 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Select Pivotal Samples for Meta Re-weighting
Paper and Code
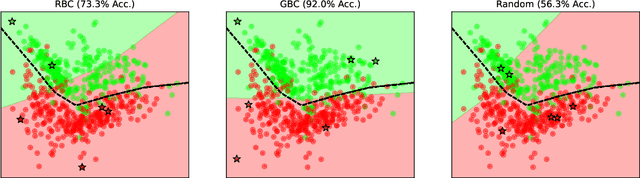
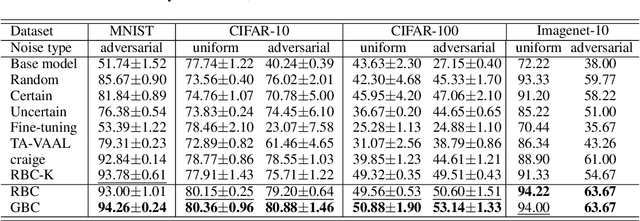
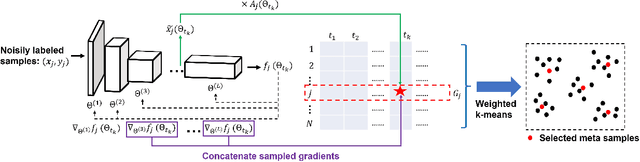
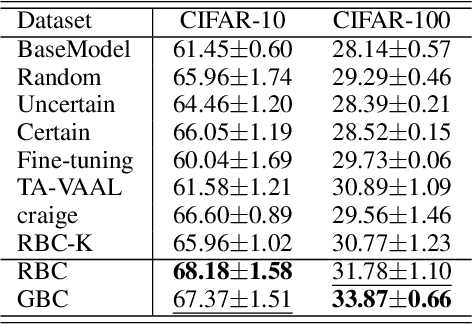
Sample re-weighting strategies provide a promising mechanism to deal with imperfect training data in machine learning, such as noisily labeled or class-imbalanced data. One such strategy involves formulating a bi-level optimization problem called the meta re-weighting problem, whose goal is to optimize performance on a small set of perfect pivotal samples, called meta samples. Many approaches have been proposed to efficiently solve this problem. However, all of them assume that a perfect meta sample set is already provided while we observe that the selections of meta sample set is performance critical. In this paper, we study how to learn to identify such a meta sample set from a large, imperfect training set, that is subsequently cleaned and used to optimize performance in the meta re-weighting setting. We propose a learning framework which reduces the meta samples selection problem to a weighted K-means clustering problem through rigorously theoretical analysis. We propose two clustering methods within our learning framework, Representation-based clustering method (RBC) and Gradient-based clustering method (GBC), for balancing performance and computational efficiency. Empirical studies demonstrate the performance advantage of our methods over various baseline methods.