 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Oct 05, 2025



We introduce GDPval, a benchmark evaluating AI model capabilities on real-world economically valuable tasks. GDPval covers the majority of U.S. Bureau of Labor Statistics Work Activities for 44 occupations across the top 9 sectors contributing to U.S. GDP (Gross Domestic Product). Tasks are constructed from the representative work of industry professionals with an average of 14 years of experience. We find that frontier model performance on GDPval is improving roughly linearly over time, and that the current best frontier models are approaching industry experts in deliverable quality. We analyze the potential for frontier models, when paired with human oversight, to perform GDPval tasks cheaper and faster than unaided experts. We also demonstrate that increased reasoning effort, increased task context, and increased scaffolding improves model performance on GDPval. Finally, we open-source a gold subset of 220 tasks and provide a public automated grading service at evals.openai.com to facilitate future research in understanding real-world model capabilities.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Watermarking Language Models with Error Correcting Codes
Jun 12, 2024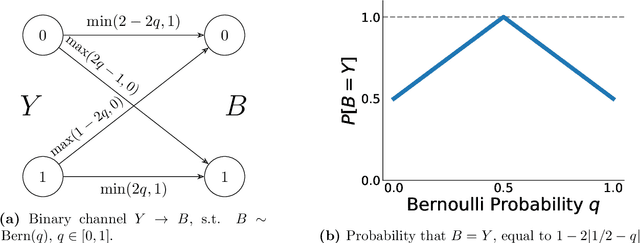
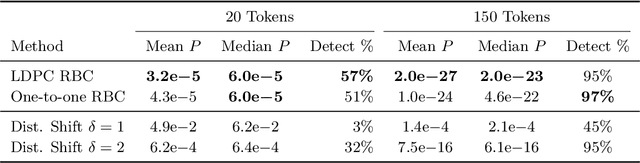
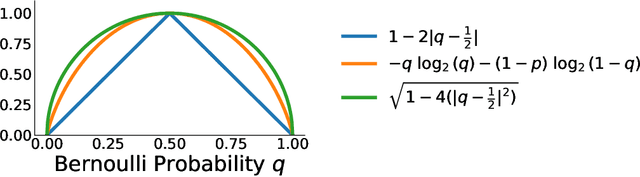
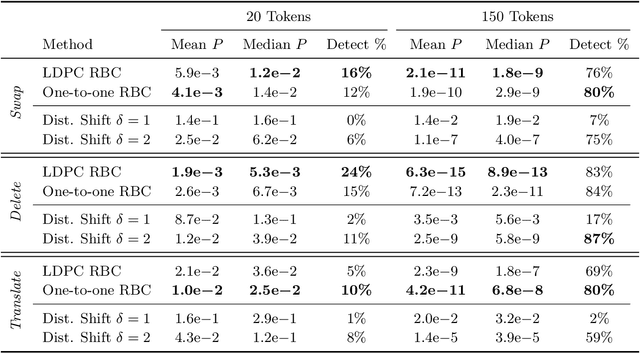
Recent progress in large language models enables the creation of realistic machine-generated content. Watermarking is a promising approach to distinguish machine-generated text from human text, embedding statistical signals in the output that are ideally undetectable to humans. We propose a watermarking framework that encodes such signals through an error correcting code. Our method, termed robust binary code (RBC) watermark, introduces no distortion compared to the original probability distribution, and no noticeable degradation in quality. We evaluate our watermark on base and instruction fine-tuned models and find our watermark is robust to edits, deletions, and translations. We provide an information-theoretic perspective on watermarking, a powerful statistical test for detection and for generating p-values, and theoretical guarantees. Our empirical findings suggest our watermark is fast, powerful, and robust, comparing favorably to the state-of-the-art.
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Mar 28, 2024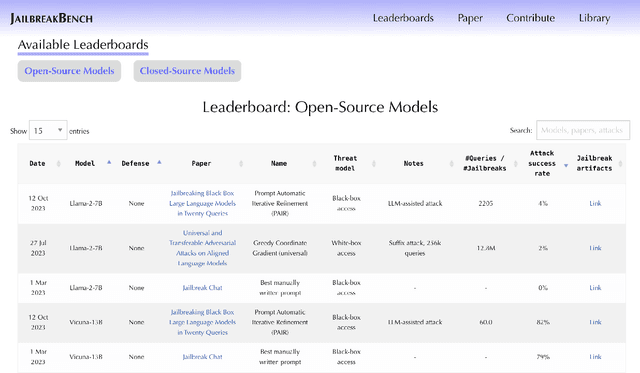


