 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenTREC: The First Test Collection Generated by Large Language Models for Evaluating Information Retrieval Systems
Jan 05, 2025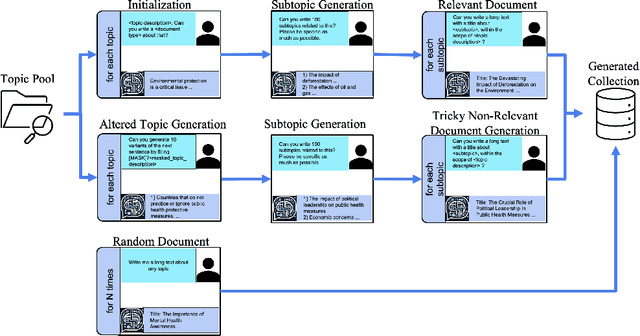

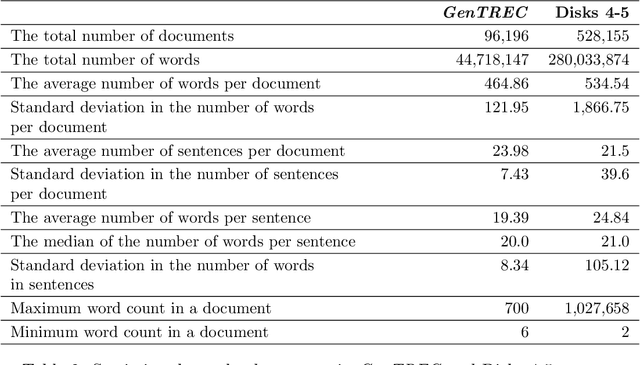
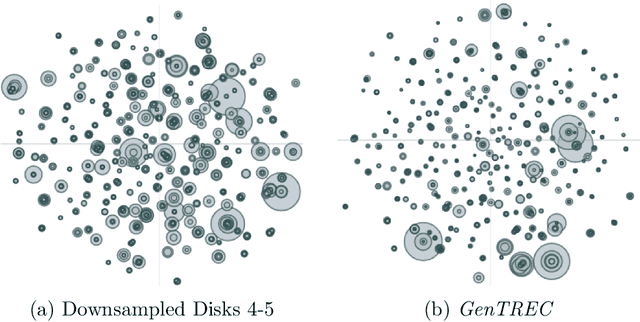
Building test collections for Information Retrieval evaluation has traditionally been a resource-intensive and time-consuming task, primarily due to the dependence on manual relevance judgments. While various cost-effective strategies have been explored, the development of such collections remains a significant challenge. In this paper, we present GenTREC , the first test collection constructed entirely from documents generated by a Large Language Model (LLM), eliminating the need for manual relevance judgments. Our approach is based on the assumption that documents generated by an LLM are inherently relevant to the prompts used for their generation. Based on this heuristic, we utilized existing TREC search topics to generate documents. We consider a document relevant only to the prompt that generated it, while other document-topic pairs are treated as non-relevant. To introduce realistic retrieval challenges, we also generated non-relevant documents, ensuring that IR systems are tested against a diverse and robust set of materials. The resulting GenTREC collection comprises 96,196 documents, 300 topics, and 18,964 relevance "judgments". We conducted extensive experiments to evaluate GenTREC in terms of document quality, relevance judgment accuracy, and evaluation reliability. Notably, our findings indicate that the ranking of IR systems using GenTREC is compatible with the evaluations conducted using traditional TREC test collections, particularly for P@100, MAP, and RPrec metrics. Overall, our results show that our proposed approach offers a promising, low-cost alternative for IR evaluation, significantly reducing the burden of building and maintaining future IR evaluation resources.
Catch Me If You Can: Deceiving Stance Detection and Geotagging Models to Protect Privacy of Individuals on Twitter
Jul 23, 2022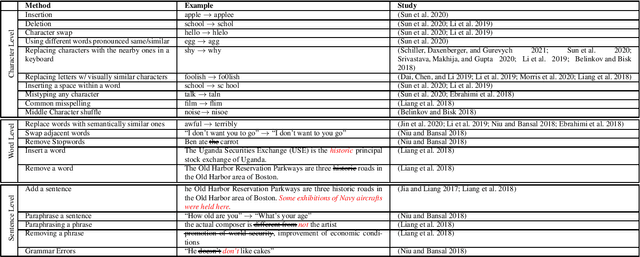
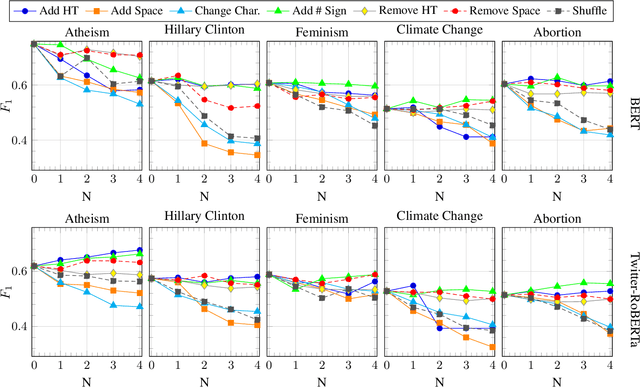
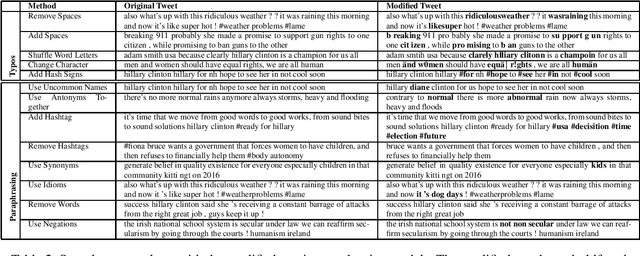
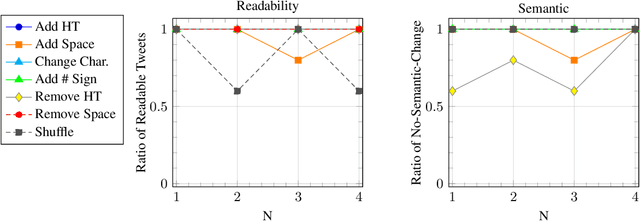
The recent advances in natural language processing have yielded many exciting developments in text analysis and language understanding models; however, these models can also be used to track people, bringing severe privacy concerns. In this work, we investigate what individuals can do to avoid being detected by those models while using social media platforms. We ground our investigation in two exposure-risky tasks, stance detection and geotagging. We explore a variety of simple techniques for modifying text, such as inserting typos in salient words, paraphrasing, and adding dummy social media posts. Our experiments show that the performance of BERT-based models fined tuned for stance detection decreases significantly due to typos, but it is not affected by paraphrasing. Moreover, we find that typos have minimal impact on state-of-the-art geotagging models due to their increased reliance on social networks; however, we show that users can deceive those models by interacting with different users, reducing their performance by almost 50%.