 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Decision-Making Based on Prediction Sets
Feb 03, 2026Prediction sets can wrap around any ML model to cover unknown test outcomes with a guaranteed probability. Yet, it remains unclear how to use them optimally for downstream decision-making. Here, we propose a decision-theoretic framework that seeks to minimize the expected loss (risk) against a worst-case distribution consistent with the prediction set's coverage guarantee. We first characterize the minimax optimal policy for a fixed prediction set, showing that it balances the worst-case loss inside the set with a penalty for potential losses outside the set. Building on this, we derive the optimal prediction set construction that minimizes the resulting robust risk subject to a coverage constraint. Finally, we introduce Risk-Optimal Conformal Prediction (ROCP), a practical algorithm that targets these risk-minimizing sets while maintaining finite-sample distribution-free marginal coverage. Empirical evaluations on medical diagnosis and safety-critical decision-making tasks demonstrate that ROCP reduces critical mistakes compared to baselines, particularly when out-of-set errors are costly.
Online Conformal Prediction via Universal Portfolio Algorithms
Feb 03, 2026Online conformal prediction (OCP) seeks prediction intervals that achieve long-run $1-α$ coverage for arbitrary (possibly adversarial) data streams, while remaining as informative as possible. Existing OCP methods often require manual learning-rate tuning to work well, and may also require algorithm-specific analyses. Here, we develop a general regret-to-coverage theory for interval-valued OCP based on the $(1-α)$-pinball loss. Our first contribution is to identify \emph{linearized regret} as a key notion, showing that controlling it implies coverage bounds for any online algorithm. This relies on a black-box reduction that depends only on the Fenchel conjugate of an upper bound on the linearized regret. Building on this theory, we propose UP-OCP, a parameter-free method for OCP, via a reduction to a two-asset portfolio selection problem, leveraging universal portfolio algorithms. We show strong finite-time bounds on the miscoverage of UP-OCP, even for polynomially growing predictions. Extensive experiments support that UP-OCP delivers consistently better size/coverage trade-offs than prior online conformal baselines.
MultiRisk: Multiple Risk Control via Iterative Score Thresholding
Dec 31, 2025As generative AI systems are increasingly deployed in real-world applications, regulating multiple dimensions of model behavior has become essential. We focus on test-time filtering: a lightweight mechanism for behavior control that compares performance scores to estimated thresholds, and modifies outputs when these bounds are violated. We formalize the problem of enforcing multiple risk constraints with user-defined priorities, and introduce two efficient dynamic programming algorithms that leverage this sequential structure. The first, MULTIRISK-BASE, provides a direct finite-sample procedure for selecting thresholds, while the second, MULTIRISK, leverages data exchangeability to guarantee simultaneous control of the risks. Under mild assumptions, we show that MULTIRISK achieves nearly tight control of all constraint risks. The analysis requires an intricate iterative argument, upper bounding the risks by introducing several forms of intermediate symmetrized risk functions, and carefully lower bounding the risks by recursively counting jumps in symmetrized risk functions between appropriate risk levels. We evaluate our framework on a three-constraint Large Language Model alignment task using the PKU-SafeRLHF dataset, where the goal is to maximize helpfulness subject to multiple safety constraints, and where scores are generated by a Large Language Model judge and a perplexity filter. Our experimental results show that our algorithm can control each individual risk at close to the target level.
Statistical Methods in Generative AI
Sep 08, 2025Generative Artificial Intelligence is emerging as an important technology, promising to be transformative in many areas. At the same time, generative AI techniques are based on sampling from probabilistic models, and by default, they come with no guarantees about correctness, safety, fairness, or other properties. Statistical methods offer a promising potential approach to improve the reliability of generative AI techniques. In addition, statistical methods are also promising for improving the quality and efficiency of AI evaluation, as well as for designing interventions and experiments in AI. In this paper, we review some of the existing work on these topics, explaining both the general statistical techniques used, as well as their applications to generative AI. We also discuss limitations and potential future directions.
