 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience-Guided Adaptation of Inference-Time Reasoning Strategies
Nov 14, 2025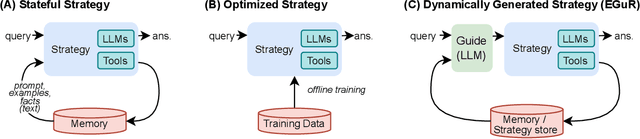
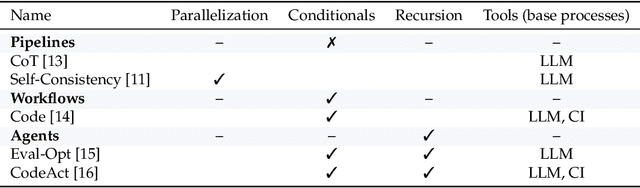

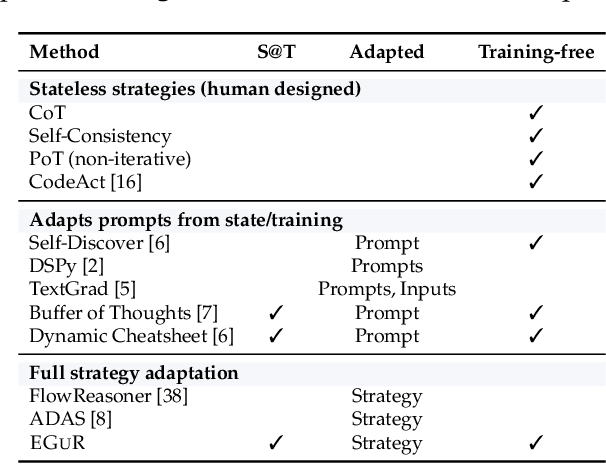
Enabling agentic AI systems to adapt their problem-solving approaches based on post-training interactions remains a fundamental challenge. While systems that update and maintain a memory at inference time have been proposed, existing designs only steer the system by modifying textual input to a language model or agent, which means that they cannot change sampling parameters, remove tools, modify system prompts, or switch between agentic and workflow paradigms. On the other hand, systems that adapt more flexibly require offline optimization and remain static once deployed. We present Experience-Guided Reasoner (EGuR), which generates tailored strategies -- complete computational procedures involving LLM calls, tools, sampling parameters, and control logic -- dynamically at inference time based on accumulated experience. We achieve this using an LLM-based meta-strategy -- a strategy that outputs strategies -- enabling adaptation of all strategy components (prompts, sampling parameters, tool configurations, and control logic). EGuR operates through two components: a Guide generates multiple candidate strategies conditioned on the current problem and structured memory of past experiences, while a Consolidator integrates execution feedback to improve future strategy generation. This produces complete, ready-to-run strategies optimized for each problem, which can be cached, retrieved, and executed as needed without wasting resources. Across five challenging benchmarks (AIME 2025, 3-SAT, and three Big Bench Extra Hard tasks), EGuR achieves up to 14% accuracy improvements over the strongest baselines while reducing computational costs by up to 111x, with both metrics improving as the system gains experience.
Once Upon an Input: Reasoning via Per-Instance Program Synthesis
Oct 26, 2025Large language models (LLMs) excel at zero-shot inference but continue to struggle with complex, multi-step reasoning. Recent methods that augment LLMs with intermediate reasoning steps such as Chain of Thought (CoT) and Program of Thought (PoT) improve performance but often produce undesirable solutions, especially in algorithmic domains. We introduce Per-Instance Program Synthesis (PIPS), a method that generates and refines programs at the instance-level using structural feedback without relying on task-specific guidance or explicit test cases. To further improve performance, PIPS incorporates a confidence metric that dynamically chooses between direct inference and program synthesis on a per-instance basis. Experiments across three frontier LLMs and 30 benchmarks including all tasks of Big Bench Extra Hard (BBEH), visual question answering tasks, relational reasoning tasks, and mathematical reasoning tasks show that PIPS improves the absolute harmonic mean accuracy by up to 8.6% and 9.4% compared to PoT and CoT respectively, and reduces undesirable program generations by 65.1% on the algorithmic tasks compared to PoT with Gemini-2.0-Flash.
