 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Language Models with Error Correcting Codes
Paper and Code
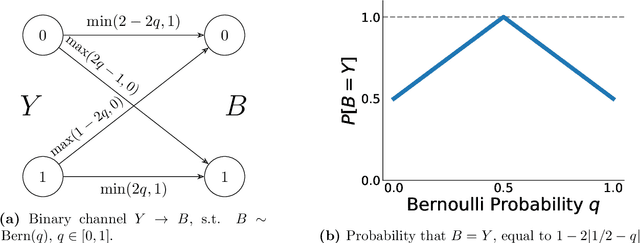
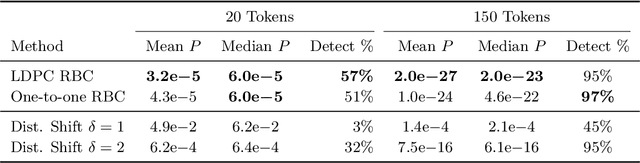
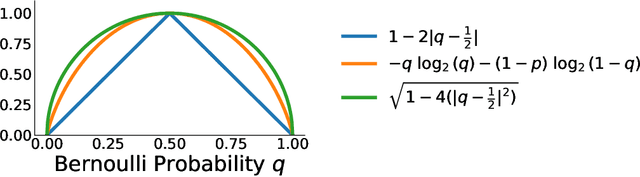
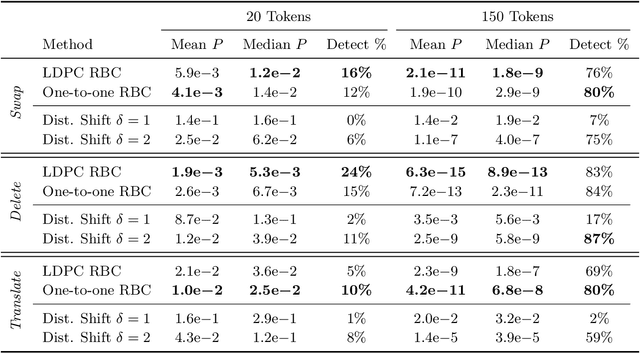
Recent progress in large language models enables the creation of realistic machine-generated content. Watermarking is a promising approach to distinguish machine-generated text from human text, embedding statistical signals in the output that are ideally undetectable to humans. We propose a watermarking framework that encodes such signals through an error correcting code. Our method, termed robust binary code (RBC) watermark, introduces no distortion compared to the original probability distribution, and no noticeable degradation in quality. We evaluate our watermark on base and instruction fine-tuned models and find our watermark is robust to edits, deletions, and translations. We provide an information-theoretic perspective on watermarking, a powerful statistical test for detection and for generating p-values, and theoretical guarantees. Our empirical findings suggest our watermark is fast, powerful, and robust, comparing favorably to the state-of-the-art.