 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Underperform Graph-Based Parsers on Supervised Relation Extraction for Complex Graphs
Apr 09, 2026Relation extraction represents a fundamental component in the process of creating knowledge graphs, among other applications. Large language models (LLMs) have been adopted as a promising tool for relation extraction, both in supervised and in-context learning settings. However, in this work we show that their performance still lags behind much smaller architectures when the linguistic graph underlying a text has great complexity. To demonstrate this, we evaluate four LLMs against a graph-based parser on six relation extraction datasets with sentence graphs of varying sizes and complexities. Our results show that the graph-based parser increasingly outperforms the LLMs, as the number of relations in the input documents increases. This makes the much lighter graph-based parser a superior choice in the presence of complex linguistic graphs.
Dependency Parsing is More Parameter-Efficient with Normalization
May 26, 2025Dependency parsing is the task of inferring natural language structure, often approached by modeling word interactions via attention through biaffine scoring. This mechanism works like self-attention in Transformers, where scores are calculated for every pair of words in a sentence. However, unlike Transformer attention, biaffine scoring does not use normalization prior to taking the softmax of the scores. In this paper, we provide theoretical evidence and empirical results revealing that a lack of normalization necessarily results in overparameterized parser models, where the extra parameters compensate for the sharp softmax outputs produced by high variance inputs to the biaffine scoring function. We argue that biaffine scoring can be made substantially more efficient by performing score normalization. We conduct experiments on six datasets for semantic and syntactic dependency parsing using a one-hop parser. We train N-layer stacked BiLSTMs and evaluate the parser's performance with and without normalizing biaffine scores. Normalizing allows us to beat the state of the art on two datasets, with fewer samples and trainable parameters. Code: https://anonymous.4open.science/r/EfficientSDP-70C1
Hate Speech According to the Law: An Analysis for Effective Detection
Dec 09, 2024



The issue of hate speech extends beyond the confines of the online realm. It is a problem with real-life repercussions, prompting most nations to formulate legal frameworks that classify hate speech as a punishable offence. These legal frameworks differ from one country to another, contributing to the big chaos that online platforms have to face when addressing reported instances of hate speech. With the definitions of hate speech falling short in introducing a robust framework, we turn our gaze onto hate speech laws. We consult the opinion of legal experts on a hate speech dataset and we experiment by employing various approaches such as pretrained models both on hate speech and legal data, as well as exploiting two large language models (Qwen2-7B-Instruct and Meta-Llama-3-70B). Due to the time-consuming nature of data acquisition for prosecutable hate speech, we use pseudo-labeling to improve our pretrained models. This study highlights the importance of amplifying research on prosecutable hate speech and provides insights into effective strategies for combating hate speech within the parameters of legal frameworks. Our findings show that legal knowledge in the form of annotations can be useful when classifying prosecutable hate speech, yet more focus should be paid on the differences between the laws.
Untangling Hate Speech Definitions: A Semantic Componential Analysis Across Cultures and Domains
Nov 11, 2024
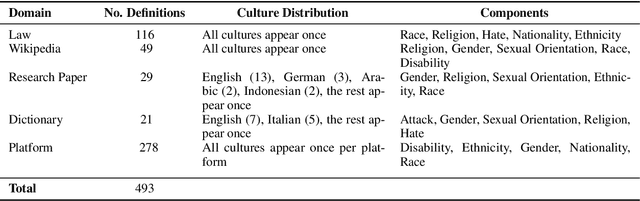

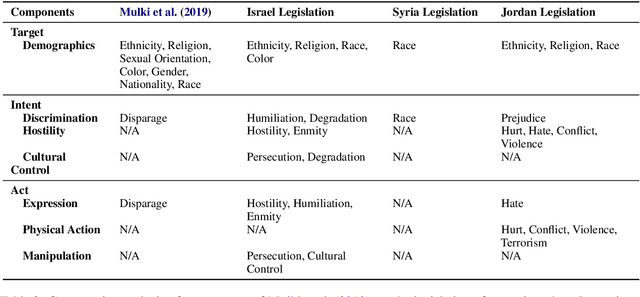
Hate speech relies heavily on cultural influences, leading to varying individual interpretations. For that reason, we propose a Semantic Componential Analysis (SCA) framework for a cross-cultural and cross-domain analysis of hate speech definitions. We create the first dataset of definitions derived from five domains: online dictionaries, research papers, Wikipedia articles, legislation, and online platforms, which are later analyzed into semantic components. Our analysis reveals that the components differ from definition to definition, yet many domains borrow definitions from one another without taking into account the target culture. We conduct zero-shot model experiments using our proposed dataset, employing three popular open-sourced LLMs to understand the impact of different definitions on hate speech detection. Our findings indicate that LLMs are sensitive to definitions: responses for hate speech detection change according to the complexity of definitions used in the prompt.
Language is Scary when Over-Analyzed: Unpacking Implied Misogynistic Reasoning with Argumentation Theory-Driven Prompts
Sep 04, 2024



