 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Reinforcement Learning with Chain-of-Thought Supervision for Explainable Detection of Hateful and Propagandistic Memes
Jun 13, 2026Hateful and propagandistic memes exploit the interplay between images and text to convey harmful intent that neither modality reveals alone. Although thinking-based multimodal large language models (MLLMs) have advanced vision-language understanding, their application to meme content moderation remains underexplored. We propose a reinforcement learning-based post-training method that improves classification performance and reference-based explanation quality in thinking-based MLLMs via task-specific rewards and Group Relative Policy Optimization (GRPO). Concretely, we (i) conduct a systematic empirical study of off-the-shelf MLLMs for hateful and propagandistic meme understanding across English and Arabic benchmarks, (ii) extend existing meme datasets with weakly supervised chain-of-thought (CoT) rationales via distillation and multi-LLM fine-grained propaganda annotations, (iii) introduce a GRPO-based objective with thinking-length regularization that jointly optimizes classification accuracy and explanation quality, and (iv) investigate self-supervised GRPO on unlabeled memes using consensus-based pseudo-labels. Experiments on the Hateful Memes and ArMeme benchmarks show that our approach improves over previously reported results on FHM accuracy (up to +2.1%, from 79.9% to 82.0%) and on ArMeme macro-F1 (up to +7.6 points, from 0.536 to 0.612 with explanations; +6.1 compared to the original ArMeme benchmark), while also generating natural-language explanations. On ArMeme, sequence-classification baselines remain stronger in terms of raw accuracy, whereas our approach provides more balanced per-class performance along with explanations. We publicly release our code, data extensions, and evaluation resources.
Can Thinking Models Think to Detect Hateful Memes?
Mar 01, 2026Hateful memes often require compositional multimodal reasoning: the image and text may appear benign in isolation, yet their interaction conveys harmful intent. Although thinking-based multimodal large language models (MLLMs) have recently advanced vision-language understanding, their capabilities remain underexplored for hateful meme analysis. We propose a reinforcement learning based post-training framework that improves reasoning in thinking-based MLLMs through task-specific rewards and a novel Group Relative Policy Optimization (GRPO) objective. Specifically, we (i) conduct a systematic empirical study of off-the-shelf MLLMs for hateful meme understanding, (ii) extend an existing hateful meme dataset by generating weakly or pseudo-supervised chain-of-thought rationales via distillation, and (iii) introduce a GRPO-based objective that jointly optimizes meme classification and explanation quality to encourage fine-grained, step-by-step reasoning. Experiments on the Hateful Memes benchmark show that our approach achieves state-of-the-art performance, improving accuracy and F1 by approximately 1 percent and explanation quality by approximately 3 percent. We will publicly release our code, dataset extensions, and evaluation resources to support reproducibility.
Measuring Political Stance and Consistency in Large Language Models
Jan 15, 2026With the incredible advancements in Large Language Models (LLMs), many people have started using them to satisfy their information needs. However, utilizing LLMs might be problematic for political issues where disagreement is common and model outputs may reflect training-data biases or deliberate alignment choices. To better characterize such behavior, we assess the stances of nine LLMs on 24 politically sensitive issues using five prompting techniques. We find that models often adopt opposing stances on several issues; some positions are malleable under prompting, while others remain stable. Among the models examined, Grok-3-mini is the most persistent, whereas Mistral-7B is the least. For issues involving countries with different languages, models tend to support the side whose language is used in the prompt. Notably, no prompting technique alters model stances on the Qatar blockade or the oppression of Palestinians. We hope these findings raise user awareness when seeking political guidance from LLMs and encourage developers to address these concerns.
NativQA Framework: Enabling LLMs with Native, Local, and Everyday Knowledge
Apr 08, 2025The rapid advancement of large language models (LLMs) has raised concerns about cultural bias, fairness, and their applicability in diverse linguistic and underrepresented regional contexts. To enhance and benchmark the capabilities of LLMs, there is a need to develop large-scale resources focused on multilingual, local, and cultural contexts. In this study, we propose a framework, NativQA, that can seamlessly construct large-scale, culturally and regionally aligned QA datasets in native languages. The framework utilizes user-defined seed queries and leverages search engines to collect location-specific, everyday information. It has been evaluated across 39 locations in 24 countries and in 7 languages, ranging from extremely low-resource to high-resource languages, which resulted over 300K Question Answer (QA) pairs. The developed resources can be used for LLM benchmarking and further fine-tuning. The framework has been made publicly available for the community (https://gitlab.com/nativqa/nativqa-framework).
