 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnce Upon an Input: Reasoning via Per-Instance Program Synthesis
Oct 26, 2025Large language models (LLMs) excel at zero-shot inference but continue to struggle with complex, multi-step reasoning. Recent methods that augment LLMs with intermediate reasoning steps such as Chain of Thought (CoT) and Program of Thought (PoT) improve performance but often produce undesirable solutions, especially in algorithmic domains. We introduce Per-Instance Program Synthesis (PIPS), a method that generates and refines programs at the instance-level using structural feedback without relying on task-specific guidance or explicit test cases. To further improve performance, PIPS incorporates a confidence metric that dynamically chooses between direct inference and program synthesis on a per-instance basis. Experiments across three frontier LLMs and 30 benchmarks including all tasks of Big Bench Extra Hard (BBEH), visual question answering tasks, relational reasoning tasks, and mathematical reasoning tasks show that PIPS improves the absolute harmonic mean accuracy by up to 8.6% and 9.4% compared to PoT and CoT respectively, and reduces undesirable program generations by 65.1% on the algorithmic tasks compared to PoT with Gemini-2.0-Flash.
The Road to Generalizable Neuro-Symbolic Learning Should be Paved with Foundation Models
May 30, 2025Neuro-symbolic learning was proposed to address challenges with training neural networks for complex reasoning tasks with the added benefits of interpretability, reliability, and efficiency. Neuro-symbolic learning methods traditionally train neural models in conjunction with symbolic programs, but they face significant challenges that limit them to simplistic problems. On the other hand, purely-neural foundation models now reach state-of-the-art performance through prompting rather than training, but they are often unreliable and lack interpretability. Supplementing foundation models with symbolic programs, which we call neuro-symbolic prompting, provides a way to use these models for complex reasoning tasks. Doing so raises the question: What role does specialized model training as part of neuro-symbolic learning have in the age of foundation models? To explore this question, we highlight three pitfalls of traditional neuro-symbolic learning with respect to the compute, data, and programs leading to generalization problems. This position paper argues that foundation models enable generalizable neuro-symbolic solutions, offering a path towards achieving the original goals of neuro-symbolic learning without the downsides of training from scratch.
Relational Programming with Foundation Models
Dec 19, 2024Foundation models have vast potential to enable diverse AI applications. The powerful yet incomplete nature of these models has spurred a wide range of mechanisms to augment them with capabilities such as in-context learning, information retrieval, and code interpreting. We propose Vieira, a declarative framework that unifies these mechanisms in a general solution for programming with foundation models. Vieira follows a probabilistic relational paradigm and treats foundation models as stateless functions with relational inputs and outputs. It supports neuro-symbolic applications by enabling the seamless combination of such models with logic programs, as well as complex, multi-modal applications by streamlining the composition of diverse sub-models. We implement Vieira by extending the Scallop compiler with a foreign interface that supports foundation models as plugins. We implement plugins for 12 foundation models including GPT, CLIP, and SAM. We evaluate Vieira on 9 challenging tasks that span language, vision, and structured and vector databases. Our evaluation shows that programs in Vieira are concise, can incorporate modern foundation models, and have comparable or better accuracy than competitive baselines.
Data-Efficient Learning with Neural Programs
Jun 10, 2024



Many computational tasks can be naturally expressed as a composition of a DNN followed by a program written in a traditional programming language or an API call to an LLM. We call such composites "neural programs" and focus on the problem of learning the DNN parameters when the training data consist of end-to-end input-output labels for the composite. When the program is written in a differentiable logic programming language, techniques from neurosymbolic learning are applicable, but in general, the learning for neural programs requires estimating the gradients of black-box components. We present an algorithm for learning neural programs, called ISED, that only relies on input-output samples of black-box components. For evaluation, we introduce new benchmarks that involve calls to modern LLMs such as GPT-4 and also consider benchmarks from the neurosymolic learning literature. Our evaluation shows that for the latter benchmarks, ISED has comparable performance to state-of-the-art neurosymbolic frameworks. For the former, we use adaptations of prior work on gradient approximations of black-box components as a baseline, and show that ISED achieves comparable accuracy but in a more data- and sample-efficient manner.
DISCRET: Synthesizing Faithful Explanations For Treatment Effect Estimation
Jun 02, 2024


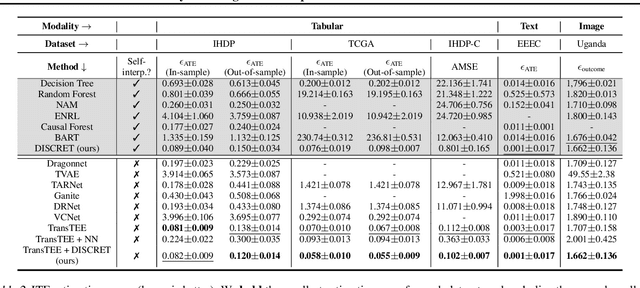
Designing faithful yet accurate AI models is challenging, particularly in the field of individual treatment effect estimation (ITE). ITE prediction models deployed in critical settings such as healthcare should ideally be (i) accurate, and (ii) provide faithful explanations. However, current solutions are inadequate: state-of-the-art black-box models do not supply explanations, post-hoc explainers for black-box models lack faithfulness guarantees, and self-interpretable models greatly compromise accuracy. To address these issues, we propose DISCRET, a self-interpretable ITE framework that synthesizes faithful, rule-based explanations for each sample. A key insight behind DISCRET is that explanations can serve dually as database queries to identify similar subgroups of samples. We provide a novel RL algorithm to efficiently synthesize these explanations from a large search space. We evaluate DISCRET on diverse tasks involving tabular, image, and text data. DISCRET outperforms the best self-interpretable models and has accuracy comparable to the best black-box models while providing faithful explanations. DISCRET is available at https://github.com/wuyinjun-1993/DISCRET-ICML2024.