 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring GPU-to-GPU Communication: Insights into Supercomputer Interconnects
Aug 26, 2024



Multi-GPU nodes are increasingly common in the rapidly evolving landscape of exascale supercomputers. On these systems, GPUs on the same node are connected through dedicated networks, with bandwidths up to a few terabits per second. However, gauging performance expectations and maximizing system efficiency is challenging due to different technologies, design options, and software layers. This paper comprehensively characterizes three supercomputers - Alps, Leonardo, and LUMI - each with a unique architecture and design. We focus on performance evaluation of intra-node and inter-node interconnects on up to 4096 GPUs, using a mix of intra-node and inter-node benchmarks. By analyzing its limitations and opportunities, we aim to offer practical guidance to researchers, system architects, and software developers dealing with multi-GPU supercomputing. Our results show that there is untapped bandwidth, and there are still many opportunities for optimization, ranging from network to software optimization.
AutoTaskFormer: Searching Vision Transformers for Multi-task Learning
Apr 20, 2023

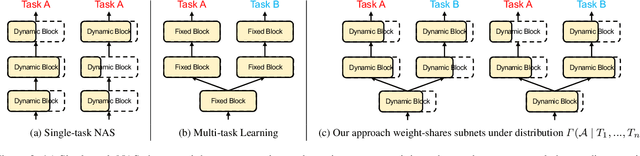
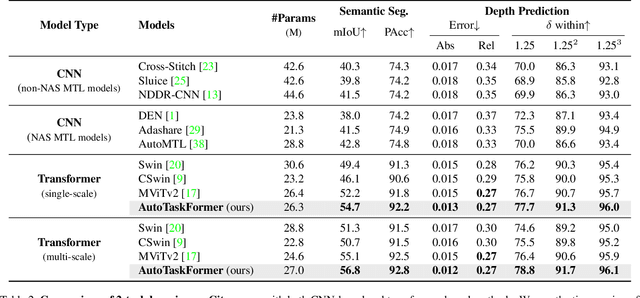
Vision Transformers have shown great performance in single tasks such as classification and segmentation. However, real-world problems are not isolated, which calls for vision transformers that can perform multiple tasks concurrently. Existing multi-task vision transformers are handcrafted and heavily rely on human expertise. In this work, we propose a novel one-shot neural architecture search framework, dubbed AutoTaskFormer (Automated Multi-Task Vision TransFormer), to automate this process. AutoTaskFormer not only identifies the weights to share across multiple tasks automatically, but also provides thousands of well-trained vision transformers with a wide range of parameters (e.g., number of heads and network depth) for deployment under various resource constraints. Experiments on both small-scale (2-task Cityscapes and 3-task NYUv2) and large-scale (16-task Taskonomy) datasets show that AutoTaskFormer outperforms state-of-the-art handcrafted vision transformers in multi-task learning. The entire code and models will be open-sourced.