 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Structural Diversity of Blackbox LLMs via Chain-of-Specification Prompting
Aug 12, 2024
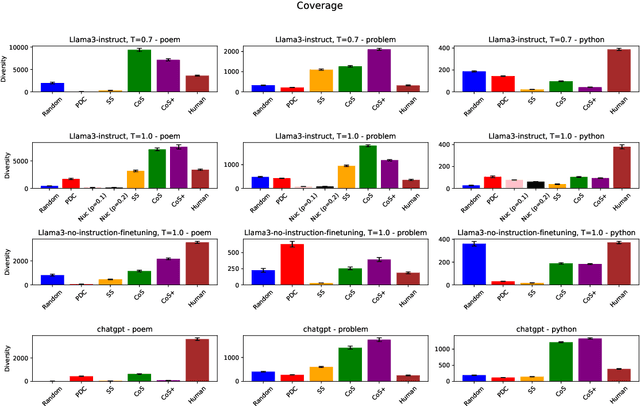
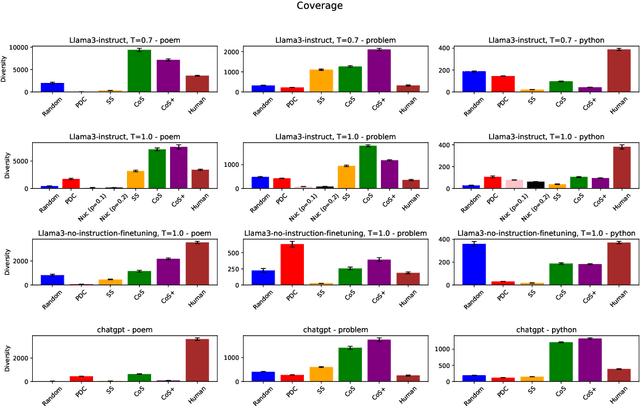
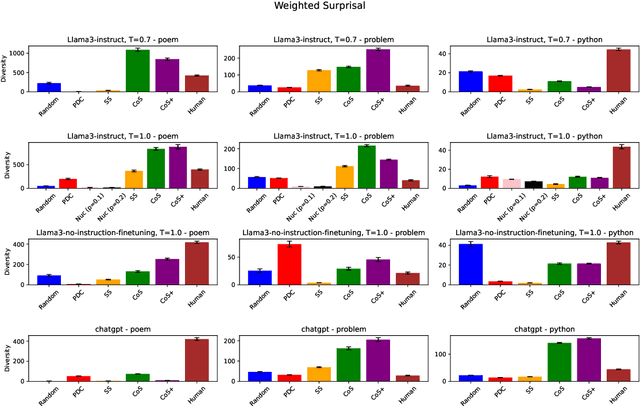
The capability to generate diverse text is a key challenge facing large language models (LLMs). Thus far, diversity has been studied via metrics such as $n$-gram diversity or diversity of BERT embeddings. However, for these kinds of diversity, the user has little control over the dimensions along which diversity is considered. For example, in the poetry domain, one might desire diversity in terms of rhyme and meter, whereas in the code domain, one might desire diversity in terms of the kinds of expressions used to solve a problem. We propose a diversity metric called structural diversity, where the user provides a mapping from generated text to features capturing the kinds of diversity that they care about. In addition, we propose a novel strategy called chain-of-specification (CoS) prompting for improving diversity by first having the LLM generate a specification encoding one instance of structural features, and then prompting the LLM to generate text that satisfies these features; notably, our strategy works with blackbox LLMs. In our experiments, we show that for structural diversity in the poetry and code domains, CoS significantly improves diversity compared to several baselines.
