 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatch Me If You Can: Deceiving Stance Detection and Geotagging Models to Protect Privacy of Individuals on Twitter
Jul 23, 2022
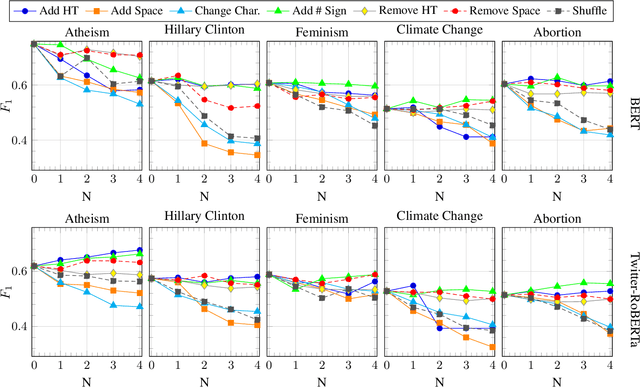
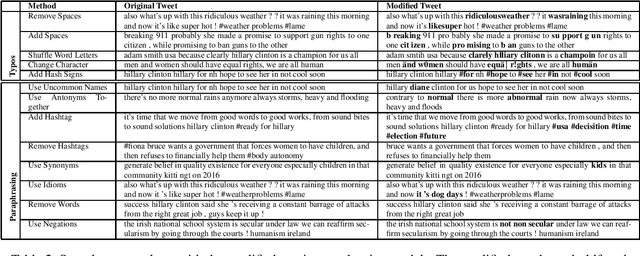
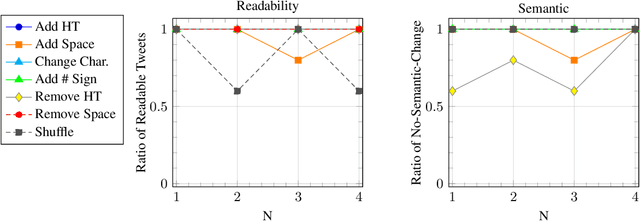
The recent advances in natural language processing have yielded many exciting developments in text analysis and language understanding models; however, these models can also be used to track people, bringing severe privacy concerns. In this work, we investigate what individuals can do to avoid being detected by those models while using social media platforms. We ground our investigation in two exposure-risky tasks, stance detection and geotagging. We explore a variety of simple techniques for modifying text, such as inserting typos in salient words, paraphrasing, and adding dummy social media posts. Our experiments show that the performance of BERT-based models fined tuned for stance detection decreases significantly due to typos, but it is not affected by paraphrasing. Moreover, we find that typos have minimal impact on state-of-the-art geotagging models due to their increased reliance on social networks; however, we show that users can deceive those models by interacting with different users, reducing their performance by almost 50%.