 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter to Ask in English: Evaluation of Large Language Models on English, Low-resource and Cross-Lingual Settings
Oct 17, 2024Large Language Models (LLMs) are trained on massive amounts of data, enabling their application across diverse domains and tasks. Despite their remarkable performance, most LLMs are developed and evaluated primarily in English. Recently, a few multi-lingual LLMs have emerged, but their performance in low-resource languages, especially the most spoken languages in South Asia, is less explored. To address this gap, in this study, we evaluate LLMs such as GPT-4, Llama 2, and Gemini to analyze their effectiveness in English compared to other low-resource languages from South Asia (e.g., Bangla, Hindi, and Urdu). Specifically, we utilized zero-shot prompting and five different prompt settings to extensively investigate the effectiveness of the LLMs in cross-lingual translated prompts. The findings of the study suggest that GPT-4 outperformed Llama 2 and Gemini in all five prompt settings and across all languages. Moreover, all three LLMs performed better for English language prompts than other low-resource language prompts. This study extensively investigates LLMs in low-resource language contexts to highlight the improvements required in LLMs and language-specific resources to develop more generally purposed NLP applications.
AraDiCE: Benchmarks for Dialectal and Cultural Capabilities in LLMs
Sep 17, 2024Arabic, with its rich diversity of dialects, remains significantly underrepresented in Large Language Models, particularly in dialectal variations. We address this gap by introducing seven synthetic datasets in dialects alongside Modern Standard Arabic (MSA), created using Machine Translation (MT) combined with human post-editing. We present AraDiCE, a benchmark for Arabic Dialect and Cultural Evaluation. We evaluate LLMs on dialect comprehension and generation, focusing specifically on low-resource Arabic dialects. Additionally, we introduce the first-ever fine-grained benchmark designed to evaluate cultural awareness across the Gulf, Egypt, and Levant regions, providing a novel dimension to LLM evaluation. Our findings demonstrate that while Arabic-specific models like Jais and AceGPT outperform multilingual models on dialectal tasks, significant challenges persist in dialect identification, generation, and translation. This work contributes ~45K post-edited samples, a cultural benchmark, and highlights the importance of tailored training to improve LLM performance in capturing the nuances of diverse Arabic dialects and cultural contexts. We will release the dialectal translation models and benchmarks curated in this study.
Do Large Language Models Speak All Languages Equally? A Comparative Study in Low-Resource Settings
Aug 05, 2024



Large language models (LLMs) have garnered significant interest in natural language processing (NLP), particularly their remarkable performance in various downstream tasks in resource-rich languages. Recent studies have highlighted the limitations of LLMs in low-resource languages, primarily focusing on binary classification tasks and giving minimal attention to South Asian languages. These limitations are primarily attributed to constraints such as dataset scarcity, computational costs, and research gaps specific to low-resource languages. To address this gap, we present datasets for sentiment and hate speech tasks by translating from English to Bangla, Hindi, and Urdu, facilitating research in low-resource language processing. Further, we comprehensively examine zero-shot learning using multiple LLMs in English and widely spoken South Asian languages. Our findings indicate that GPT-4 consistently outperforms Llama 2 and Gemini, with English consistently demonstrating superior performance across diverse tasks compared to low-resource languages. Furthermore, our analysis reveals that natural language inference (NLI) exhibits the highest performance among the evaluated tasks, with GPT-4 demonstrating superior capabilities.