GenTREC: The First Test Collection Generated by Large Language Models for Evaluating Information Retrieval Systems
Jan 05, 2025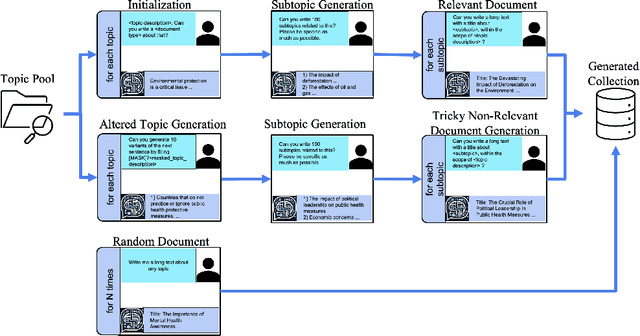

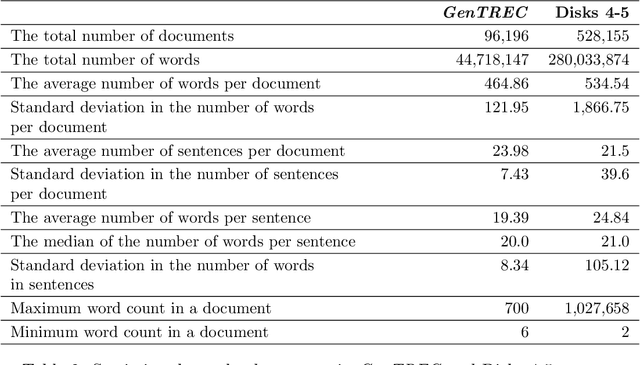
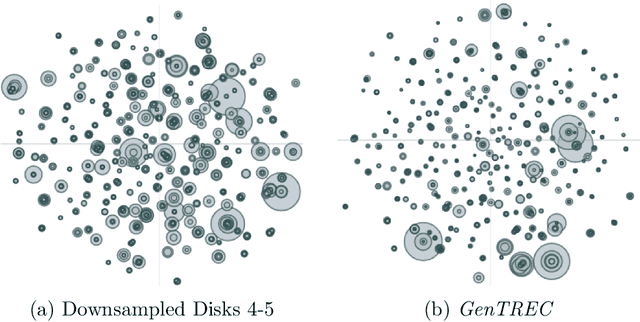
Building test collections for Information Retrieval evaluation has traditionally been a resource-intensive and time-consuming task, primarily due to the dependence on manual relevance judgments. While various cost-effective strategies have been explored, the development of such collections remains a significant challenge. In this paper, we present GenTREC , the first test collection constructed entirely from documents generated by a Large Language Model (LLM), eliminating the need for manual relevance judgments. Our approach is based on the assumption that documents generated by an LLM are inherently relevant to the prompts used for their generation. Based on this heuristic, we utilized existing TREC search topics to generate documents. We consider a document relevant only to the prompt that generated it, while other document-topic pairs are treated as non-relevant. To introduce realistic retrieval challenges, we also generated non-relevant documents, ensuring that IR systems are tested against a diverse and robust set of materials. The resulting GenTREC collection comprises 96,196 documents, 300 topics, and 18,964 relevance "judgments". We conducted extensive experiments to evaluate GenTREC in terms of document quality, relevance judgment accuracy, and evaluation reliability. Notably, our findings indicate that the ranking of IR systems using GenTREC is compatible with the evaluations conducted using traditional TREC test collections, particularly for P@100, MAP, and RPrec metrics. Overall, our results show that our proposed approach offers a promising, low-cost alternative for IR evaluation, significantly reducing the burden of building and maintaining future IR evaluation resources.