Generative Adversarial Bayesian Optimization for Surrogate Objectives
Feb 09, 2024


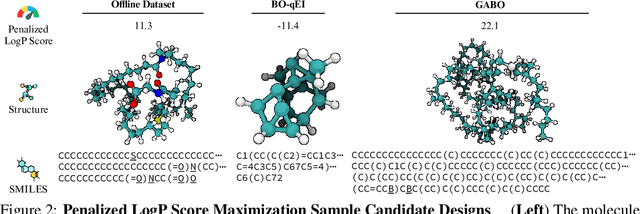
Offline model-based policy optimization seeks to optimize a learned surrogate objective function without querying the true oracle objective during optimization. However, inaccurate surrogate model predictions are frequently encountered along the optimization trajectory. To address this limitation, we propose generative adversarial Bayesian optimization (GABO) using adaptive source critic regularization, a task-agnostic framework for Bayesian optimization that employs a Lipschitz-bounded source critic model to constrain the optimization trajectory to regions where the surrogate function is reliable. We show that under certain assumptions for the continuous input space prior, our algorithm dynamically adjusts the strength of the source critic regularization. GABO outperforms existing baselines on a number of different offline optimization tasks across a variety of scientific domains. Our code is available at https://github.com/michael-s-yao/gabo
Learning to Select Pivotal Samples for Meta Re-weighting
Feb 09, 2023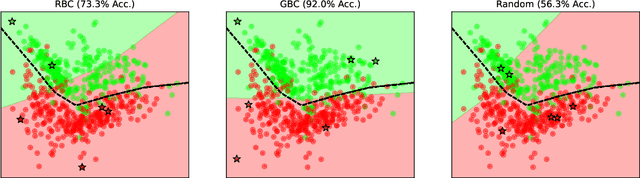
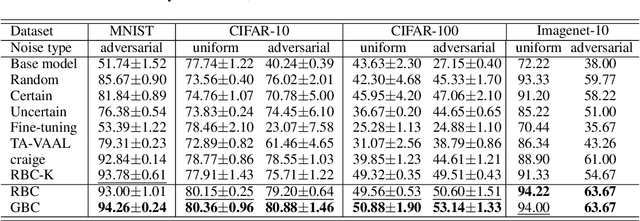
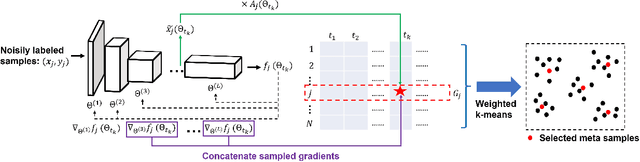
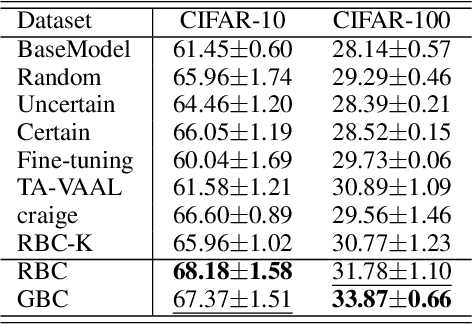
Sample re-weighting strategies provide a promising mechanism to deal with imperfect training data in machine learning, such as noisily labeled or class-imbalanced data. One such strategy involves formulating a bi-level optimization problem called the meta re-weighting problem, whose goal is to optimize performance on a small set of perfect pivotal samples, called meta samples. Many approaches have been proposed to efficiently solve this problem. However, all of them assume that a perfect meta sample set is already provided while we observe that the selections of meta sample set is performance critical. In this paper, we study how to learn to identify such a meta sample set from a large, imperfect training set, that is subsequently cleaned and used to optimize performance in the meta re-weighting setting. We propose a learning framework which reduces the meta samples selection problem to a weighted K-means clustering problem through rigorously theoretical analysis. We propose two clustering methods within our learning framework, Representation-based clustering method (RBC) and Gradient-based clustering method (GBC), for balancing performance and computational efficiency. Empirical studies demonstrate the performance advantage of our methods over various baseline methods.
Adversarial Prompting for Black Box Foundation Models
Feb 08, 2023Prompting interfaces allow users to quickly adjust the output of generative models in both vision and language. However, small changes and design choices in the prompt can lead to significant differences in the output. In this work, we develop a black-box framework for generating adversarial prompts for unstructured image and text generation. These prompts, which can be standalone or prepended to benign prompts, induce specific behaviors into the generative process, such as generating images of a particular object or biasing the frequency of specific letters in the generated text.
