 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACR: A Benchmark for Automatic Cohort Retrieval
Jun 20, 2024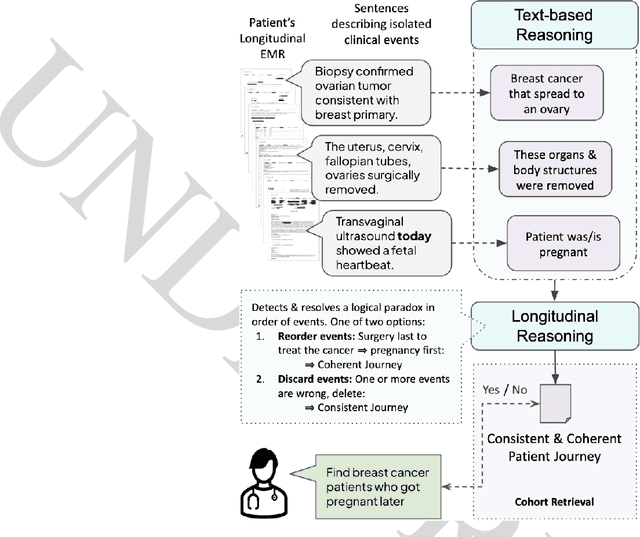
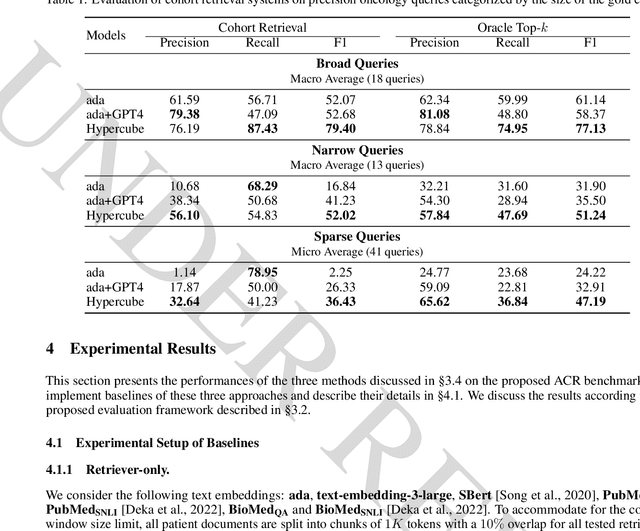
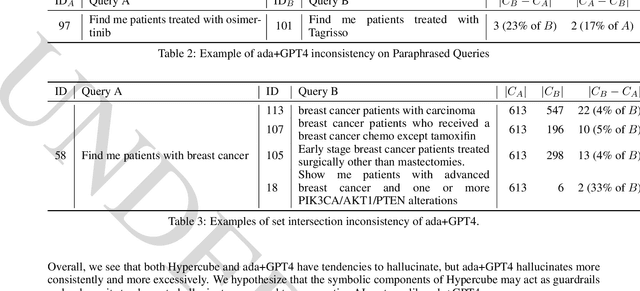
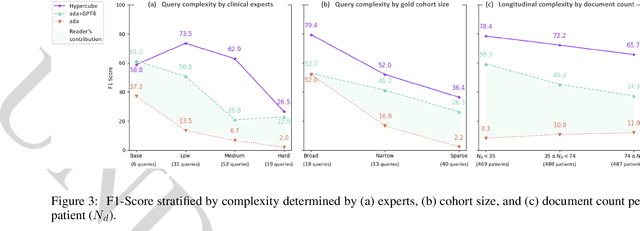
Identifying patient cohorts is fundamental to numerous healthcare tasks, including clinical trial recruitment and retrospective studies. Current cohort retrieval methods in healthcare organizations rely on automated queries of structured data combined with manual curation, which are time-consuming, labor-intensive, and often yield low-quality results. Recent advancements in large language models (LLMs) and information retrieval (IR) offer promising avenues to revolutionize these systems. Major challenges include managing extensive eligibility criteria and handling the longitudinal nature of unstructured Electronic Medical Records (EMRs) while ensuring that the solution remains cost-effective for real-world application. This paper introduces a new task, Automatic Cohort Retrieval (ACR), and evaluates the performance of LLMs and commercial, domain-specific neuro-symbolic approaches. We provide a benchmark task, a query dataset, an EMR dataset, and an evaluation framework. Our findings underscore the necessity for efficient, high-quality ACR systems capable of longitudinal reasoning across extensive patient databases.
DISCRET: Synthesizing Faithful Explanations For Treatment Effect Estimation
Jun 02, 2024


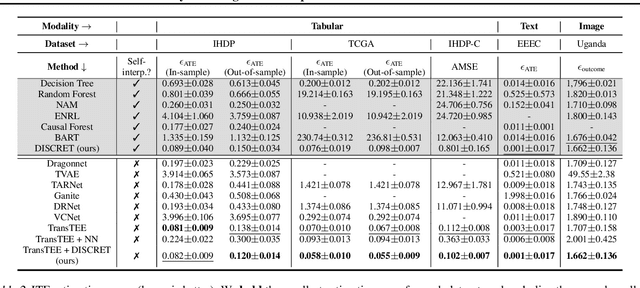
Designing faithful yet accurate AI models is challenging, particularly in the field of individual treatment effect estimation (ITE). ITE prediction models deployed in critical settings such as healthcare should ideally be (i) accurate, and (ii) provide faithful explanations. However, current solutions are inadequate: state-of-the-art black-box models do not supply explanations, post-hoc explainers for black-box models lack faithfulness guarantees, and self-interpretable models greatly compromise accuracy. To address these issues, we propose DISCRET, a self-interpretable ITE framework that synthesizes faithful, rule-based explanations for each sample. A key insight behind DISCRET is that explanations can serve dually as database queries to identify similar subgroups of samples. We provide a novel RL algorithm to efficiently synthesize these explanations from a large search space. We evaluate DISCRET on diverse tasks involving tabular, image, and text data. DISCRET outperforms the best self-interpretable models and has accuracy comparable to the best black-box models while providing faithful explanations. DISCRET is available at https://github.com/wuyinjun-1993/DISCRET-ICML2024.