 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Once Correct, Still Wrong: Counterfactual Hallucination in Multilingual Vision-Language Models
Feb 05, 2026Vision-language models (VLMs) can achieve high accuracy while still accepting culturally plausible but visually incorrect interpretations. Existing hallucination benchmarks rarely test this failure mode, particularly outside Western contexts and English. We introduce M2CQA, a culturally grounded multimodal benchmark built from images spanning 17 MENA countries, paired with contrastive true and counterfactual statements in English, Arabic, and its dialects. To isolate hallucination beyond raw accuracy, we propose the CounterFactual Hallucination Rate (CFHR), which measures counterfactual acceptance conditioned on correctly answering the true statement. Evaluating state-of-the-art VLMs under multiple prompting strategies, we find that CFHR rises sharply in Arabic, especially in dialects, even when true-statement accuracy remains high. Moreover, reasoning-first prompting consistently increases counterfactual hallucination, while answering before justifying improves robustness. We will make the experimental resources and dataset publicly available for the community.
Do I Really Know? Learning Factual Self-Verification for Hallucination Reduction
Feb 02, 2026Factual hallucination remains a central challenge for large language models (LLMs). Existing mitigation approaches primarily rely on either external post-hoc verification or mapping uncertainty directly to abstention during fine-tuning, often resulting in overly conservative behavior. We propose VeriFY, a training-time framework that teaches LLMs to reason about factual uncertainty through consistency-based self-verification. VeriFY augments training with structured verification traces that guide the model to produce an initial answer, generate and answer a probing verification query, issue a consistency judgment, and then decide whether to answer or abstain. To address the risk of reinforcing hallucinated content when training on augmented traces, we introduce a stage-level loss masking approach that excludes hallucinated answer stages from the training objective while preserving supervision over verification behavior. Across multiple model families and scales, VeriFY reduces factual hallucination rates by 9.7 to 53.3 percent, with only modest reductions in recall (0.4 to 5.7 percent), and generalizes across datasets when trained on a single source. The source code, training data, and trained model checkpoints will be released upon acceptance.
There Is More to Refusal in Large Language Models than a Single Direction
Feb 02, 2026Prior work argues that refusal in large language models is mediated by a single activation-space direction, enabling effective steering and ablation. We show that this account is incomplete. Across eleven categories of refusal and non-compliance, including safety, incomplete or unsupported requests, anthropomorphization, and over-refusal, we find that these refusal behaviors correspond to geometrically distinct directions in activation space. Yet despite this diversity, linear steering along any refusal-related direction produces nearly identical refusal to over-refusal trade-offs, acting as a shared one-dimensional control knob. The primary effect of different directions is not whether the model refuses, but how it refuses.
Editing Across Languages: A Survey of Multilingual Knowledge Editing
May 20, 2025While Knowledge Editing has been extensively studied in monolingual settings, it remains underexplored in multilingual contexts. This survey systematizes recent research on Multilingual Knowledge Editing (MKE), a growing subdomain of model editing focused on ensuring factual edits generalize reliably across languages. We present a comprehensive taxonomy of MKE methods, covering parameter-based, memory-based, fine-tuning, and hypernetwork approaches. We survey available benchmarks,summarize key findings on method effectiveness and transfer patterns, identify challenges in cross-lingual propagation, and highlight open problems related to language anisotropy, evaluation coverage, and edit scalability. Our analysis consolidates a rapidly evolving area and lays the groundwork for future progress in editable language-aware LLMs.
AraDiCE: Benchmarks for Dialectal and Cultural Capabilities in LLMs
Sep 17, 2024Arabic, with its rich diversity of dialects, remains significantly underrepresented in Large Language Models, particularly in dialectal variations. We address this gap by introducing seven synthetic datasets in dialects alongside Modern Standard Arabic (MSA), created using Machine Translation (MT) combined with human post-editing. We present AraDiCE, a benchmark for Arabic Dialect and Cultural Evaluation. We evaluate LLMs on dialect comprehension and generation, focusing specifically on low-resource Arabic dialects. Additionally, we introduce the first-ever fine-grained benchmark designed to evaluate cultural awareness across the Gulf, Egypt, and Levant regions, providing a novel dimension to LLM evaluation. Our findings demonstrate that while Arabic-specific models like Jais and AceGPT outperform multilingual models on dialectal tasks, significant challenges persist in dialect identification, generation, and translation. This work contributes ~45K post-edited samples, a cultural benchmark, and highlights the importance of tailored training to improve LLM performance in capturing the nuances of diverse Arabic dialects and cultural contexts. We will release the dialectal translation models and benchmarks curated in this study.
Exploring Alignment in Shared Cross-lingual Spaces
May 23, 2024



