 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQayyem: A Real-time Platform for Scoring Proficiency of Arabic Essays
Mar 01, 2026Over the past years, Automated Essay Scoring (AES) systems have gained increasing attention as scalable and consistent solutions for assessing the proficiency of student writing. Despite recent progress, support for Arabic AES remains limited due to linguistic complexity and scarcity of large publicly-available annotated datasets. In this work, we present Qayyem, a Web-based platform designed to support Arabic AES by providing an integrated workflow for assignment creation, batch essay upload, scoring configuration, and per-trait essay evaluation. Qayyem abstracts the technical complexity of interacting with scoring server APIs, allowing instructors to access advanced scoring services through a user-friendly interface. The platform deploys a number of state-of-the-art Arabic essay scoring models with different effectiveness and efficiency figures.
LAILA: A Large Trait-Based Dataset for Arabic Automated Essay Scoring
Dec 30, 2025Automated Essay Scoring (AES) has gained increasing attention in recent years, yet research on Arabic AES remains limited due to the lack of publicly available datasets. To address this, we introduce LAILA, the largest publicly available Arabic AES dataset to date, comprising 7,859 essays annotated with holistic and trait-specific scores on seven dimensions: relevance, organization, vocabulary, style, development, mechanics, and grammar. We detail the dataset design, collection, and annotations, and provide benchmark results using state-of-the-art Arabic and English models in prompt-specific and cross-prompt settings. LAILA fills a critical need in Arabic AES research, supporting the development of robust scoring systems.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025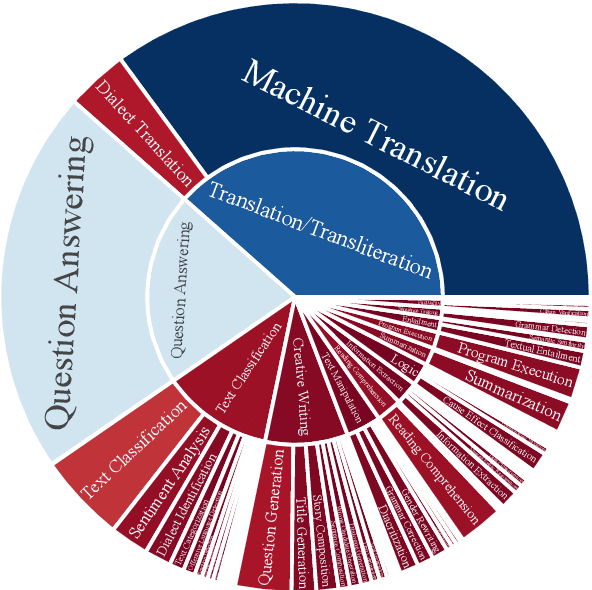



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
TRATES: Trait-Specific Rubric-Assisted Cross-Prompt Essay Scoring
May 20, 2025Research on holistic Automated Essay Scoring (AES) is long-dated; yet, there is a notable lack of attention for assessing essays according to individual traits. In this work, we propose TRATES, a novel trait-specific and rubric-based cross-prompt AES framework that is generic yet specific to the underlying trait. The framework leverages a Large Language Model (LLM) that utilizes the trait grading rubrics to generate trait-specific features (represented by assessment questions), then assesses those features given an essay. The trait-specific features are eventually combined with generic writing-quality and prompt-specific features to train a simple classical regression model that predicts trait scores of essays from an unseen prompt. Experiments show that TRATES achieves a new state-of-the-art performance across all traits on a widely-used dataset, with the generated LLM-based features being the most significant.