Foundations of Top-$k$ Decoding For Language Models
May 25, 2025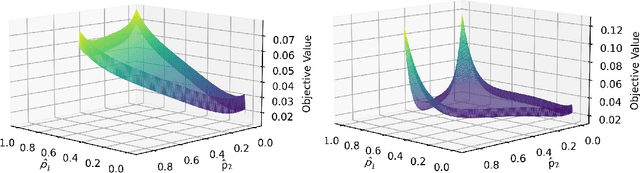

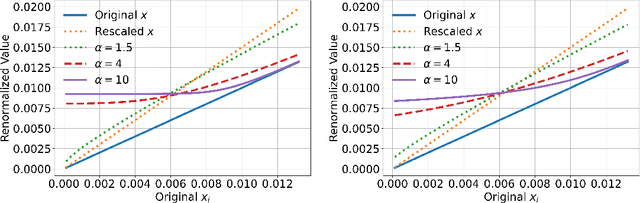

Top-$k$ decoding is a widely used method for sampling from LLMs: at each token, only the largest $k$ next-token-probabilities are kept, and the next token is sampled after re-normalizing them to sum to unity. Top-$k$ and other sampling methods are motivated by the intuition that true next-token distributions are sparse, and the noisy LLM probabilities need to be truncated. However, to our knowledge, a precise theoretical motivation for the use of top-$k$ decoding is missing. In this work, we develop a theoretical framework that both explains and generalizes top-$k$ decoding. We view decoding at a fixed token as the recovery of a sparse probability distribution. We consider \emph{Bregman decoders} obtained by minimizing a separable Bregman divergence (for both the \emph{primal} and \emph{dual} cases) with a sparsity-inducing $\ell_0$ regularization. Despite the combinatorial nature of the objective, we show how to optimize it efficiently for a large class of divergences. We show that the optimal decoding strategies are greedy, and further that the loss function is discretely convex in $k$, so that binary search provably and efficiently finds the optimal $k$. We show that top-$k$ decoding arises as a special case for the KL divergence, and identify new decoding strategies that have distinct behaviors (e.g., non-linearly up-weighting larger probabilities after re-normalization).
Synthetic-Powered Predictive Inference
May 19, 2025Conformal prediction is a framework for predictive inference with a distribution-free, finite-sample guarantee. However, it tends to provide uninformative prediction sets when calibration data are scarce. This paper introduces Synthetic-powered predictive inference (SPPI), a novel framework that incorporates synthetic data -- e.g., from a generative model -- to improve sample efficiency. At the core of our method is a score transporter: an empirical quantile mapping that aligns nonconformity scores from trusted, real data with those from synthetic data. By carefully integrating the score transporter into the calibration process, SPPI provably achieves finite-sample coverage guarantees without making any assumptions about the real and synthetic data distributions. When the score distributions are well aligned, SPPI yields substantially tighter and more informative prediction sets than standard conformal prediction. Experiments on image classification and tabular regression demonstrate notable improvements in predictive efficiency in data-scarce settings.
Likelihood-Ratio Regularized Quantile Regression: Adapting Conformal Prediction to High-Dimensional Covariate Shifts
Feb 18, 2025We consider the problem of conformal prediction under covariate shift. Given labeled data from a source domain and unlabeled data from a covariate shifted target domain, we seek to construct prediction sets with valid marginal coverage in the target domain. Most existing methods require estimating the unknown likelihood ratio function, which can be prohibitive for high-dimensional data such as images. To address this challenge, we introduce the likelihood ratio regularized quantile regression (LR-QR) algorithm, which combines the pinball loss with a novel choice of regularization in order to construct a threshold function without directly estimating the unknown likelihood ratio. We show that the LR-QR method has coverage at the desired level in the target domain, up to a small error term that we can control. Our proofs draw on a novel analysis of coverage via stability bounds from learning theory. Our experiments demonstrate that the LR-QR algorithm outperforms existing methods on high-dimensional prediction tasks, including a regression task for the Communities and Crime dataset, and an image classification task from the WILDS repository.
A Confidence Interval for the $\ell_2$ Expected Calibration Error
Aug 16, 2024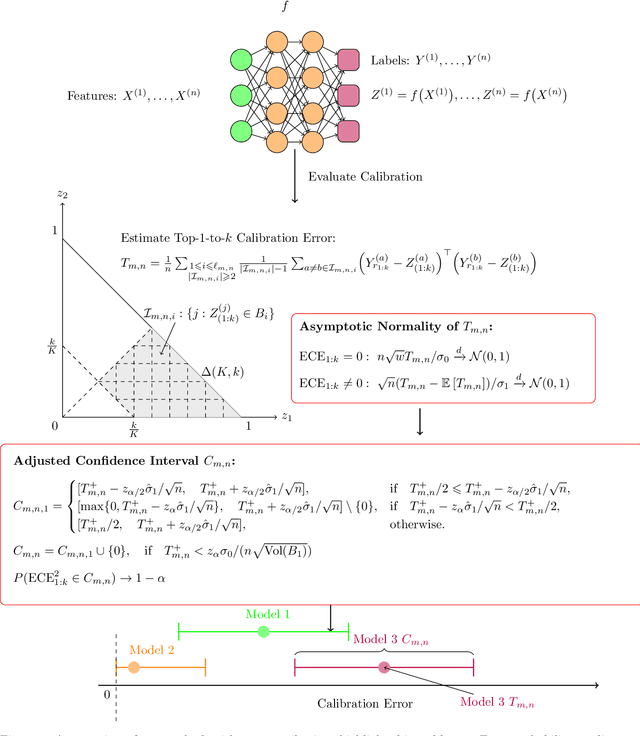
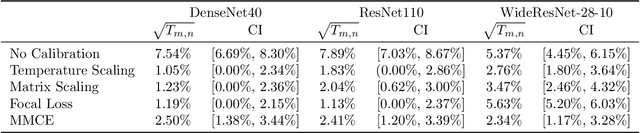
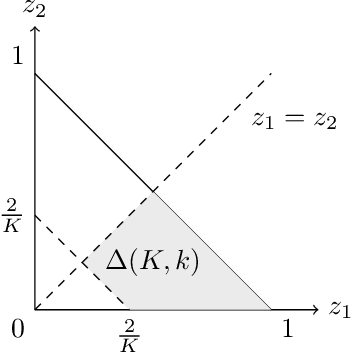

Recent advances in machine learning have significantly improved prediction accuracy in various applications. However, ensuring the calibration of probabilistic predictions remains a significant challenge. Despite efforts to enhance model calibration, the rigorous statistical evaluation of model calibration remains less explored. In this work, we develop confidence intervals the $\ell_2$ Expected Calibration Error (ECE). We consider top-1-to-$k$ calibration, which includes both the popular notion of confidence calibration as well as full calibration. For a debiased estimator of the ECE, we show asymptotic normality, but with different convergence rates and asymptotic variances for calibrated and miscalibrated models. We develop methods to construct asymptotically valid confidence intervals for the ECE, accounting for this behavior as well as non-negativity. Our theoretical findings are supported through extensive experiments, showing that our methods produce valid confidence intervals with shorter lengths compared to those obtained by resampling-based methods.