GenAI Content Detection Task 2: AI vs. Human -- Academic Essay Authenticity Challenge
Dec 24, 2024



This paper presents a comprehensive overview of the first edition of the Academic Essay Authenticity Challenge, organized as part of the GenAI Content Detection shared tasks collocated with COLING 2025. This challenge focuses on detecting machine-generated vs. human-authored essays for academic purposes. The task is defined as follows: "Given an essay, identify whether it is generated by a machine or authored by a human.'' The challenge involves two languages: English and Arabic. During the evaluation phase, 25 teams submitted systems for English and 21 teams for Arabic, reflecting substantial interest in the task. Finally, seven teams submitted system description papers. The majority of submissions utilized fine-tuned transformer-based models, with one team employing Large Language Models (LLMs) such as Llama 2 and Llama 3. This paper outlines the task formulation, details the dataset construction process, and explains the evaluation framework. Additionally, we present a summary of the approaches adopted by participating teams. Nearly all submitted systems outperformed the n-gram-based baseline, with the top-performing systems achieving F1 scores exceeding 0.98 for both languages, indicating significant progress in the detection of machine-generated text.
AIGCodeSet: A New Annotated Dataset for AI Generated Code Detection
Dec 21, 2024



With the rapid advancement of LLM models, they have become widely useful in various fields. While these AI systems can be used for code generation, significantly simplifying and accelerating the tasks of developers, their use for students to do assignments has raised ethical questions in the field of education. In this context, determining the author of a particular code becomes important. In this study, we introduce AIGCodeSet, a dataset for AI-generated code detection tasks, specifically for the Python programming language. We obtain the problem descriptions and human-written codes from the CodeNet dataset. Using the problem descriptions, we generate AI-written codes with CodeLlama 34B, Codestral 22B, and Gemini 1.5 Flash models in three approaches: i) generating code from the problem description alone, ii) generating code using the description along with human-written source code containing runtime errors, and iii) generating code using the problem description and human-written code that resulted in wrong answers. Lastly, we conducted a post-processing step to eliminate LLM output irrelevant to code snippets. Overall, AIGCodeSet consists of 2,828 AI-generated and 4,755 human-written code snippets. We share our code with the research community to support studies on this important topic and provide performance results for baseline AI-generated code detection methods.
Detecting Turkish Synonyms Used in Different Time Periods
Nov 24, 2024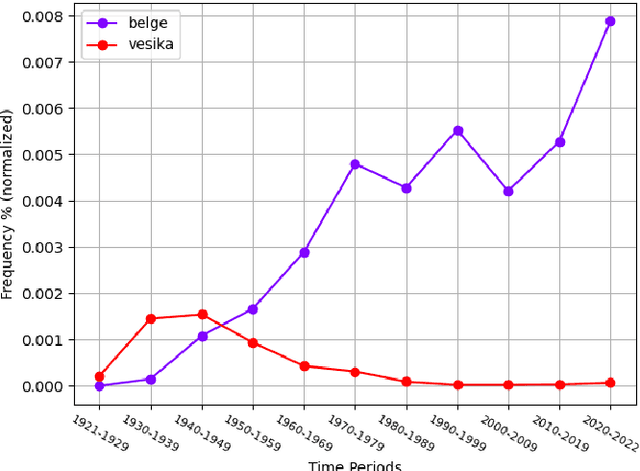
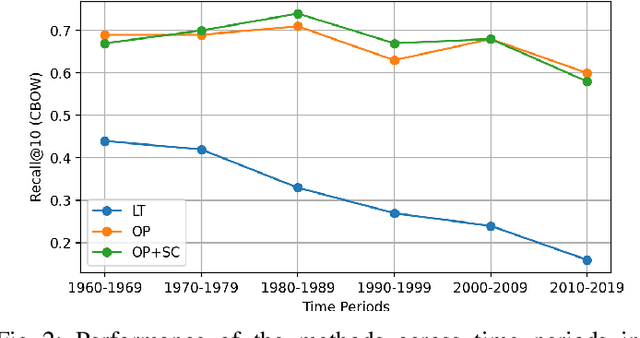
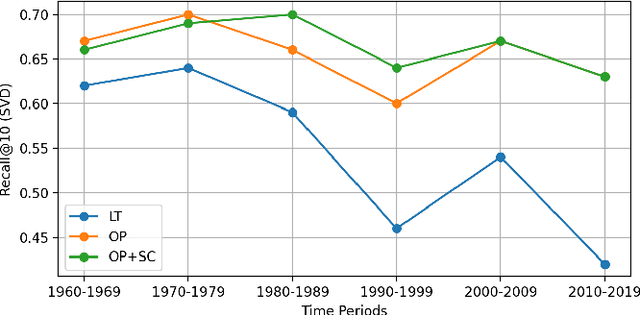
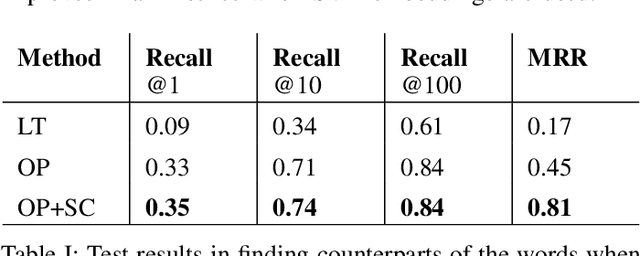