Despite their remarkable ability to capture linguistic nuances across diverse languages, questions persist regarding the degree of alignment between languages in multilingual embeddings. Drawing inspiration from research on high-dimensional representations in neural language models, we employ clustering to uncover latent concepts within multilingual models. Our analysis focuses on quantifying the \textit{alignment} and \textit{overlap} of these concepts across various languages within the latent space. To this end, we introduce two metrics \CA{} and \CO{} aimed at quantifying these aspects, enabling a deeper exploration of multilingual embeddings. Our study encompasses three multilingual models (\texttt{mT5}, \texttt{mBERT}, and \texttt{XLM-R}) and three downstream tasks (Machine Translation, Named Entity Recognition, and Sentiment Analysis). Key findings from our analysis include: i) deeper layers in the network demonstrate increased cross-lingual \textit{alignment} due to the presence of language-agnostic concepts, ii) fine-tuning of the models enhances \textit{alignment} within the latent space, and iii) such task-specific calibration helps in explaining the emergence of zero-shot capabilities in the models.\footnote{The code is available at \url{https://github.com/baselmousi/multilingual-latent-concepts}}
Latent Concept-based Explanation of NLP Models
Apr 18, 2024


Interpreting and understanding the predictions made by deep learning models poses a formidable challenge due to their inherently opaque nature. Many previous efforts aimed at explaining these predictions rely on input features, specifically, the words within NLP models. However, such explanations are often less informative due to the discrete nature of these words and their lack of contextual verbosity. To address this limitation, we introduce the Latent Concept Attribution method (LACOAT), which generates explanations for predictions based on latent concepts. Our founding intuition is that a word can exhibit multiple facets, contingent upon the context in which it is used. Therefore, given a word in context, the latent space derived from our training process reflects a specific facet of that word. LACOAT functions by mapping the representations of salient input words into the training latent space, allowing it to provide predictions with context-based explanations within this latent space.
Scaled-up Discovery of Latent Concepts in Deep NLP Models
Aug 20, 2023
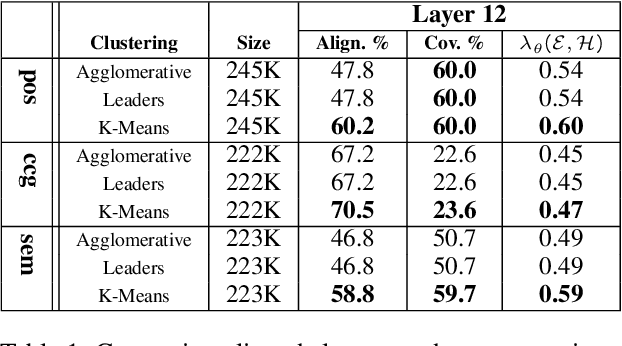

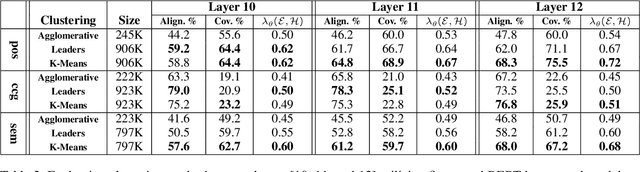
Pre-trained language models (pLMs) learn intricate patterns and contextual dependencies via unsupervised learning on vast text data, driving breakthroughs across NLP tasks. Despite these achievements, these models remain black boxes, necessitating research into understanding their decision-making processes. Recent studies explore representation analysis by clustering latent spaces within pre-trained models. However, these approaches are limited in terms of scalability and the scope of interpretation because of high computation costs of clustering algorithms. This study focuses on comparing clustering algorithms for the purpose of scaling encoded concept discovery of representations from pLMs. Specifically, we compare three algorithms in their capacity to unveil the encoded concepts through their alignment to human-defined ontologies: Agglomerative Hierarchical Clustering, Leaders Algorithm, and K-Means Clustering. Our results show that K-Means has the potential to scale to very large datasets, allowing rich latent concept discovery, both on the word and phrase level.
LLMeBench: A Flexible Framework for Accelerating LLMs Benchmarking
Aug 09, 2023


The recent development and success of Large Language Models (LLMs) necessitate an evaluation of their performance across diverse NLP tasks in different languages. Although several frameworks have been developed and made publicly available, their customization capabilities for specific tasks and datasets are often complex for different users. In this study, we introduce the LLMeBench framework. Initially developed to evaluate Arabic NLP tasks using OpenAI's GPT and BLOOM models; it can be seamlessly customized for any NLP task and model, regardless of language. The framework also features zero- and few-shot learning settings. A new custom dataset can be added in less than 10 minutes, and users can use their own model API keys to evaluate the task at hand. The developed framework has been already tested on 31 unique NLP tasks using 53 publicly available datasets within 90 experimental setups, involving approximately 296K data points. We plan to open-source the framework for the community (https://github.com/qcri/LLMeBench/). A video demonstrating the framework is available online (https://youtu.be/FkQn4UjYA0s).