We propose misogyny detection as an Argumentative Reasoning task and we investigate the capacity of large language models (LLMs) to understand the implicit reasoning used to convey misogyny in both Italian and English. The central aim is to generate the missing reasoning link between a message and the implied meanings encoding the misogyny. Our study uses argumentation theory as a foundation to form a collection of prompts in both zero-shot and few-shot settings. These prompts integrate different techniques, including chain-of-thought reasoning and augmented knowledge. Our findings show that LLMs fall short on reasoning capabilities about misogynistic comments and that they mostly rely on their implicit knowledge derived from internalized common stereotypes about women to generate implied assumptions, rather than on inductive reasoning.
Let Guidelines Guide You: A Prescriptive Guideline-Centered Data Annotation Methodology
Jun 20, 2024


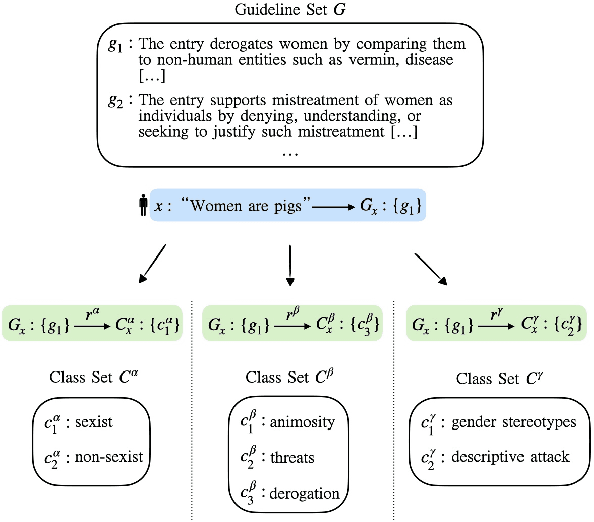
We introduce the Guideline-Centered annotation process, a novel data annotation methodology focused on reporting the annotation guidelines associated with each data sample. We identify three main limitations of the standard prescriptive annotation process and describe how the Guideline-Centered methodology overcomes them by reducing the loss of information in the annotation process and ensuring adherence to guidelines. Additionally, we discuss how the Guideline-Centered enables the reuse of annotated data across multiple tasks at the cost of a single human-annotation process.
QueerBench: Quantifying Discrimination in Language Models Toward Queer Identities
Jun 18, 2024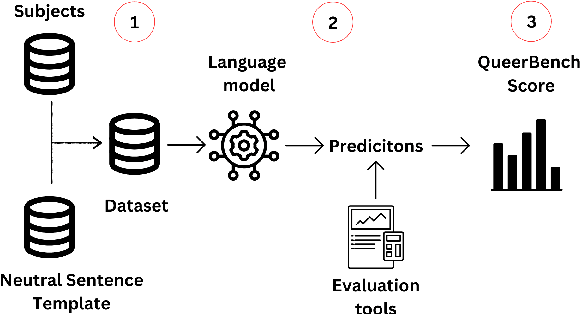

