 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermining Energy Efficiency Sweet Spots in Production LLM Inference
Feb 05, 2026Large Language Models (LLMs) inference is central in modern AI applications, making it critical to understand their energy footprint. Existing approaches typically estimate energy consumption through simple linear functions of input and output sequence lengths, yet our observations reveal clear Energy Efficiency regimes: peak efficiency occurs with short-to-moderate inputs and medium-length outputs, while efficiency drops sharply for long inputs or very short outputs, indicating a non-linear dependency. In this work, we propose an analytical model derived from the computational and memory-access complexity of the Transformer architecture, capable of accurately characterizing the efficiency curve as a function of input and output lengths. To assess its accuracy, we evaluate energy consumption using TensorRT-LLM on NVIDIA H100 GPUs across a diverse set of LLMs ranging from 1B to 9B parameters, including OPT, LLaMA, Gemma, Falcon, Qwen2, and Granite, tested over input and output lengths from 64 to 4096 tokens, achieving a mean MAPE of 1.79%. Our results show that aligning sequence lengths with these efficiency "Sweet Spots" can substantially reduce energy usage, supporting informed truncation, summarization, and adaptive generation strategies in production systems.
Assessing Tenstorrent's RISC-V MatMul Acceleration Capabilities
May 09, 2025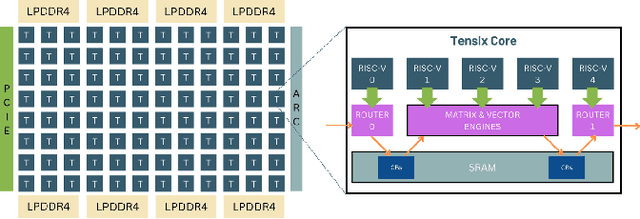

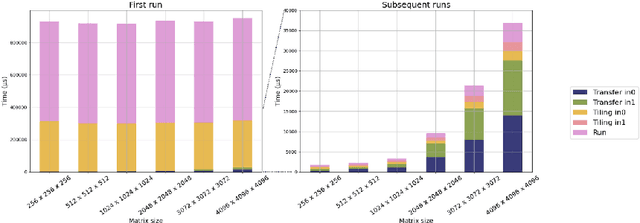
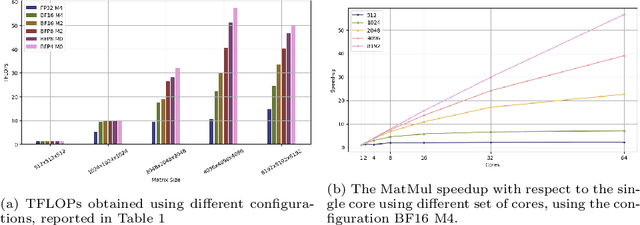
The increasing demand for generative AI as Large Language Models (LLMs) services has driven the need for specialized hardware architectures that optimize computational efficiency and energy consumption. This paper evaluates the performance of the Tenstorrent Grayskull e75 RISC-V accelerator for basic linear algebra kernels at reduced numerical precision, a fundamental operation in LLM computations. We present a detailed characterization of Grayskull's execution model, gridsize, matrix dimensions, data formats, and numerical precision impact computational efficiency. Furthermore, we compare Grayskull's performance against state-of-the-art architectures with tensor acceleration, including Intel Sapphire Rapids processors and two NVIDIA GPUs (V100 and A100). Whilst NVIDIA GPUs dominate raw performance, Grayskull demonstrates a competitive trade-off between power consumption and computational throughput, reaching a peak of 1.55 TFLOPs/Watt with BF16.
Exploring GPU-to-GPU Communication: Insights into Supercomputer Interconnects
Aug 26, 2024



Multi-GPU nodes are increasingly common in the rapidly evolving landscape of exascale supercomputers. On these systems, GPUs on the same node are connected through dedicated networks, with bandwidths up to a few terabits per second. However, gauging performance expectations and maximizing system efficiency is challenging due to different technologies, design options, and software layers. This paper comprehensively characterizes three supercomputers - Alps, Leonardo, and LUMI - each with a unique architecture and design. We focus on performance evaluation of intra-node and inter-node interconnects on up to 4096 GPUs, using a mix of intra-node and inter-node benchmarks. By analyzing its limitations and opportunities, we aim to offer practical guidance to researchers, system architects, and software developers dealing with multi-GPU supercomputing. Our results show that there is untapped bandwidth, and there are still many opportunities for optimization, ranging from network to software optimization.
RUAD: unsupervised anomaly detection in HPC systems
Aug 28, 2022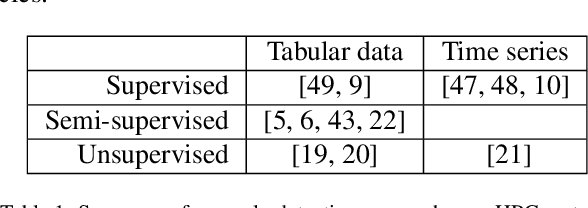
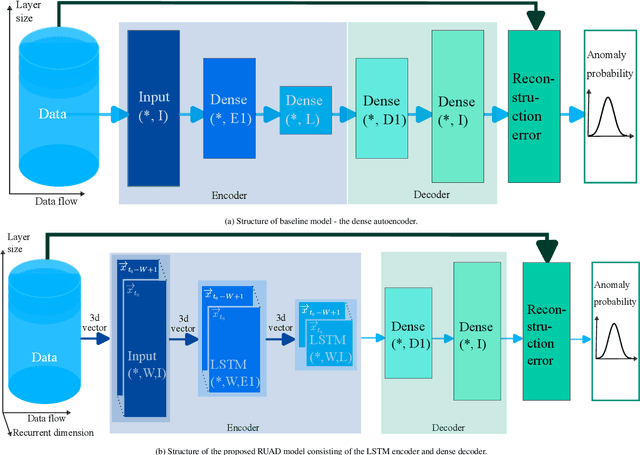


The increasing complexity of modern high-performance computing (HPC) systems necessitates the introduction of automated and data-driven methodologies to support system administrators' effort toward increasing the system's availability. Anomaly detection is an integral part of improving the availability as it eases the system administrator's burden and reduces the time between an anomaly and its resolution. However, current state-of-the-art (SoA) approaches to anomaly detection are supervised and semi-supervised, so they require a human-labelled dataset with anomalies - this is often impractical to collect in production HPC systems. Unsupervised anomaly detection approaches based on clustering, aimed at alleviating the need for accurate anomaly data, have so far shown poor performance. In this work, we overcome these limitations by proposing RUAD, a novel Recurrent Unsupervised Anomaly Detection model. RUAD achieves better results than the current semi-supervised and unsupervised SoA approaches. This is achieved by considering temporal dependencies in the data and including long-short term memory cells in the model architecture. The proposed approach is assessed on a complete ten-month history of a Tier-0 system (Marconi100 from CINECA with 980 nodes). RUAD achieves an area under the curve (AUC) of 0.763 in semi-supervised training and an AUC of 0.767 in unsupervised training, which improves upon the SoA approach that achieves an AUC of 0.747 in semi-supervised training and an AUC of 0.734 in unsupervised training. It also vastly outperforms the current SoA unsupervised anomaly detection approach based on clustering, achieving the AUC of 0.548.