Instruction Following by Boosting Attention of Large Language Models
Jun 16, 2025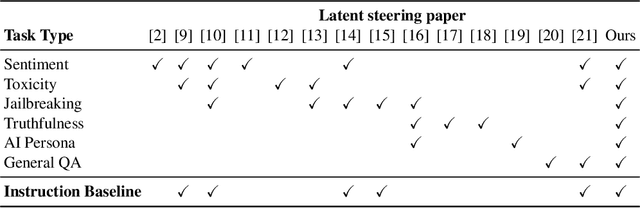
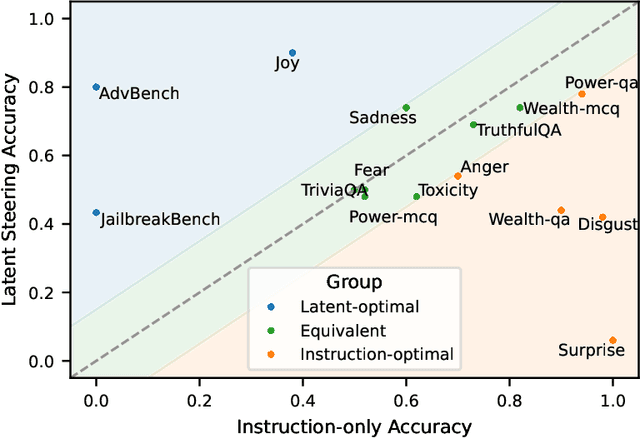
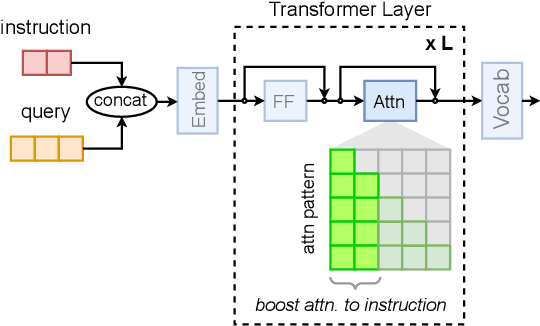

Controlling the generation of large language models (LLMs) remains a central challenge to ensure their safe and reliable deployment. While prompt engineering and finetuning are common approaches, recent work has explored latent steering, a lightweight technique that alters LLM internal activations to guide generation. However, subsequent studies revealed latent steering's effectiveness to be limited, often underperforming simple instruction prompting. To address this limitation, we first establish a benchmark across diverse behaviors for standardized evaluation of steering techniques. Building on insights from this benchmark, we introduce Instruction Attention Boosting (InstABoost), a latent steering method that boosts the strength of instruction prompting by altering the model's attention during generation. InstABoost combines the strengths of existing approaches and is theoretically supported by prior work that suggests that in-context rule following in transformer-based models can be controlled by manipulating attention on instructions. Empirically, InstABoost demonstrates superior control success compared to both traditional prompting and latent steering.
The Road to Generalizable Neuro-Symbolic Learning Should be Paved with Foundation Models
May 30, 2025Neuro-symbolic learning was proposed to address challenges with training neural networks for complex reasoning tasks with the added benefits of interpretability, reliability, and efficiency. Neuro-symbolic learning methods traditionally train neural models in conjunction with symbolic programs, but they face significant challenges that limit them to simplistic problems. On the other hand, purely-neural foundation models now reach state-of-the-art performance through prompting rather than training, but they are often unreliable and lack interpretability. Supplementing foundation models with symbolic programs, which we call neuro-symbolic prompting, provides a way to use these models for complex reasoning tasks. Doing so raises the question: What role does specialized model training as part of neuro-symbolic learning have in the age of foundation models? To explore this question, we highlight three pitfalls of traditional neuro-symbolic learning with respect to the compute, data, and programs leading to generalization problems. This position paper argues that foundation models enable generalizable neuro-symbolic solutions, offering a path towards achieving the original goals of neuro-symbolic learning without the downsides of training from scratch.