Watermarking Language Models with Error Correcting Codes
Jun 12, 2024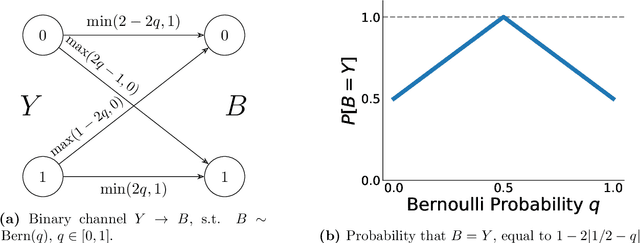
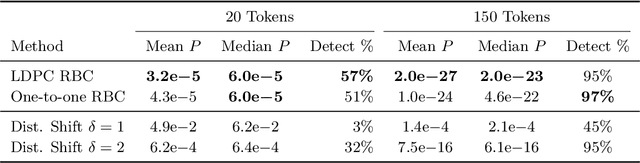
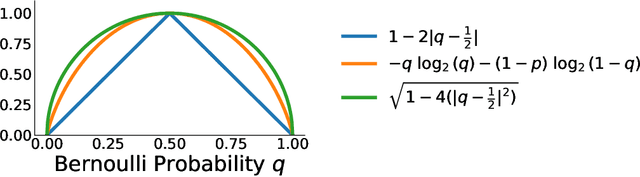
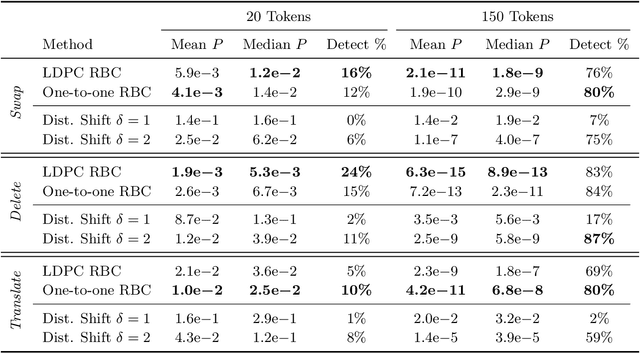
Recent progress in large language models enables the creation of realistic machine-generated content. Watermarking is a promising approach to distinguish machine-generated text from human text, embedding statistical signals in the output that are ideally undetectable to humans. We propose a watermarking framework that encodes such signals through an error correcting code. Our method, termed robust binary code (RBC) watermark, introduces no distortion compared to the original probability distribution, and no noticeable degradation in quality. We evaluate our watermark on base and instruction fine-tuned models and find our watermark is robust to edits, deletions, and translations. We provide an information-theoretic perspective on watermarking, a powerful statistical test for detection and for generating p-values, and theoretical guarantees. Our empirical findings suggest our watermark is fast, powerful, and robust, comparing favorably to the state-of-the-art.
One-Shot Safety Alignment for Large Language Models via Optimal Dualization
May 29, 2024The growing safety concerns surrounding Large Language Models (LLMs) raise an urgent need to align them with diverse human preferences to simultaneously enhance their helpfulness and safety. A promising approach is to enforce safety constraints through Reinforcement Learning from Human Feedback (RLHF). For such constrained RLHF, common Lagrangian-based primal-dual policy optimization methods are computationally expensive and often unstable. This paper presents a dualization perspective that reduces constrained alignment to an equivalent unconstrained alignment problem. We do so by pre-optimizing a smooth and convex dual function that has a closed form. This shortcut eliminates the need for cumbersome primal-dual policy iterations, thus greatly reducing the computational burden and improving training stability. Our strategy leads to two practical algorithms in model-based and preference-based scenarios (MoCAN and PeCAN, respectively). A broad range of experiments demonstrate the effectiveness of our methods.