 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNativQA Framework: Enabling LLMs with Native, Local, and Everyday Knowledge
Apr 08, 2025The rapid advancement of large language models (LLMs) has raised concerns about cultural bias, fairness, and their applicability in diverse linguistic and underrepresented regional contexts. To enhance and benchmark the capabilities of LLMs, there is a need to develop large-scale resources focused on multilingual, local, and cultural contexts. In this study, we propose a framework, NativQA, that can seamlessly construct large-scale, culturally and regionally aligned QA datasets in native languages. The framework utilizes user-defined seed queries and leverages search engines to collect location-specific, everyday information. It has been evaluated across 39 locations in 24 countries and in 7 languages, ranging from extremely low-resource to high-resource languages, which resulted over 300K Question Answer (QA) pairs. The developed resources can be used for LLM benchmarking and further fine-tuning. The framework has been made publicly available for the community (https://gitlab.com/nativqa/nativqa-framework).
LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content
Oct 20, 2024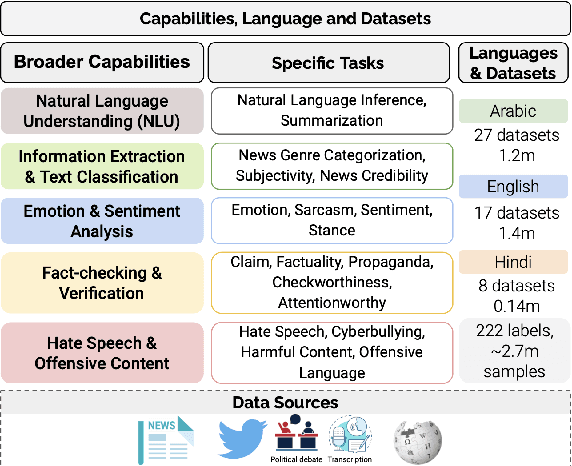
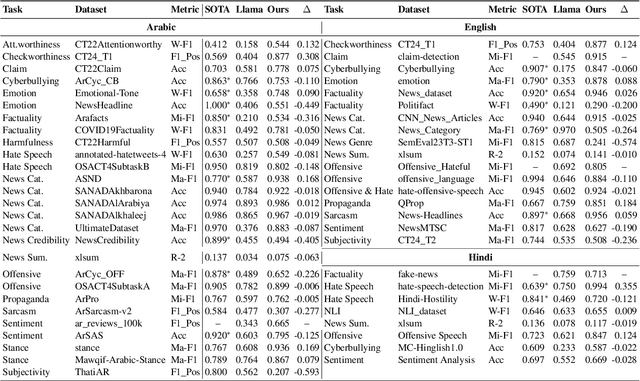
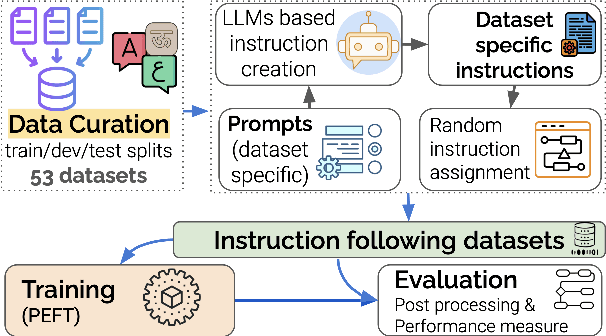
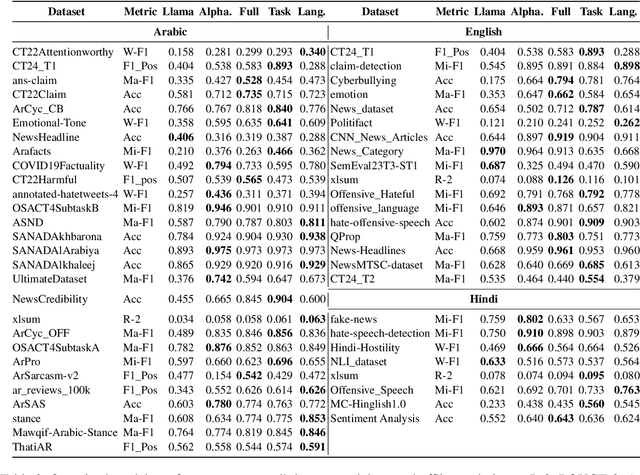
Large Language Models (LLMs) have demonstrated remarkable success as general-purpose task solvers across various fields, including NLP, healthcare, finance, and law. However, their capabilities remain limited when addressing domain-specific problems, particularly in downstream NLP tasks. Research has shown that models fine-tuned on instruction-based downstream NLP datasets outperform those that are not fine-tuned. While most efforts in this area have primarily focused on resource-rich languages like English and broad domains, little attention has been given to multilingual settings and specific domains. To address this gap, this study focuses on developing a specialized LLM, LlamaLens, for analyzing news and social media content in a multilingual context. To the best of our knowledge, this is the first attempt to tackle both domain specificity and multilinguality, with a particular focus on news and social media. Our experimental setup includes 19 tasks, represented by 52 datasets covering Arabic, English, and Hindi. We demonstrate that LlamaLens outperforms the current state-of-the-art (SOTA) on 16 testing sets, and achieves comparable performance on 10 sets. We make the models and resources publicly available for the research community.(https://huggingface.co/QCRI)
NativQA: Multilingual Culturally-Aligned Natural Query for LLMs
Jul 13, 2024Natural Question Answering (QA) datasets play a crucial role in developing and evaluating the capabilities of large language models (LLMs), ensuring their effective usage in real-world applications. Despite the numerous QA datasets that have been developed, there is a notable lack of region-specific datasets generated by native users in their own languages. This gap hinders the effective benchmarking of LLMs for regional and cultural specificities. In this study, we propose a scalable framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages, for LLM evaluation and tuning. Moreover, to demonstrate the efficacy of the proposed framework, we designed a multilingual natural QA dataset, MultiNativQA, consisting of ~72K QA pairs in seven languages, ranging from high to extremely low resource, based on queries from native speakers covering 18 topics. We benchmark the MultiNativQA dataset with open- and closed-source LLMs. We made both the framework NativQA and MultiNativQA dataset publicly available for the community. (https://nativqa.gitlab.io)