Dynamic structure of languages poses significant challenges in applying natural language processing models on historical texts, causing decreased performance in various downstream tasks. Turkish is a prominent example of rapid linguistic transformation due to the language reform in the 20th century. In this paper, we propose two methods for detecting synonyms used in different time periods, focusing on Turkish. In our first method, we use Orthogonal Procrustes method to align the embedding spaces created using documents written in the corresponding time periods. In our second method, we extend the first one by incorporating Spearman's correlation between frequencies of words throughout the years. In our experiments, we show that our proposed methods outperform the baseline method. Furthermore, we observe that the efficacy of our methods remains consistent when the target time period shifts from the 1960s to the 1980s. However, their performance slightly decreases for subsequent time periods.
NativQA: Multilingual Culturally-Aligned Natural Query for LLMs
Jul 13, 2024Natural Question Answering (QA) datasets play a crucial role in developing and evaluating the capabilities of large language models (LLMs), ensuring their effective usage in real-world applications. Despite the numerous QA datasets that have been developed, there is a notable lack of region-specific datasets generated by native users in their own languages. This gap hinders the effective benchmarking of LLMs for regional and cultural specificities. In this study, we propose a scalable framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages, for LLM evaluation and tuning. Moreover, to demonstrate the efficacy of the proposed framework, we designed a multilingual natural QA dataset, MultiNativQA, consisting of ~72K QA pairs in seven languages, ranging from high to extremely low resource, based on queries from native speakers covering 18 topics. We benchmark the MultiNativQA dataset with open- and closed-source LLMs. We made both the framework NativQA and MultiNativQA dataset publicly available for the community. (https://nativqa.gitlab.io)
Turkronicles: Diachronic Resources for the Fast Evolving Turkish Language
May 16, 2024



Over the past century, the Turkish language has undergone substantial changes, primarily driven by governmental interventions. In this work, our goal is to investigate the evolution of the Turkish language since the establishment of T\"urkiye in 1923. Thus, we first introduce Turkronicles which is a diachronic corpus for Turkish derived from the Official Gazette of T\"urkiye. Turkronicles contains 45,375 documents, detailing governmental actions, making it a pivotal resource for analyzing the linguistic evolution influenced by the state policies. In addition, we expand an existing diachronic Turkish corpus which consists of the records of the Grand National Assembly of T\"urkiye by covering additional years. Next, combining these two diachronic corpora, we seek answers for two main research questions: How have the Turkish vocabulary and the writing conventions changed since the 1920s? Our analysis reveals that the vocabularies of two different time periods diverge more as the time between them increases, and newly coined Turkish words take the place of their old counterparts. We also observe changes in writing conventions. In particular, the use of circumflex noticeably decreases and words ending with the letters "-b" and "-d" are successively replaced with "-p" and "-t" letters, respectively. Overall, this study quantitatively highlights the dramatic changes in Turkish from various aspects of the language in a diachronic perspective.