NativQA: Multilingual Culturally-Aligned Natural Query for LLMs
Jul 13, 2024Natural Question Answering (QA) datasets play a crucial role in developing and evaluating the capabilities of large language models (LLMs), ensuring their effective usage in real-world applications. Despite the numerous QA datasets that have been developed, there is a notable lack of region-specific datasets generated by native users in their own languages. This gap hinders the effective benchmarking of LLMs for regional and cultural specificities. In this study, we propose a scalable framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages, for LLM evaluation and tuning. Moreover, to demonstrate the efficacy of the proposed framework, we designed a multilingual natural QA dataset, MultiNativQA, consisting of ~72K QA pairs in seven languages, ranging from high to extremely low resource, based on queries from native speakers covering 18 topics. We benchmark the MultiNativQA dataset with open- and closed-source LLMs. We made both the framework NativQA and MultiNativQA dataset publicly available for the community. (https://nativqa.gitlab.io)
ArAIEval Shared Task: Propagandistic Techniques Detection in Unimodal and Multimodal Arabic Content
Jul 05, 2024
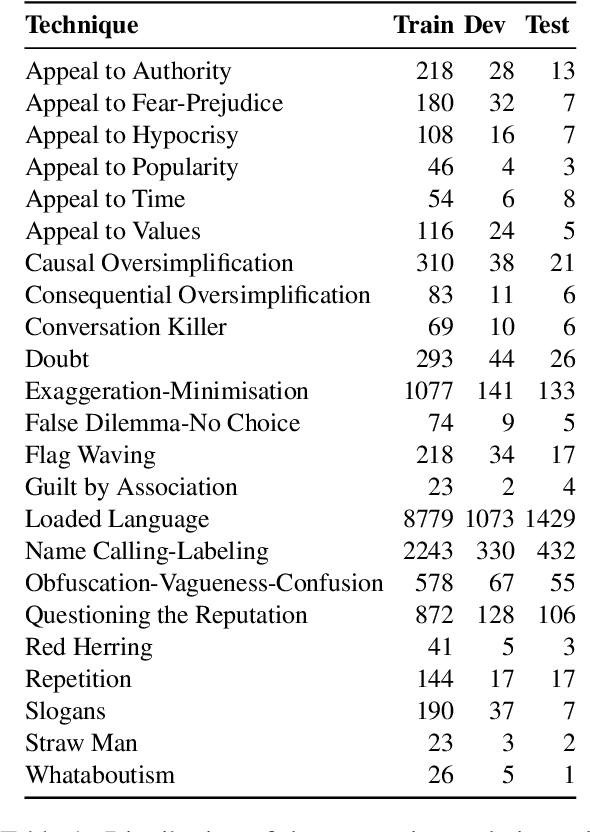


We present an overview of the second edition of the ArAIEval shared task, organized as part of the ArabicNLP 2024 conference co-located with ACL 2024. In this edition, ArAIEval offers two tasks: (i) detection of propagandistic textual spans with persuasion techniques identification in tweets and news articles, and (ii) distinguishing between propagandistic and non-propagandistic memes. A total of 14 teams participated in the final evaluation phase, with 6 and 9 teams participating in Tasks 1 and 2, respectively. Finally, 11 teams submitted system description papers. Across both tasks, we observed that fine-tuning transformer models such as AraBERT was at the core of the majority of the participating systems. We provide a description of the task setup, including a description of the dataset construction and the evaluation setup. We further provide a brief overview of the participating systems. All datasets and evaluation scripts are released to the research community (https://araieval.gitlab.io/). We hope this will enable further research on these important tasks in Arabic.