ArabicNLU 2024: The First Arabic Natural Language Understanding Shared Task
Jul 30, 2024

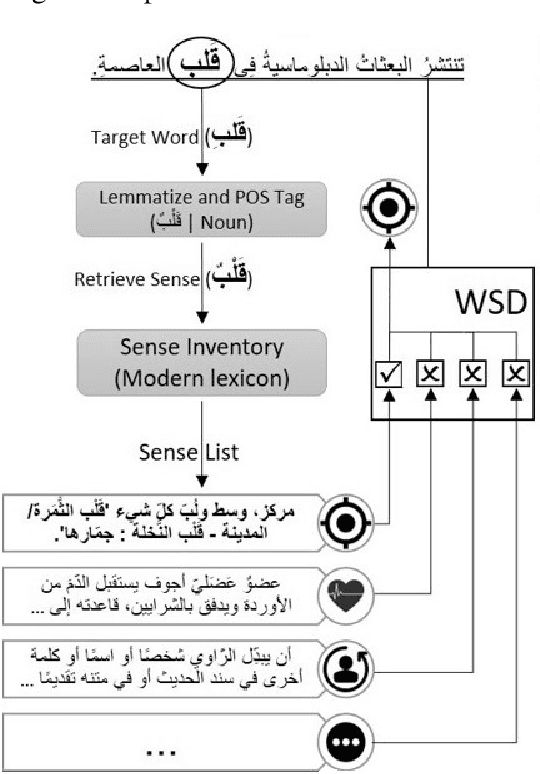
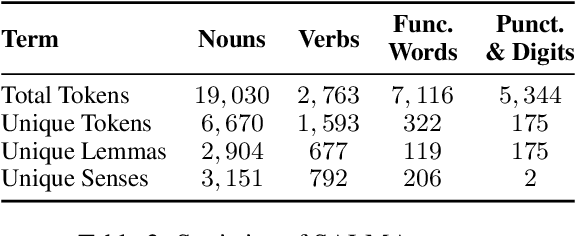
This paper presents an overview of the Arabic Natural Language Understanding (ArabicNLU 2024) shared task, focusing on two subtasks: Word Sense Disambiguation (WSD) and Location Mention Disambiguation (LMD). The task aimed to evaluate the ability of automated systems to resolve word ambiguity and identify locations mentioned in Arabic text. We provided participants with novel datasets, including a sense-annotated corpus for WSD, called SALMA with approximately 34k annotated tokens, and the IDRISI-DA dataset with 3,893 annotations and 763 unique location mentions. These are challenging tasks. Out of the 38 registered teams, only three teams participated in the final evaluation phase, with the highest accuracy being 77.8% for WSD and the highest MRR@1 being 95.0% for LMD. The shared task not only facilitated the evaluation and comparison of different techniques, but also provided valuable insights and resources for the continued advancement of Arabic NLU technologies.
Graded Relevance Scoring of Written Essays with Dense Retrieval
May 08, 2024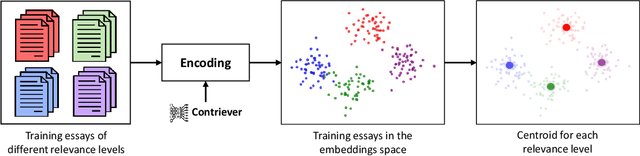
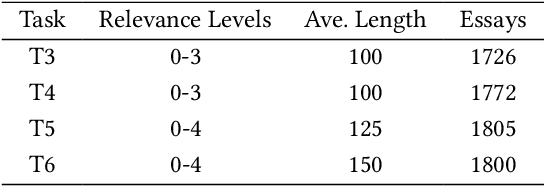
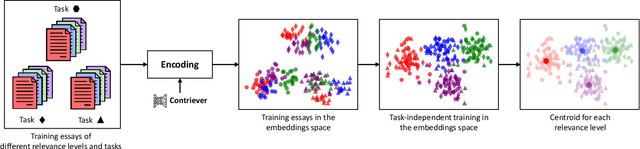
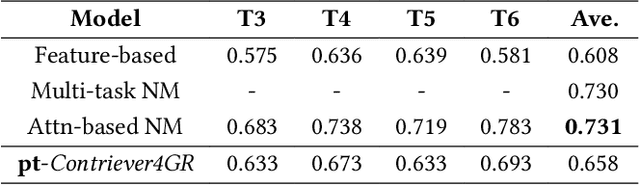
Automated Essay Scoring automates the grading process of essays, providing a great advantage for improving the writing proficiency of students. While holistic essay scoring research is prevalent, a noticeable gap exists in scoring essays for specific quality traits. In this work, we focus on the relevance trait, which measures the ability of the student to stay on-topic throughout the entire essay. We propose a novel approach for graded relevance scoring of written essays that employs dense retrieval encoders. Dense representations of essays at different relevance levels then form clusters in the embeddings space, such that their centroids are potentially separate enough to effectively represent their relevance levels. We hence use the simple 1-Nearest-Neighbor classification over those centroids to determine the relevance level of an unseen essay. As an effective unsupervised dense encoder, we leverage Contriever, which is pre-trained with contrastive learning and demonstrated comparable performance to supervised dense retrieval models. We tested our approach on both task-specific (i.e., training and testing on same task) and cross-task (i.e., testing on unseen task) scenarios using the widely used ASAP++ dataset. Our method establishes a new state-of-the-art performance in the task-specific scenario, while its extension for the cross-task scenario exhibited a performance that is on par with the state-of-the-art model for that scenario. We also analyzed the performance of our approach in a more practical few-shot scenario, showing that it can significantly reduce the labeling cost while sacrificing only 10% of its effectiveness.
