 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Detection-Guided Preference Optimization for Clinical Summarization
May 27, 2026Large language models (LLMs) have shown promise on summarization tasks, but they often produce hallucinations, which are unsupported or incorrect statements that limit their reliability in specialized healthcare applications. We introduce \itermodelfull (\itermodel), an inference-time method that leverages hallucination detectors to guide iterative summary revisions toward factual corrections. Building on this, we propose \itermodel for Preference Learning (\model), which converts detector-guided refinement trajectories into preference pairs for model finetuning. Extensive experiments show that our methods substantially reduce hallucinations for Llama and Gemma models in summarizing real-world clinical notes from \MimicIV. For example, \itermodel reduces 24\% and \model reduces 48\% hallucinations in Llama-3.1-8B-Instruct. Importantly, both methods preserve summary fluency, coherence, and relevance according to human expert and LLM-Jury evaluations. Together, these results demonstrate that detection-informed refinement and preference learning offer an automated solution for improving factual faithfulness in clinical summarization.
ACR: A Benchmark for Automatic Cohort Retrieval
Jun 20, 2024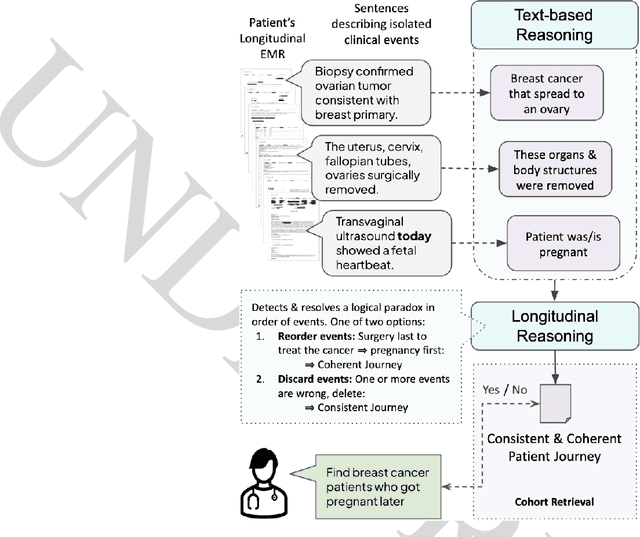
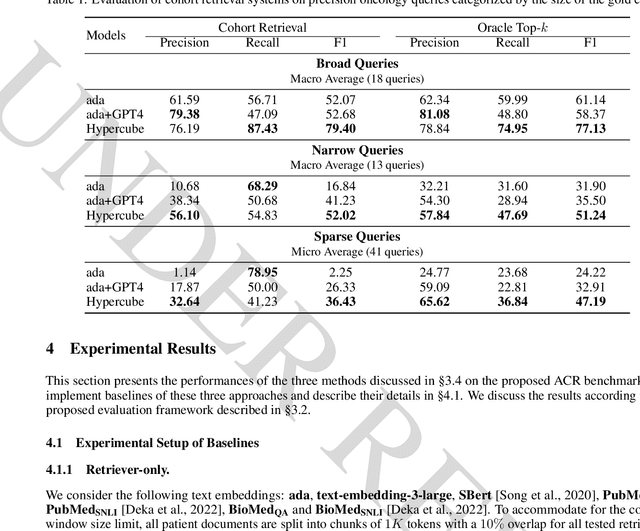
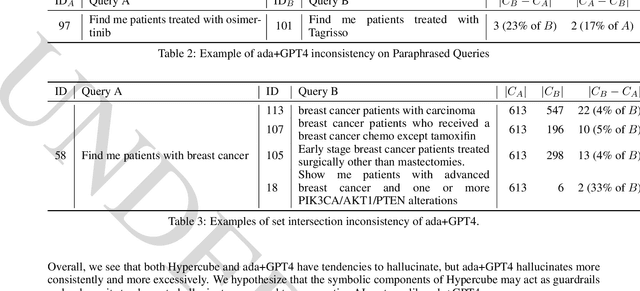
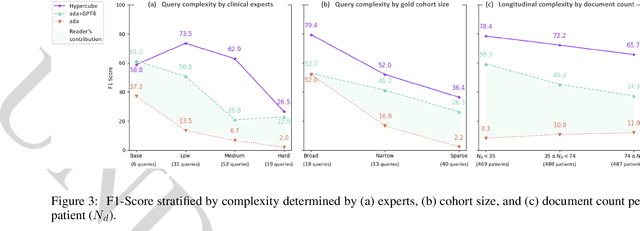
Identifying patient cohorts is fundamental to numerous healthcare tasks, including clinical trial recruitment and retrospective studies. Current cohort retrieval methods in healthcare organizations rely on automated queries of structured data combined with manual curation, which are time-consuming, labor-intensive, and often yield low-quality results. Recent advancements in large language models (LLMs) and information retrieval (IR) offer promising avenues to revolutionize these systems. Major challenges include managing extensive eligibility criteria and handling the longitudinal nature of unstructured Electronic Medical Records (EMRs) while ensuring that the solution remains cost-effective for real-world application. This paper introduces a new task, Automatic Cohort Retrieval (ACR), and evaluates the performance of LLMs and commercial, domain-specific neuro-symbolic approaches. We provide a benchmark task, a query dataset, an EMR dataset, and an evaluation framework. Our findings underscore the necessity for efficient, high-quality ACR systems capable of longitudinal reasoning across extensive patient databases.