BLP 2023 Task 2: Sentiment Analysis
Oct 24, 2023
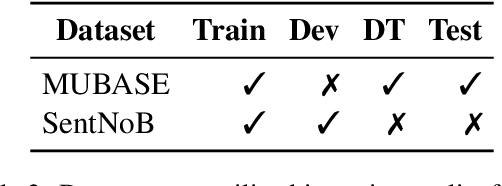
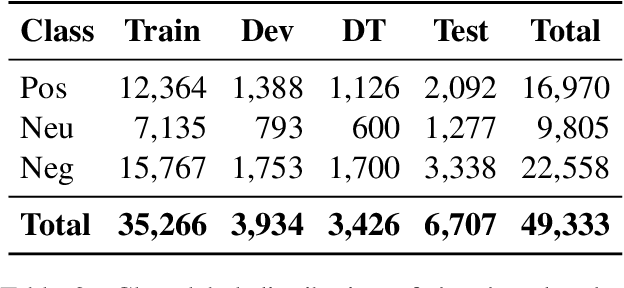
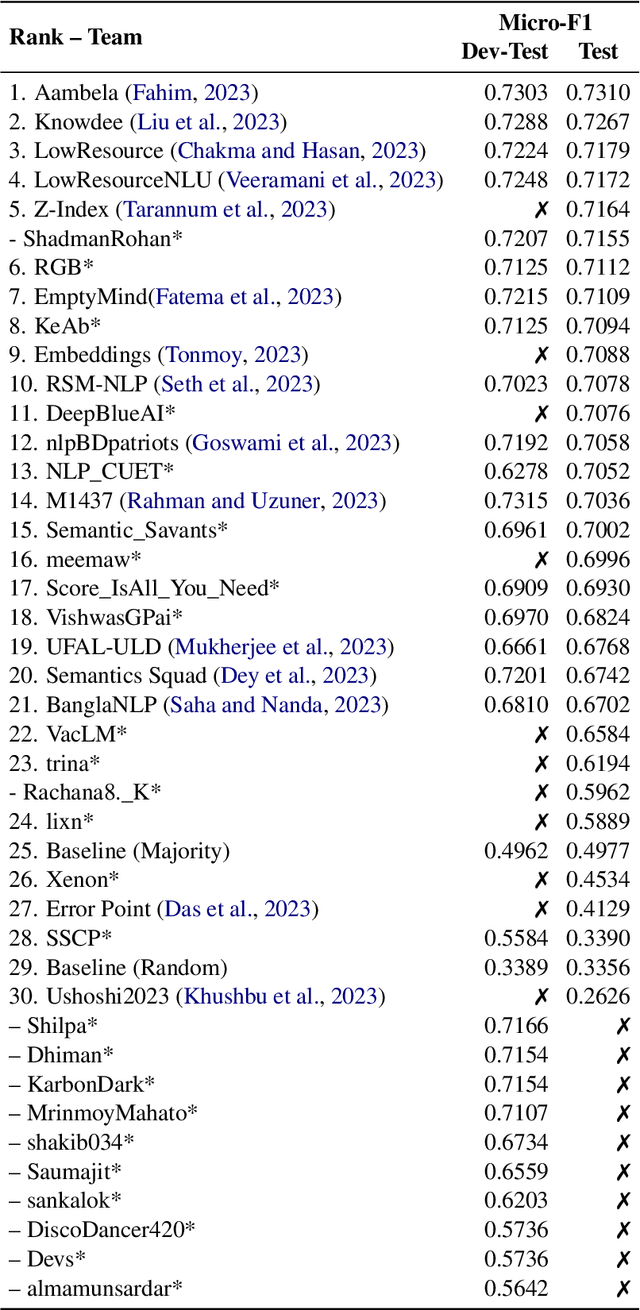
We present an overview of the BLP Sentiment Shared Task, organized as part of the inaugural BLP 2023 workshop, co-located with EMNLP 2023. The task is defined as the detection of sentiment in a given piece of social media text. This task attracted interest from 71 participants, among whom 29 and 30 teams submitted systems during the development and evaluation phases, respectively. In total, participants submitted 597 runs. However, a total of 15 teams submitted system description papers. The range of approaches in the submitted systems spans from classical machine learning models, fine-tuning pre-trained models, to leveraging Large Language Model (LLMs) in zero- and few-shot settings. In this paper, we provide a detailed account of the task setup, including dataset development and evaluation setup. Additionally, we provide a brief overview of the systems submitted by the participants. All datasets and evaluation scripts from the shared task have been made publicly available for the research community, to foster further research in this domain
Zero- and Few-Shot Prompting with LLMs: A Comparative Study with Fine-tuned Models for Bangla Sentiment Analysis
Aug 21, 2023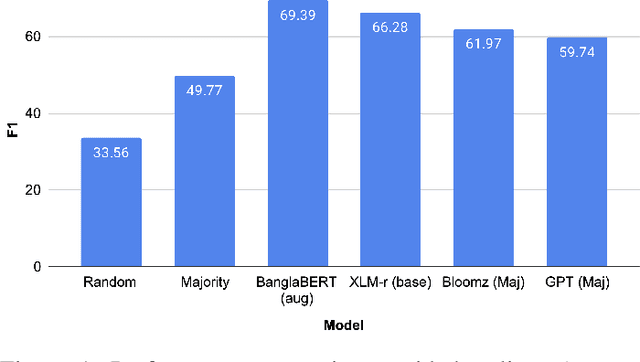
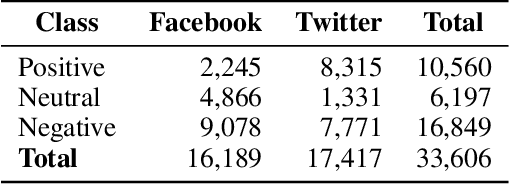
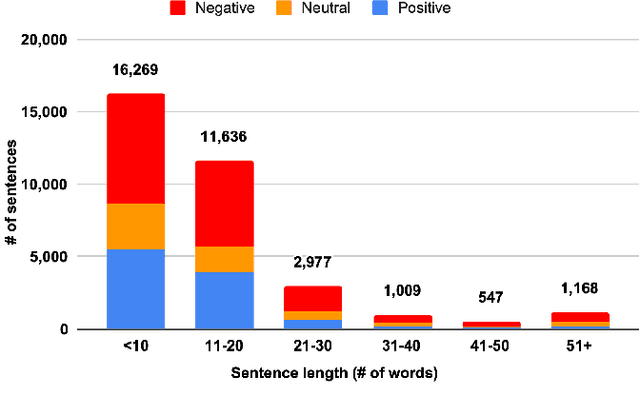
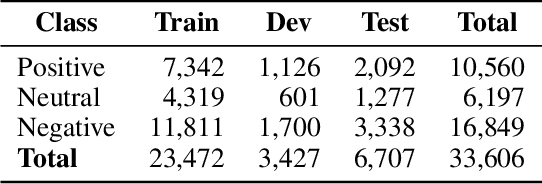
The rapid expansion of the digital world has propelled sentiment analysis into a critical tool across diverse sectors such as marketing, politics, customer service, and healthcare. While there have been significant advancements in sentiment analysis for widely spoken languages, low-resource languages, such as Bangla, remain largely under-researched due to resource constraints. Furthermore, the recent unprecedented performance of Large Language Models (LLMs) in various applications highlights the need to evaluate them in the context of low-resource languages. In this study, we present a sizeable manually annotated dataset encompassing 