Can Large Language Models Automatically Score Proficiency of Written Essays?
Mar 10, 2024



Although several methods were proposed to address the problem of automated essay scoring (AES) in the last 50 years, there is still much to desire in terms of effectiveness. Large Language Models (LLMs) are transformer-based models that demonstrate extraordinary capabilities on various tasks. In this paper, we test the ability of LLMs, given their powerful linguistic knowledge, to analyze and effectively score written essays. We experimented with two popular LLMs, namely ChatGPT and Llama. We aim to check if these models can do this task and, if so, how their performance is positioned among the state-of-the-art (SOTA) models across two levels, holistically and per individual writing trait. We utilized prompt-engineering tactics in designing four different prompts to bring their maximum potential to this task. Our experiments conducted on the ASAP dataset revealed several interesting observations. First, choosing the right prompt depends highly on the model and nature of the task. Second, the two LLMs exhibited comparable average performance in AES, with a slight advantage for ChatGPT. Finally, despite the performance gap between the two LLMs and SOTA models in terms of predictions, they provide feedback to enhance the quality of the essays, which can potentially help both teachers and students.
Detecting Stance of Authorities towards Rumors in Arabic Tweets: A Preliminary Study
Jan 14, 2023


A myriad of studies addressed the problem of rumor verification in Twitter by either utilizing evidence from the propagation networks or external evidence from the Web. However, none of these studies exploited evidence from trusted authorities. In this paper, we define the task of detecting the stance of authorities towards rumors in tweets, i.e., whether a tweet from an authority agrees, disagrees, or is unrelated to the rumor. We believe the task is useful to augment the sources of evidence utilized by existing rumor verification systems. We construct and release the first Authority STance towards Rumors (AuSTR) dataset, where evidence is retrieved from authority timelines in Arabic Twitter. Due to the relatively limited size of our dataset, we study the usefulness of existing datasets for stance detection in our task. We show that existing datasets are somewhat useful for the task; however, they are clearly insufficient, which motivates the need to augment them with annotated data constituting stance of authorities from Twitter.