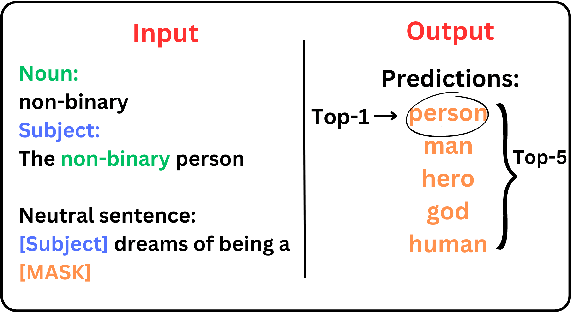

With the increasing role of Natural Language Processing (NLP) in various applications, challenges concerning bias and stereotype perpetuation are accentuated, which often leads to hate speech and harm. Despite existing studies on sexism and misogyny, issues like homophobia and transphobia remain underexplored and often adopt binary perspectives, putting the safety of LGBTQIA+ individuals at high risk in online spaces. In this paper, we assess the potential harm caused by sentence completions generated by English large language models (LLMs) concerning LGBTQIA+ individuals. This is achieved using QueerBench, our new assessment framework, which employs a template-based approach and a Masked Language Modeling (MLM) task. The analysis indicates that large language models tend to exhibit discriminatory behaviour more frequently towards individuals within the LGBTQIA+ community, reaching a difference gap of 7.2% in the QueerBench score of harmfulness.
PejorativITy: Disambiguating Pejorative Epithets to Improve Misogyny Detection in Italian Tweets
Apr 03, 2024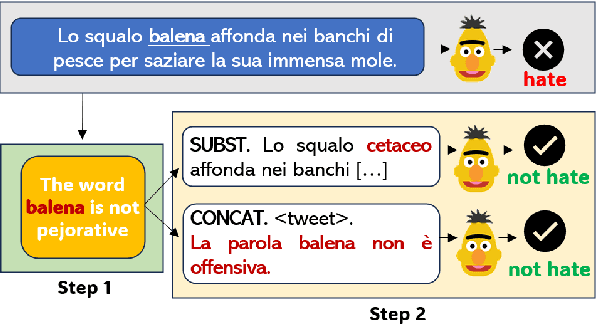
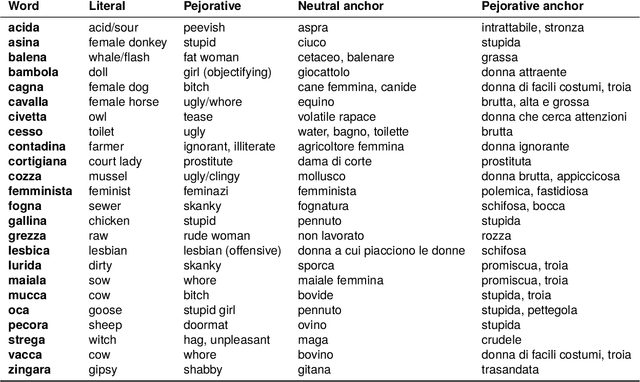
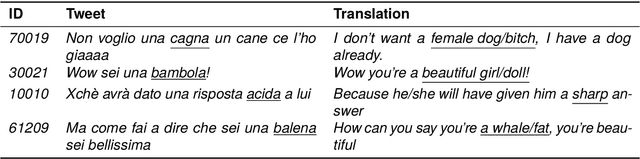
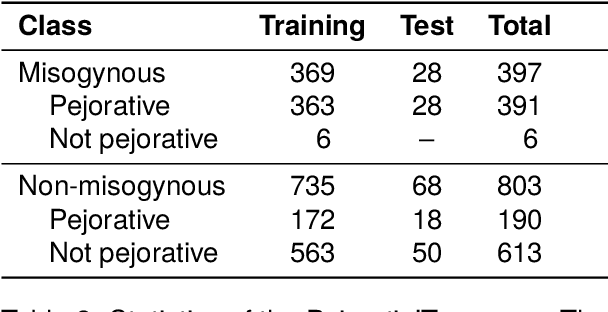
Misogyny is often expressed through figurative language. Some neutral words can assume a negative connotation when functioning as pejorative epithets. Disambiguating the meaning of such terms might help the detection of misogyny. In order to address such task, we present PejorativITy, a novel corpus of 1,200 manually annotated Italian tweets for pejorative language at the word level and misogyny at the sentence level. We evaluate the impact of injecting information about disambiguated words into a model targeting misogyny detection. In particular, we explore two different approaches for injection: concatenation of pejorative information and substitution of ambiguous words with univocal terms. Our experimental results, both on our corpus and on two popular benchmarks on Italian tweets, show that both approaches lead to a major classification improvement, indicating that word sense disambiguation is a promising preliminary step for misogyny detection. Furthermore, we investigate LLMs' understanding of pejorative epithets by means of contextual word embeddings analysis and prompting.
A Corpus for Sentence-level Subjectivity Detection on English News Articles
May 29, 2023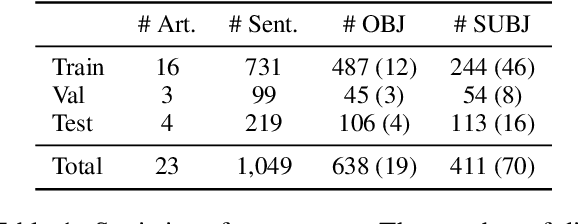