Neural Likelihoods for Multi-Output Gaussian Processes
May 31, 2019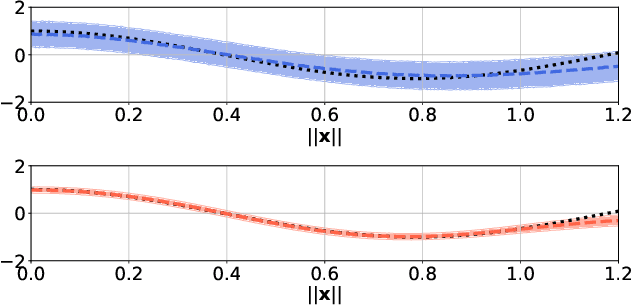
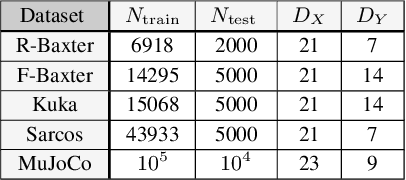
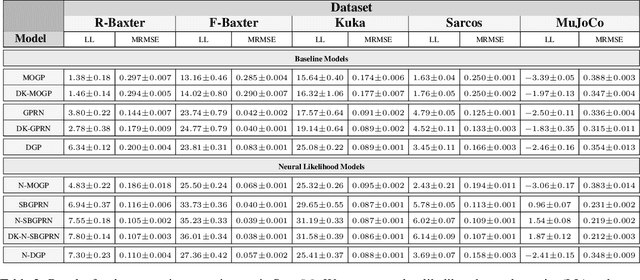
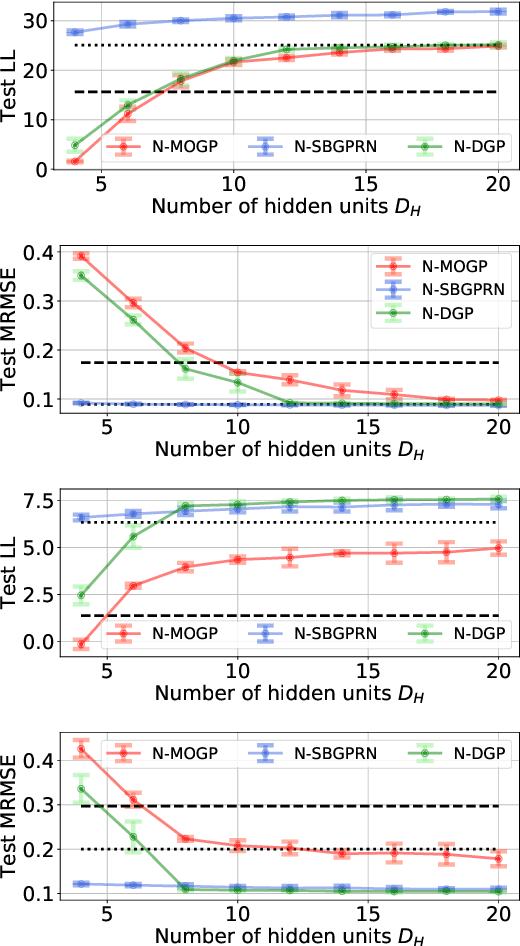
We construct flexible likelihoods for multi-output Gaussian process models that leverage neural networks as components. We make use of sparse variational inference methods to enable scalable approximate inference for the resulting class of models. An attractive feature of these models is that they can admit analytic predictive means even when the likelihood is non-linear and the predictive distributions are non-Gaussian. We validate the modeling potential of these models in a variety of experiments in both the supervised and unsupervised setting. We demonstrate that the flexibility of these `neural' likelihoods can improve prediction quality as compared to simpler Gaussian process models and that neural likelihoods can be readily combined with a variety of underlying Gaussian process models, including deep Gaussian processes.
Deep Feature Interpolation for Image Content Changes
Jun 19, 2017
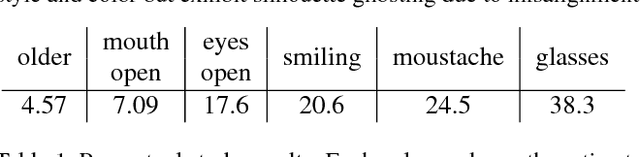

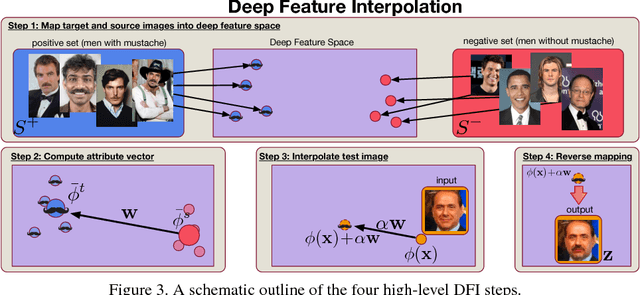
We propose Deep Feature Interpolation (DFI), a new data-driven baseline for automatic high-resolution image transformation. As the name suggests, it relies only on simple linear interpolation of deep convolutional features from pre-trained convnets. We show that despite its simplicity, DFI can perform high-level semantic transformations like "make older/younger", "make bespectacled", "add smile", among others, surprisingly well - sometimes even matching or outperforming the state-of-the-art. This is particularly unexpected as DFI requires no specialized network architecture or even any deep network to be trained for these tasks. DFI therefore can be used as a new baseline to evaluate more complex algorithms and provides a practical answer to the question of which image transformation tasks are still challenging in the rise of deep learning.