 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACR: A Benchmark for Automatic Cohort Retrieval
Jun 20, 2024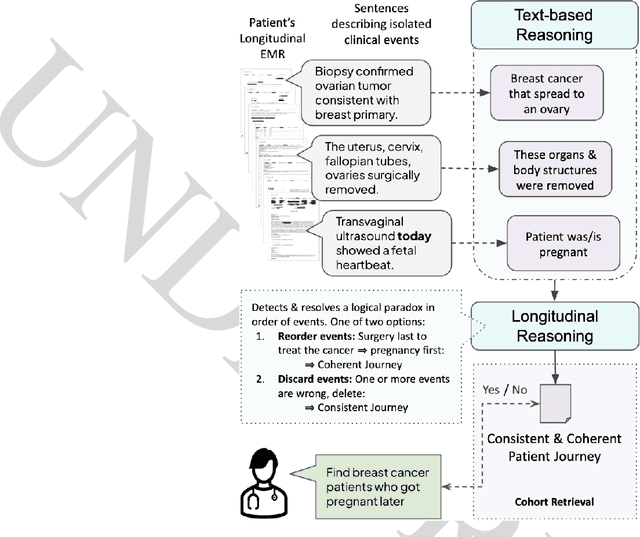
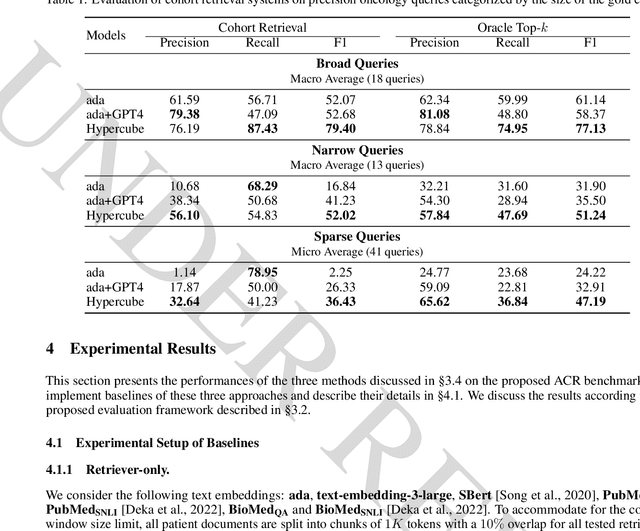
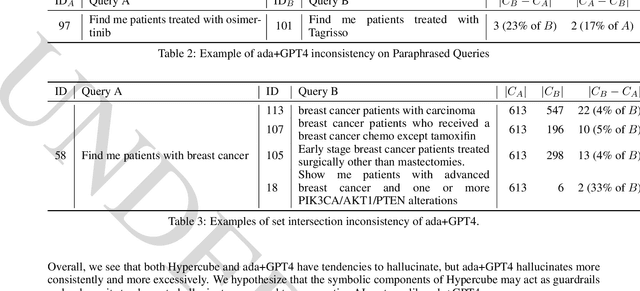
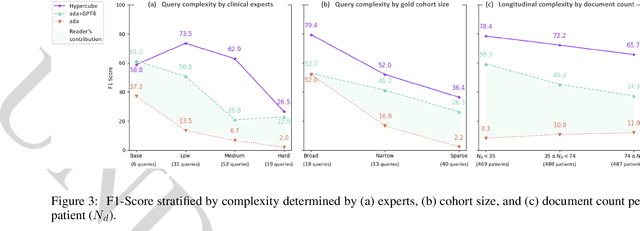
Identifying patient cohorts is fundamental to numerous healthcare tasks, including clinical trial recruitment and retrospective studies. Current cohort retrieval methods in healthcare organizations rely on automated queries of structured data combined with manual curation, which are time-consuming, labor-intensive, and often yield low-quality results. Recent advancements in large language models (LLMs) and information retrieval (IR) offer promising avenues to revolutionize these systems. Major challenges include managing extensive eligibility criteria and handling the longitudinal nature of unstructured Electronic Medical Records (EMRs) while ensuring that the solution remains cost-effective for real-world application. This paper introduces a new task, Automatic Cohort Retrieval (ACR), and evaluates the performance of LLMs and commercial, domain-specific neuro-symbolic approaches. We provide a benchmark task, a query dataset, an EMR dataset, and an evaluation framework. Our findings underscore the necessity for efficient, high-quality ACR systems capable of longitudinal reasoning across extensive patient databases.