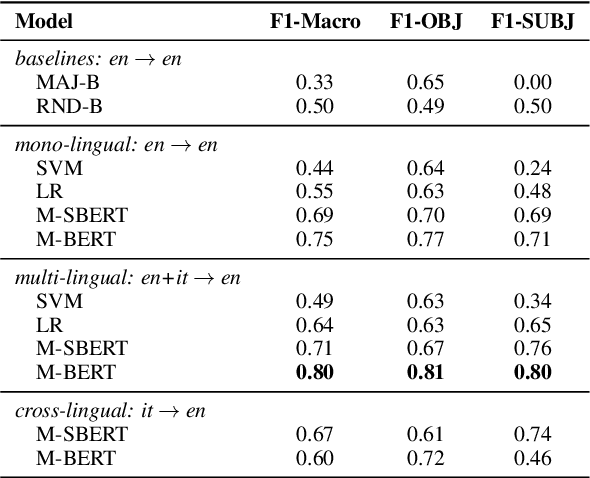
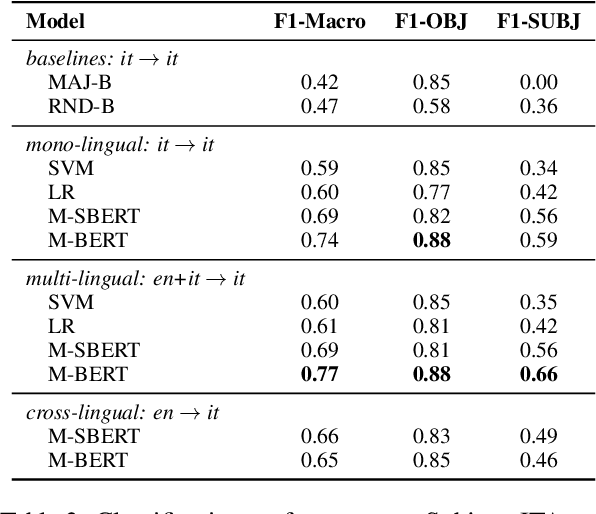
We present a novel corpus for subjectivity detection at the sentence level. We develop new annotation guidelines for the task, which are not limited to language-specific cues, and apply them to produce a new corpus in English. The corpus consists of 411 subjective and 638 objective sentences extracted from ongoing coverage of political affairs from online news outlets. This new resource paves the way for the development of models for subjectivity detection in English and across other languages, without relying on language-specific tools like lexicons or machine translation. We evaluate state-of-the-art multilingual transformer-based models on the task, both in mono- and cross-lingual settings, the latter with a similar existing corpus in Italian language. We observe that enriching our corpus with resources in other languages improves the results on the task.
Overview of the CLEF-2019 CheckThat!: Automatic Identification and Verification of Claims
Sep 25, 2021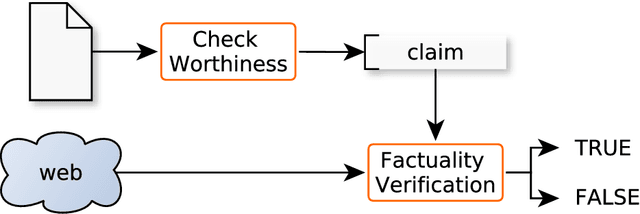
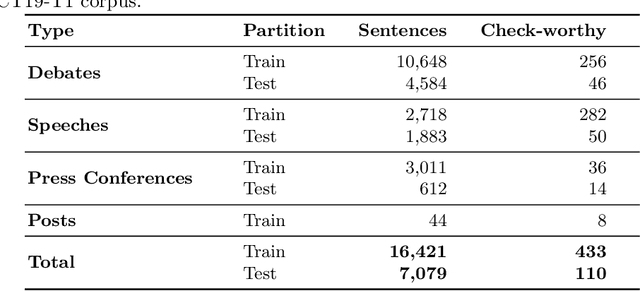


We present an overview of the second edition of the CheckThat! Lab at CLEF 2019. The lab featured two tasks in two different languages: English and Arabic. Task 1 (English) challenged the participating systems to predict which claims in a political debate or speech should be prioritized for fact-checking. Task 2 (Arabic) asked to (A) rank a given set of Web pages with respect to a check-worthy claim based on their usefulness for fact-checking that claim, (B) classify these same Web pages according to their degree of usefulness for fact-checking the target claim, (C) identify useful passages from these pages, and (D) use the useful pages to predict the claim's factuality. CheckThat! provided a full evaluation framework, consisting of data in English (derived from fact-checking sources) and Arabic (gathered and annotated from scratch) and evaluation based on mean average precision (MAP) and normalized discounted cumulative gain (nDCG) for ranking, and F1 for classification. A total of 47 teams registered to participate in this lab, and fourteen of them actually submitted runs (compared to nine last year). The evaluation results show that the most successful approaches to Task 1 used various neural networks and logistic regression. As for Task 2, learning-to-rank was used by the highest scoring runs for subtask A, while different classifiers were used in the other subtasks. We release to the research community all datasets from the lab as well as the evaluation scripts, which should enable further research in the important tasks of check-worthiness estimation and automatic claim verification.
* Check-worthiness Estimation, Fact-Checking, Veracity, Evidence-based Verification, Fake News Detection, Computational Journalism, Disinformation, Misinformation. arXiv admin note: text overlap with arXiv:2012.09263 by other authors