methods while maintaining the safety guarantee.
Length Optimization in Conformal Prediction
Jun 27, 2024



Conditional validity and length efficiency are two crucial aspects of conformal prediction (CP). Achieving conditional validity ensures accurate uncertainty quantification for data subpopulations, while proper length efficiency ensures that the prediction sets remain informative and non-trivial. Despite significant efforts to address each of these issues individually, a principled framework that reconciles these two objectives has been missing in the CP literature. In this paper, we develop Conformal Prediction with Length-Optimization (CPL) - a novel framework that constructs prediction sets with (near-) optimal length while ensuring conditional validity under various classes of covariate shifts, including the key cases of marginal and group-conditional coverage. In the infinite sample regime, we provide strong duality results which indicate that CPL achieves conditional validity and length optimality. In the finite sample regime, we show that CPL constructs conditionally valid prediction sets. Our extensive empirical evaluations demonstrate the superior prediction set size performance of CPL compared to state-of-the-art methods across diverse real-world and synthetic datasets in classification, regression, and text-related settings.
Conformal Prediction with Learned Features
Apr 26, 2024



In this paper, we focus on the problem of conformal prediction with conditional guarantees. Prior work has shown that it is impossible to construct nontrivial prediction sets with full conditional coverage guarantees. A wealth of research has considered relaxations of full conditional guarantees, relying on some predefined uncertainty structures. Departing from this line of thinking, we propose Partition Learning Conformal Prediction (PLCP), a framework to improve conditional validity of prediction sets through learning uncertainty-guided features from the calibration data. We implement PLCP efficiently with alternating gradient descent, utilizing off-the-shelf machine learning models. We further analyze PLCP theoretically and provide conditional guarantees for infinite and finite sample sizes. Finally, our experimental results over four real-world and synthetic datasets show the superior performance of PLCP compared to state-of-the-art methods in terms of coverage and length in both classification and regression scenarios.
Beyond the Universal Law of Robustness: Sharper Laws for Random Features and Neural Tangent Kernels
Feb 03, 2023Machine learning models are vulnerable to adversarial perturbations, and a thought-provoking paper by Bubeck and Sellke has analyzed this phenomenon through the lens of over-parameterization: interpolating smoothly the data requires significantly more parameters than simply memorizing it. However, this "universal" law provides only a necessary condition for robustness, and it is unable to discriminate between models. In this paper, we address these gaps by focusing on empirical risk minimization in two prototypical settings, namely, random features and the neural tangent kernel (NTK). We prove that, for random features, the model is not robust for any degree of over-parameterization, even when the necessary condition coming from the universal law of robustness is satisfied. In contrast, for even activations, the NTK model meets the universal lower bound, and it is robust as soon as the necessary condition on over-parameterization is fulfilled. This also addresses a conjecture in prior work by Bubeck, Li and Nagaraj. Our analysis decouples the effect of the kernel of the model from an "interaction matrix", which describes the interaction with the test data and captures the effect of the activation. Our theoretical results are corroborated by numerical evidence on both synthetic and standard datasets (MNIST, CIFAR-10).