 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenTREC: The First Test Collection Generated by Large Language Models for Evaluating Information Retrieval Systems
Jan 05, 2025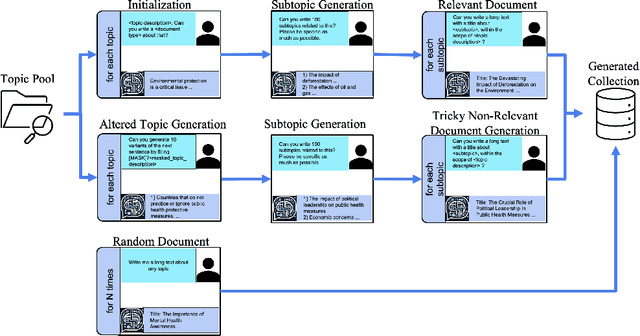

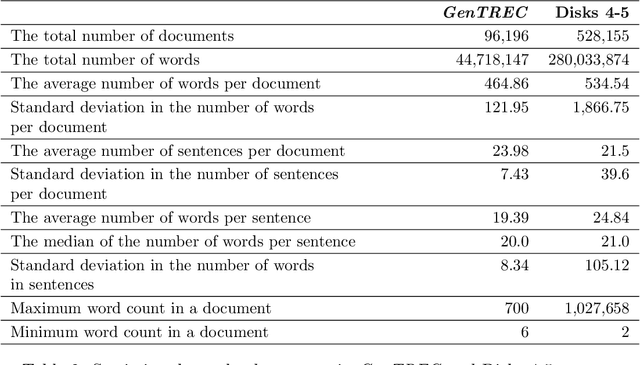
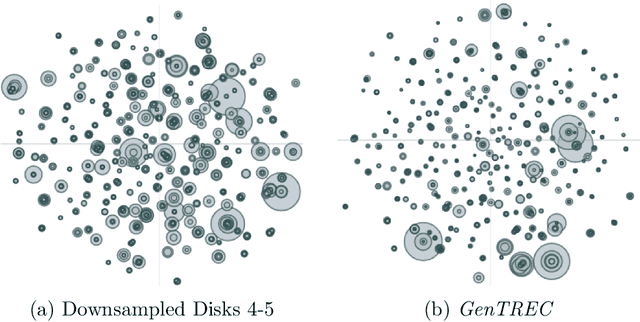
Building test collections for Information Retrieval evaluation has traditionally been a resource-intensive and time-consuming task, primarily due to the dependence on manual relevance judgments. While various cost-effective strategies have been explored, the development of such collections remains a significant challenge. In this paper, we present GenTREC , the first test collection constructed entirely from documents generated by a Large Language Model (LLM), eliminating the need for manual relevance judgments. Our approach is based on the assumption that documents generated by an LLM are inherently relevant to the prompts used for their generation. Based on this heuristic, we utilized existing TREC search topics to generate documents. We consider a document relevant only to the prompt that generated it, while other document-topic pairs are treated as non-relevant. To introduce realistic retrieval challenges, we also generated non-relevant documents, ensuring that IR systems are tested against a diverse and robust set of materials. The resulting GenTREC collection comprises 96,196 documents, 300 topics, and 18,964 relevance "judgments". We conducted extensive experiments to evaluate GenTREC in terms of document quality, relevance judgment accuracy, and evaluation reliability. Notably, our findings indicate that the ranking of IR systems using GenTREC is compatible with the evaluations conducted using traditional TREC test collections, particularly for P@100, MAP, and RPrec metrics. Overall, our results show that our proposed approach offers a promising, low-cost alternative for IR evaluation, significantly reducing the burden of building and maintaining future IR evaluation resources.
New Metrics to Encourage Innovation and Diversity in Information Retrieval Approaches
Jan 24, 2023



In evaluation campaigns, participants often explore variations of popular, state-of-the-art baselines as a low-risk strategy to achieve competitive results. While effective, this can lead to local "hill climbing" rather than more radical and innovative departure from standard methods. Moreover, if many participants build on similar baselines, the overall diversity of approaches considered may be limited. In this work, we propose a new class of IR evaluation metrics intended to promote greater diversity of approaches in evaluation campaigns. Whereas traditional IR metrics focus on user experience, our two "innovation" metrics instead reward exploration of more divergent, higher-risk strategies finding relevant documents missed by other systems. Experiments on four TREC collections show that our metrics do change system rankings by rewarding systems that find such rare, relevant documents. This result is further supported by a controlled, synthetic data experiment, and a qualitative analysis. In addition, we show that our metrics achieve higher evaluation stability and discriminative power than the standard metrics we modify. To support reproducibility, we share our source code.