Where's the Bug? Attention Probing for Scalable Fault Localization
Feb 20, 2025Ensuring code correctness remains a challenging problem even as large language models (LLMs) become increasingly capable at code-related tasks. While LLM-based program repair systems can propose bug fixes using only a user's bug report, their effectiveness is fundamentally limited by their ability to perform fault localization (FL), a challenging problem for both humans and LLMs. Existing FL approaches rely on executable test cases, require training on costly and often noisy line-level annotations, or demand resource-intensive LLMs. In this paper, we present Bug Attention Probe (BAP), a method which learns state-of-the-art fault localization without any direct localization labels, outperforming traditional FL baselines and prompting of large-scale LLMs. We evaluate our approach across a variety of code settings, including real-world Java bugs from the standard Defects4J dataset as well as seven other datasets which span a diverse set of bug types and languages. Averaged across all eight datasets, BAP improves by 34.6% top-1 accuracy compared to the strongest baseline and 93.4% over zero-shot prompting GPT-4o. BAP is also significantly more efficient than prompting, outperforming large open-weight models at a small fraction of the computational cost.
Towards Compositionality in Concept Learning
Jun 26, 2024



Concept-based interpretability methods offer a lens into the internals of foundation models by decomposing their embeddings into high-level concepts. These concept representations are most useful when they are compositional, meaning that the individual concepts compose to explain the full sample. We show that existing unsupervised concept extraction methods find concepts which are not compositional. To automatically discover compositional concept representations, we identify two salient properties of such representations, and propose Compositional Concept Extraction (CCE) for finding concepts which obey these properties. We evaluate CCE on five different datasets over image and text data. Our evaluation shows that CCE finds more compositional concept representations than baselines and yields better accuracy on four downstream classification tasks. Code and data are available at https://github.com/adaminsky/compositional_concepts .
MDB: Interactively Querying Datasets and Models
Aug 13, 2023As models are trained and deployed, developers need to be able to systematically debug errors that emerge in the machine learning pipeline. We present MDB, a debugging framework for interactively querying datasets and models. MDB integrates functional programming with relational algebra to build expressive queries over a database of datasets and model predictions. Queries are reusable and easily modified, enabling debuggers to rapidly iterate and refine queries to discover and characterize errors and model behaviors. We evaluate MDB on object detection, bias discovery, image classification, and data imputation tasks across self-driving videos, large language models, and medical records. Our experiments show that MDB enables up to 10x faster and 40\% shorter queries than other baselines. In a user study, we find developers can successfully construct complex queries that describe errors of machine learning models.
TopEx: Topic-based Explanations for Model Comparison
Jun 02, 2023


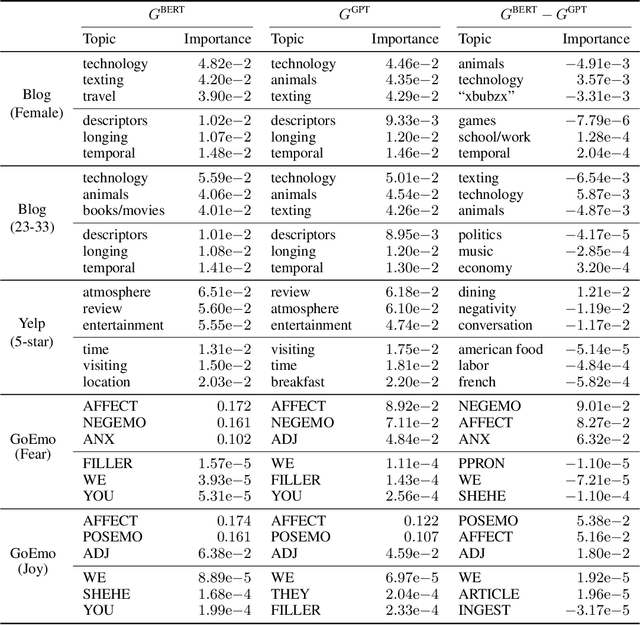
Meaningfully comparing language models is challenging with current explanation methods. Current explanations are overwhelming for humans due to large vocabularies or incomparable across models. We present TopEx, an explanation method that enables a level playing field for comparing language models via model-agnostic topics. We demonstrate how TopEx can identify similarities and differences between DistilRoBERTa and GPT-2 on a variety of NLP tasks.