Coupling Symbolic Reasoning with Language Modeling for Efficient Longitudinal Understanding of Unstructured Electronic Medical Records
Aug 07, 2023
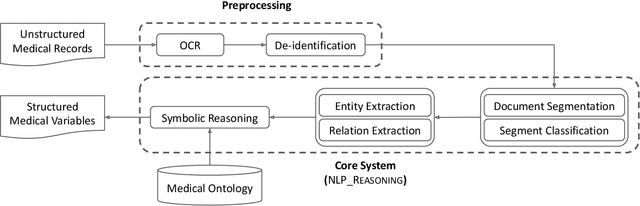
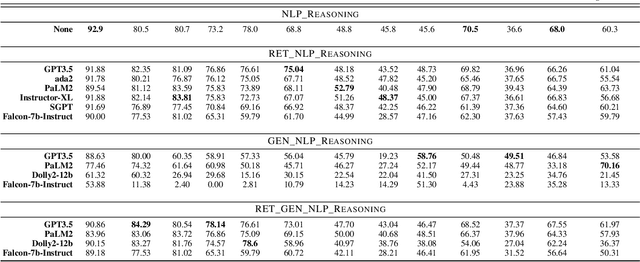
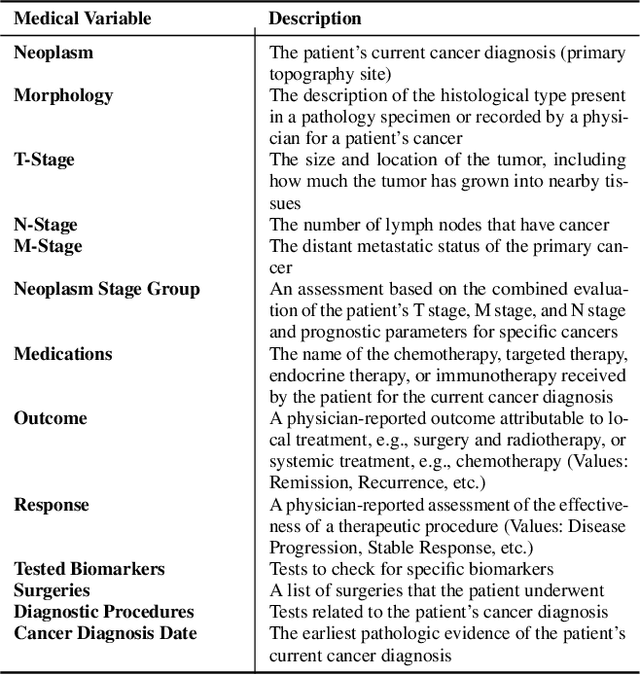
The application of Artificial Intelligence (AI) in healthcare has been revolutionary, especially with the recent advancements in transformer-based Large Language Models (LLMs). However, the task of understanding unstructured electronic medical records remains a challenge given the nature of the records (e.g., disorganization, inconsistency, and redundancy) and the inability of LLMs to derive reasoning paradigms that allow for comprehensive understanding of medical variables. In this work, we examine the power of coupling symbolic reasoning with language modeling toward improved understanding of unstructured clinical texts. We show that such a combination improves the extraction of several medical variables from unstructured records. In addition, we show that the state-of-the-art commercially-free LLMs enjoy retrieval capabilities comparable to those provided by their commercial counterparts. Finally, we elaborate on the need for LLM steering through the application of symbolic reasoning as the exclusive use of LLMs results in the lowest performance.
Towards Fast Adaptation of Pretrained Contrastive Models for Multi-channel Video-Language Retrieval
Jun 05, 2022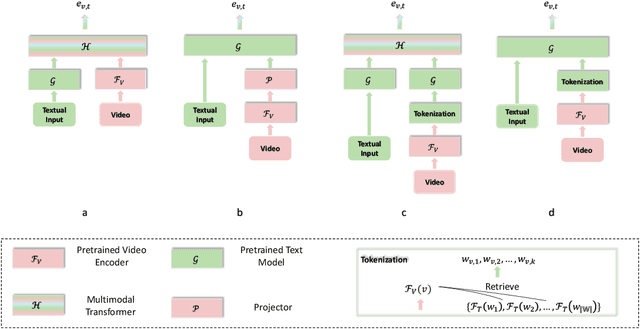

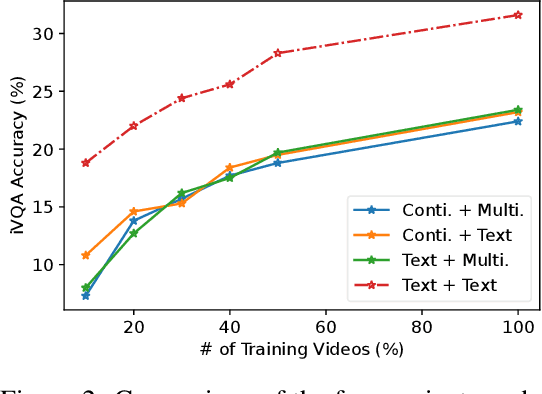
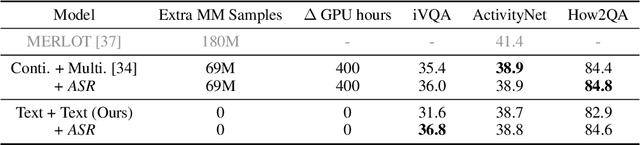
Multi-channel video-language retrieval require models to understand information from different modalities (e.g. video+question, video+speech) and real-world knowledge to correctly link a video with a textual response or query. Fortunately, multimodal contrastive models have been shown to be highly effective at aligning entities in images/videos and text, e.g., CLIP; text contrastive models have been extensively studied recently for their strong ability of producing discriminative sentence embeddings, e.g., SimCSE. Their abilities are exactly needed by multi-channel video-language retrieval. However, it is not clear how to quickly adapt these two lines of models to multi-channel video-language retrieval-style tasks. In this paper, we identify a principled model design space with two axes: how to represent videos and how to fuse video and text information. Based on categorization of recent methods, we investigate the options of representing videos using continuous feature vectors or discrete text tokens; for the fusion method, we explore a multimodal transformer or a pretrained contrastive text model. We extensively evaluate the four combinations on five video-language datasets. We surprisingly find that discrete text tokens coupled with a pretrained contrastive text model yields the best performance. This combination can even outperform state-of-the-art on the iVQA dataset without the additional training on millions of video-language data. Further analysis shows that this is because representing videos as text tokens captures the key visual information with text tokens that are naturally aligned with text models and the text models obtained rich knowledge during contrastive pretraining process. All the empirical analysis we obtain for the four variants establishes a solid foundation for future research on leveraging the rich knowledge of pretrained contrastive models.