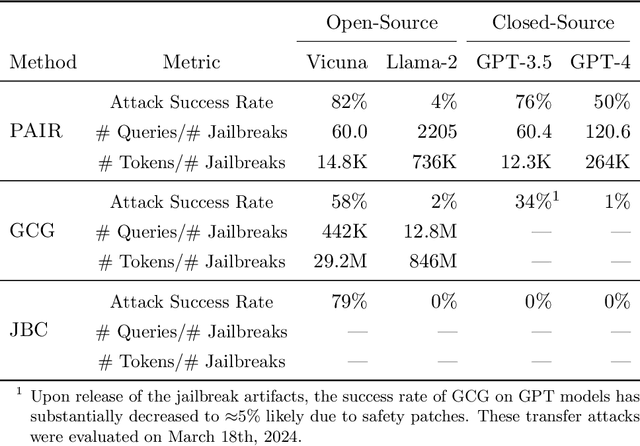
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) a new jailbreaking dataset containing 100 unique behaviors, which we call JBB-Behaviors; (2) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.
A Safe Harbor for AI Evaluation and Red Teaming
Mar 07, 2024



Independent evaluation and red teaming are critical for identifying the risks posed by generative AI systems. However, the terms of service and enforcement strategies used by prominent AI companies to deter model misuse have disincentives on good faith safety evaluations. This causes some researchers to fear that conducting such research or releasing their findings will result in account suspensions or legal reprisal. Although some companies offer researcher access programs, they are an inadequate substitute for independent research access, as they have limited community representation, receive inadequate funding, and lack independence from corporate incentives. We propose that major AI developers commit to providing a legal and technical safe harbor, indemnifying public interest safety research and protecting it from the threat of account suspensions or legal reprisal. These proposals emerged from our collective experience conducting safety, privacy, and trustworthiness research on generative AI systems, where norms and incentives could be better aligned with public interests, without exacerbating model misuse. We believe these commitments are a necessary step towards more inclusive and unimpeded community efforts to tackle the risks of generative AI.
Jailbreaking Black Box Large Language Models in Twenty Queries
Oct 13, 2023



There is growing interest in ensuring that large language models (LLMs) align with human values. However, the alignment of such models is vulnerable to adversarial jailbreaks, which coax LLMs into overriding their safety guardrails. The identification of these vulnerabilities is therefore instrumental in understanding inherent weaknesses and preventing future misuse. To this end, we propose Prompt Automatic Iterative Refinement (PAIR), an algorithm that generates semantic jailbreaks with only black-box access to an LLM. PAIR -- which is inspired by social engineering attacks -- uses an attacker LLM to automatically generate jailbreaks for a separate targeted LLM without human intervention. In this way, the attacker LLM iteratively queries the target LLM to update and refine a candidate jailbreak. Empirically, PAIR often requires fewer than twenty queries to produce a jailbreak, which is orders of magnitude more efficient than existing algorithms. PAIR also achieves competitive jailbreaking success rates and transferability on open and closed-source LLMs, including GPT-3.5/4, Vicuna, and PaLM-2.
Statistical Estimation Under Distribution Shift: Wasserstein Perturbations and Minimax Theory
Aug 03, 2023Distribution shifts are a serious concern in modern statistical learning as they can systematically change the properties of the data away from the truth. We focus on Wasserstein distribution shifts, where every data point may undergo a slight perturbation, as opposed to the Huber contamination model where a fraction of observations are outliers. We formulate and study shifts beyond independent perturbations, exploring Joint Distribution Shifts, where the per-observation perturbations can be coordinated. We analyze several important statistical problems, including location estimation, linear regression, and non-parametric density estimation. Under a squared loss for mean estimation and prediction error in linear regression, we find the exact minimax risk, a least favorable perturbation, and show that the sample mean and least squares estimators are respectively optimal. This holds for both independent and joint shifts, but the least favorable perturbations and minimax risks differ. For other problems, we provide nearly optimal estimators and precise finite-sample bounds. We also introduce several tools for bounding the minimax risk under distribution shift, such as a smoothing technique for location families, and generalizations of classical tools including least favorable sequences of priors, the modulus of continuity, Le Cam's, Fano's, and Assouad's methods.
Adversarial Prompting for Black Box Foundation Models
Feb 08, 2023Prompting interfaces allow users to quickly adjust the output of generative models in both vision and language. However, small changes and design choices in the prompt can lead to significant differences in the output. In this work, we develop a black-box framework for generating adversarial prompts for unstructured image and text generation. These prompts, which can be standalone or prepended to benign prompts, induce specific behaviors into the generative process, such as generating images of a particular object or biasing the frequency of specific letters in the generated text.
Interventional and Counterfactual Inference with Diffusion Models
Feb 02, 2023



We consider the problem of answering observational, interventional, and counterfactual queries in a causally sufficient setting where only observational data and the causal graph are available. Utilizing the recent developments in diffusion models, we introduce diffusion-based causal models (DCM) to learn causal mechanisms, that generate unique latent encodings to allow for direct sampling under interventions as well as abduction for counterfactuals. We utilize DCM to model structural equations, seeing that diffusion models serve as a natural candidate here since they encode each node to a latent representation, a proxy for the exogenous noise, and offer flexible and accurate modeling to provide reliable causal statements and estimates. Our empirical evaluations demonstrate significant improvements over existing state-of-the-art methods for answering causal queries. Our theoretical results provide a methodology for analyzing the counterfactual error for general encoder/decoder models which could be of independent interest.