Rectifying Group Irregularities in Explanations for Distribution Shift
May 25, 2023It is well-known that real-world changes constituting distribution shift adversely affect model performance. How to characterize those changes in an interpretable manner is poorly understood. Existing techniques to address this problem take the form of shift explanations that elucidate how to map samples from the original distribution toward the shifted one by reducing the disparity between these two distributions. However, these methods can introduce group irregularities, leading to explanations that are less feasible and robust. To address these issues, we propose Group-aware Shift Explanations (GSE), a method that produces interpretable explanations by leveraging worst-group optimization to rectify group irregularities. We demonstrate how GSE not only maintains group structures, such as demographic and hierarchical subpopulations, but also enhances feasibility and robustness in the resulting explanations in a wide range of tabular, language, and image settings.
Learning to Select Pivotal Samples for Meta Re-weighting
Feb 09, 2023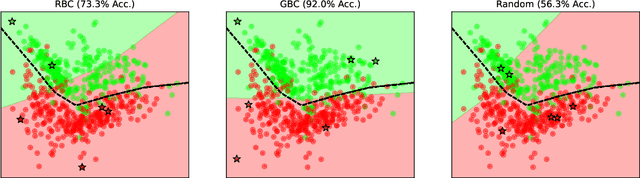
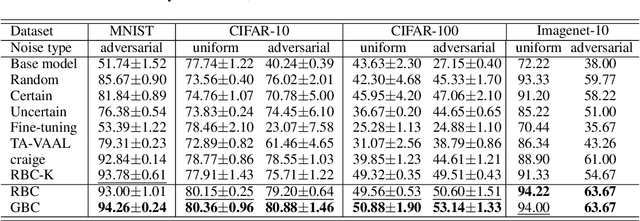
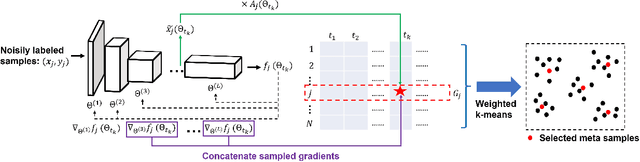
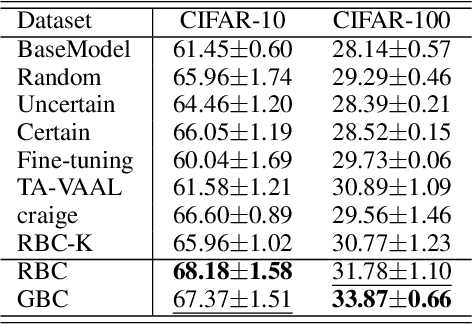
Sample re-weighting strategies provide a promising mechanism to deal with imperfect training data in machine learning, such as noisily labeled or class-imbalanced data. One such strategy involves formulating a bi-level optimization problem called the meta re-weighting problem, whose goal is to optimize performance on a small set of perfect pivotal samples, called meta samples. Many approaches have been proposed to efficiently solve this problem. However, all of them assume that a perfect meta sample set is already provided while we observe that the selections of meta sample set is performance critical. In this paper, we study how to learn to identify such a meta sample set from a large, imperfect training set, that is subsequently cleaned and used to optimize performance in the meta re-weighting setting. We propose a learning framework which reduces the meta samples selection problem to a weighted K-means clustering problem through rigorously theoretical analysis. We propose two clustering methods within our learning framework, Representation-based clustering method (RBC) and Gradient-based clustering method (GBC), for balancing performance and computational efficiency. Empirical studies demonstrate the performance advantage of our methods over various baseline methods.