Cross-lingual Transfer Learning for Check-worthy Claim Identification over Twitter
Nov 09, 2022



Misinformation spread over social media has become an undeniable infodemic. However, not all spreading claims are made equal. If propagated, some claims can be destructive, not only on the individual level, but to organizations and even countries. Detecting claims that should be prioritized for fact-checking is considered the first step to fight against spread of fake news. With training data limited to a handful of languages, developing supervised models to tackle the problem over lower-resource languages is currently infeasible. Therefore, our work aims to investigate whether we can use existing datasets to train models for predicting worthiness of verification of claims in tweets in other languages. We present a systematic comparative study of six approaches for cross-lingual check-worthiness estimation across pairs of five diverse languages with the help of Multilingual BERT (mBERT) model. We run our experiments using a state-of-the-art multilingual Twitter dataset. Our results show that for some language pairs, zero-shot cross-lingual transfer is possible and can perform as good as monolingual models that are trained on the target language. We also show that in some languages, this approach outperforms (or at least is comparable to) state-of-the-art models.
Catch Me If You Can: Deceiving Stance Detection and Geotagging Models to Protect Privacy of Individuals on Twitter
Jul 23, 2022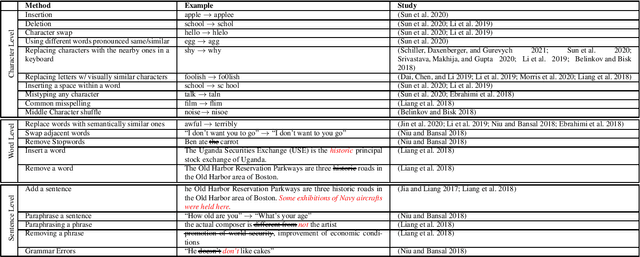
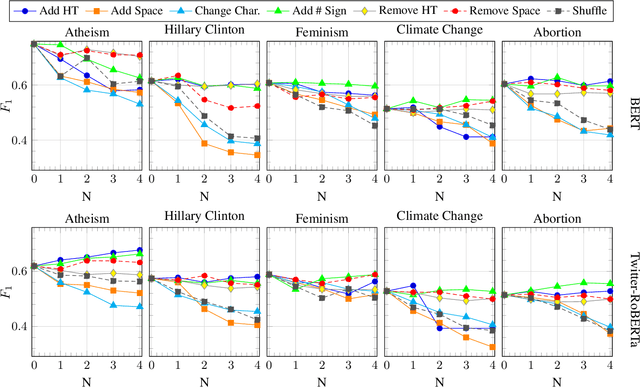
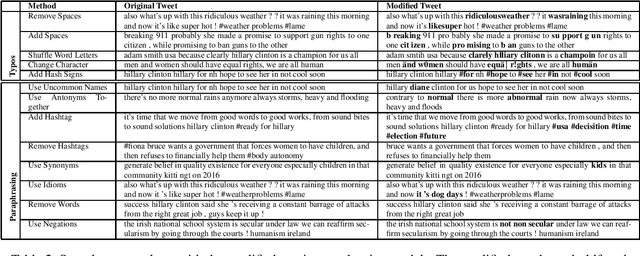
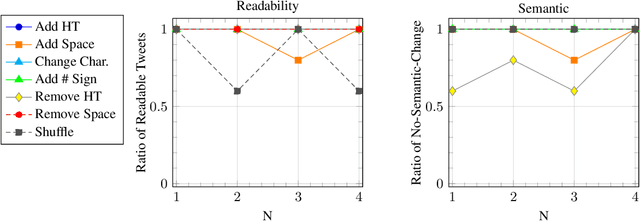
The recent advances in natural language processing have yielded many exciting developments in text analysis and language understanding models; however, these models can also be used to track people, bringing severe privacy concerns. In this work, we investigate what individuals can do to avoid being detected by those models while using social media platforms. We ground our investigation in two exposure-risky tasks, stance detection and geotagging. We explore a variety of simple techniques for modifying text, such as inserting typos in salient words, paraphrasing, and adding dummy social media posts. Our experiments show that the performance of BERT-based models fined tuned for stance detection decreases significantly due to typos, but it is not affected by paraphrasing. Moreover, we find that typos have minimal impact on state-of-the-art geotagging models due to their increased reliance on social networks; however, we show that users can deceive those models by interacting with different users, reducing their performance by almost 50%.