33,605 Bangla news tweets and Facebook comments. We also investigate zero- and few-shot in-context learning with several language models, including Flan-T5, GPT-4, and Bloomz, offering a comparative analysis against fine-tuned models. Our findings suggest that monolingual transformer-based models consistently outperform other models, even in zero and few-shot scenarios. To foster continued exploration, we intend to make this dataset and our research tools publicly available to the broader research community. In the spirit of further research, we plan to make this dataset and our experimental resources publicly accessible to the wider research community.
Z-Index at CheckThat! Lab 2022: Check-Worthiness Identification on Tweet Text
Jul 15, 2022
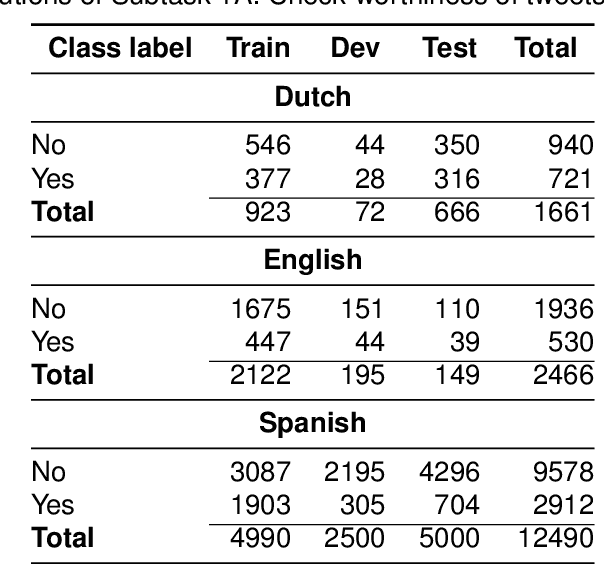
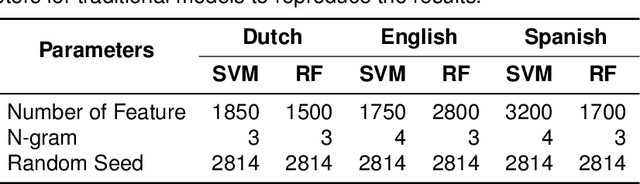

The wide use of social media and digital technologies facilitates sharing various news and information about events and activities. Despite sharing positive information misleading and false information is also spreading on social media. There have been efforts in identifying such misleading information both manually by human experts and automatic tools. Manual effort does not scale well due to the high volume of information, containing factual claims, are appearing online. Therefore, automatically identifying check-worthy claims can be very useful for human experts. In this study, we describe our participation in Subtask-1A: Check-worthiness of tweets (English, Dutch and Spanish) of CheckThat! lab at CLEF 2022. We performed standard preprocessing steps and applied different models to identify whether a given text is worthy of fact checking or not. We use the oversampling technique to balance the dataset and applied SVM and Random Forest (RF) with TF-IDF representations. We also used BERT multilingual (BERT-m) and XLM-RoBERTa-base pre-trained models for the experiments. We used BERT-m for the official submissions and our systems ranked as 3rd, 5th, and 12th in Spanish, Dutch, and English, respectively. In further experiments, our evaluation shows that transformer models (BERT-m and XLM-RoBERTa-base) outperform the SVM and RF in Dutch and English languages where a different scenario is observed for Spanish.
