 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermining Energy Efficiency Sweet Spots in Production LLM Inference
Feb 05, 2026Large Language Models (LLMs) inference is central in modern AI applications, making it critical to understand their energy footprint. Existing approaches typically estimate energy consumption through simple linear functions of input and output sequence lengths, yet our observations reveal clear Energy Efficiency regimes: peak efficiency occurs with short-to-moderate inputs and medium-length outputs, while efficiency drops sharply for long inputs or very short outputs, indicating a non-linear dependency. In this work, we propose an analytical model derived from the computational and memory-access complexity of the Transformer architecture, capable of accurately characterizing the efficiency curve as a function of input and output lengths. To assess its accuracy, we evaluate energy consumption using TensorRT-LLM on NVIDIA H100 GPUs across a diverse set of LLMs ranging from 1B to 9B parameters, including OPT, LLaMA, Gemma, Falcon, Qwen2, and Granite, tested over input and output lengths from 64 to 4096 tokens, achieving a mean MAPE of 1.79%. Our results show that aligning sequence lengths with these efficiency "Sweet Spots" can substantially reduce energy usage, supporting informed truncation, summarization, and adaptive generation strategies in production systems.
A Corpus for Sentence-level Subjectivity Detection on English News Articles
May 29, 2023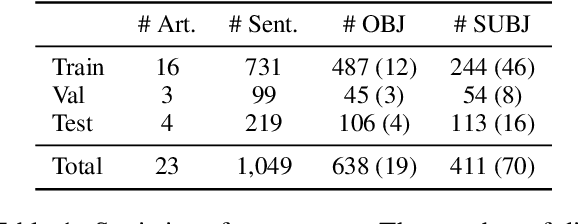

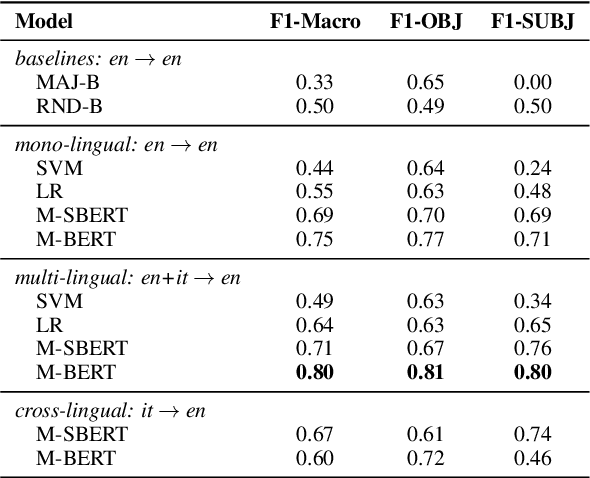
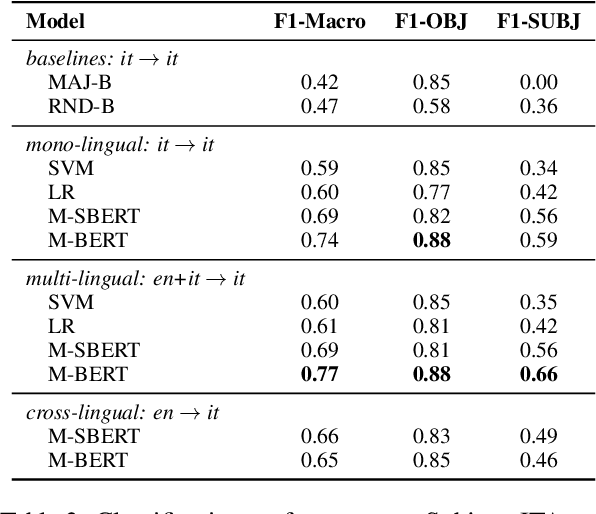
We present a novel corpus for subjectivity detection at the sentence level. We develop new annotation guidelines for the task, which are not limited to language-specific cues, and apply them to produce a new corpus in English. The corpus consists of 411 subjective and 638 objective sentences extracted from ongoing coverage of political affairs from online news outlets. This new resource paves the way for the development of models for subjectivity detection in English and across other languages, without relying on language-specific tools like lexicons or machine translation. We evaluate state-of-the-art multilingual transformer-based models on the task, both in mono- and cross-lingual settings, the latter with a similar existing corpus in Italian language. We observe that enriching our corpus with resources in other languages improves the results on the task.