Coupling Symbolic Reasoning with Language Modeling for Efficient Longitudinal Understanding of Unstructured Electronic Medical Records
Aug 07, 2023
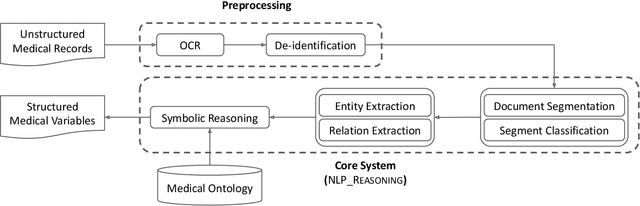
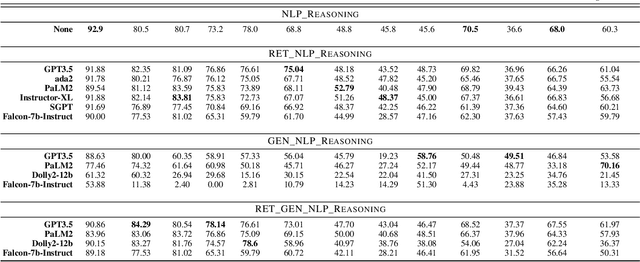
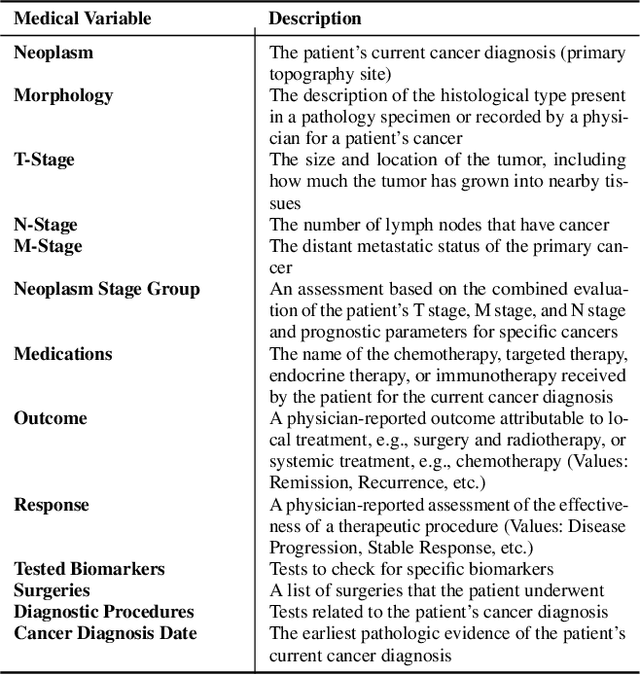
The application of Artificial Intelligence (AI) in healthcare has been revolutionary, especially with the recent advancements in transformer-based Large Language Models (LLMs). However, the task of understanding unstructured electronic medical records remains a challenge given the nature of the records (e.g., disorganization, inconsistency, and redundancy) and the inability of LLMs to derive reasoning paradigms that allow for comprehensive understanding of medical variables. In this work, we examine the power of coupling symbolic reasoning with language modeling toward improved understanding of unstructured clinical texts. We show that such a combination improves the extraction of several medical variables from unstructured records. In addition, we show that the state-of-the-art commercially-free LLMs enjoy retrieval capabilities comparable to those provided by their commercial counterparts. Finally, we elaborate on the need for LLM steering through the application of symbolic reasoning as the exclusive use of LLMs results in the lowest performance.
Egyptian Arabic to English Statistical Machine Translation System for NIST OpenMT'2015
Jun 18, 2016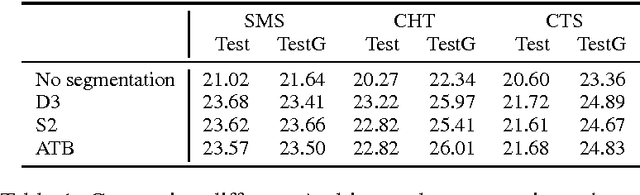



The paper describes the Egyptian Arabic-to-English statistical machine translation (SMT) system that the QCRI-Columbia-NYUAD (QCN) group submitted to the NIST OpenMT'2015 competition. The competition focused on informal dialectal Arabic, as used in SMS, chat, and speech. Thus, our efforts focused on processing and standardizing Arabic, e.g., using tools such as 3arrib and MADAMIRA. We further trained a phrase-based SMT system using state-of-the-art features and components such as operation sequence model, class-based language model, sparse features, neural network joint model, genre-based hierarchically-interpolated language model, unsupervised transliteration mining, phrase-table merging, and hypothesis combination. Our system ranked second on all three genres.