Simulating Using Deep Learning The World Trade Forecasting of Export-Import Exchange Rate Convergence Factor During COVID-19
Jan 23, 2022By trade we usually mean the exchange of goods between states and countries. International trade acts as a barometer of the economic prosperity index and every country is overly dependent on resources, so international trade is essential. Trade is significant to the global health crisis, saving lives and livelihoods. By collecting the dataset called "Effects of COVID19 on trade" from the state website NZ Tatauranga Aotearoa, we have developed a sustainable prediction process on the effects of COVID-19 in world trade using a deep learning model. In the research, we have given a 180-day trade forecast where the ups and downs of daily imports and exports have been accurately predicted in the Covid-19 period. In order to fulfill this prediction, we have taken data from 1st January 2015 to 30th May 2021 for all countries, all commodities, and all transport systems and have recovered what the world trade situation will be in the next 180 days during the Covid-19 period. The deep learning method has received equal attention from both investors and researchers in the field of in-depth observation. This study predicts global trade using the Long-Short Term Memory. Time series analysis can be useful to see how a given asset, security, or economy changes over time. Time series analysis plays an important role in past analysis to get different predictions of the future and it can be observed that some factors affect a particular variable from period to period. Through the time series it is possible to observe how various economic changes or trade effects change over time. By reviewing these changes, one can be aware of the steps to be taken in the future and a country can be more careful in terms of imports and exports accordingly. From our time series analysis, it can be said that the LSTM model has given a very gracious thought of the future world import and export situation in terms of trade.
MEDIC: A Multi-Task Learning Dataset for Disaster Image Classification
Aug 29, 2021
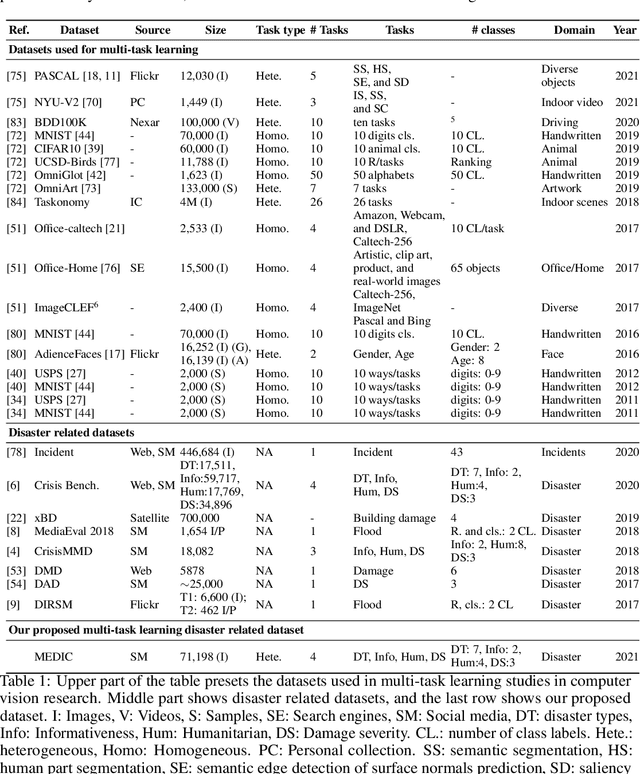
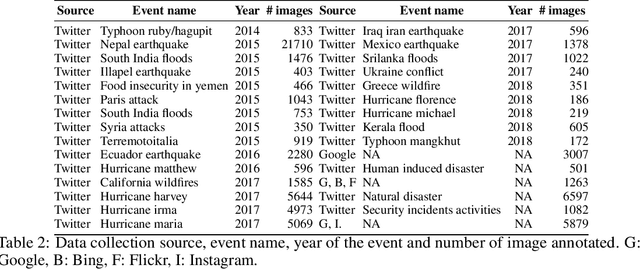

Recent research in disaster informatics demonstrates a practical and important use case of artificial intelligence to save human lives and sufferings during post-natural disasters based on social media contents (text and images). While notable progress has been made using texts, research on exploiting the images remains relatively under-explored. To advance the image-based approach, we propose MEDIC (available at: https://crisisnlp.qcri.org/medic/index.html), which is the largest social media image classification dataset for humanitarian response consisting of 71,198 images to address four different tasks in a multi-task learning setup. This is the first dataset of its kind: social media image, disaster response, and multi-task learning research. An important property of this dataset is its high potential to contribute research on multi-task learning, which recently receives much interest from the machine learning community and has shown remarkable results in terms of memory, inference speed, performance, and generalization capability. Therefore, the proposed dataset is an important resource for advancing image-based disaster management and multi-task machine learning research.